Pretzel: email encryption and provider-supplied functions are compatible Gupta et al., SIGCOMM’17
While emails today are often encrypted in transit, the vast majority of emails are exposed in plaintext to the mail servers that handle them. Given the sensitive information often contained in email correspondence, why is this?
Publicly, email providers have stated that default end-to-end encryption would conflict with essential functions (spam filtering, etc.), because the latter requires analyzing email text.
It’s the same argument that often gets used to justify MiTM corporate ‘attacks’ on HTTPS traffic (aka ‘middleboxes’). With Pretzel the authors make an important contribution to the debate by demonstrating that the situation is not quite so black-and-white as intermediaries and service providers would like you to believe. It is possible to have both end-to-end encryption and email provider functions such as spam filtering and topic extraction. And it’s possible without extreme overheads that would otherwise make it infeasible in practice. It turns out that there’s a three-way trade-off we can make:
Our objective in this paper is to refute these claims of incompatibility… Ultimately, our goal is just to demonstrate an alternative. We don’t claim that Pretzel is an optimal point in the three-way trade-off among functionality, performance, and privacy; we don’t yet know what such an optimum would be. We simply claim that it is different from the status quo (which combines rich functionality, superb performance, but no encryption by default) and that it is potentially plausible.
Even if the application to email doesn’t especially interest you, there’s a lot to learn from this paper about modern cryptographic building blocks and what is becoming possible.
A high-level overview of Pretzel
Senders encrypt email using an end-to-end encryption scheme (OpenPGP in the prototype), and the intended recipients decrypt messages and obtain the email contents. (Let’s put aside for the moment the usability issues with key management and PGP for end users). The provider and each recipient then engage in a secure two-party computation (2PC):
… the term refers to cryptographic protocols that enable one or both parties to learn the output of an agreed upon function, without revealing the inputs to each other. For example, a provider supplies its spam filter, a user supplies an email, and both parties learn whether the email is spam while protecting the details of the filter and the content of the email.
Pretzel focuses on classification tasks, as applied to spam filtering and topic extraction (used to support provider’s advertising-based business models). So far, the authors have implemented Naive Bayes for spam filtering, multinomial Naive Bayes for topic extraction, logistic regression classifiers, and linear Support Vector Machine classifiers.
Pretzel comprises an end-to-end encryption module, and function modules that implementation computations over email content. The e2e module exists solely at the clients, but the function modules have both client-side and provider-side components.
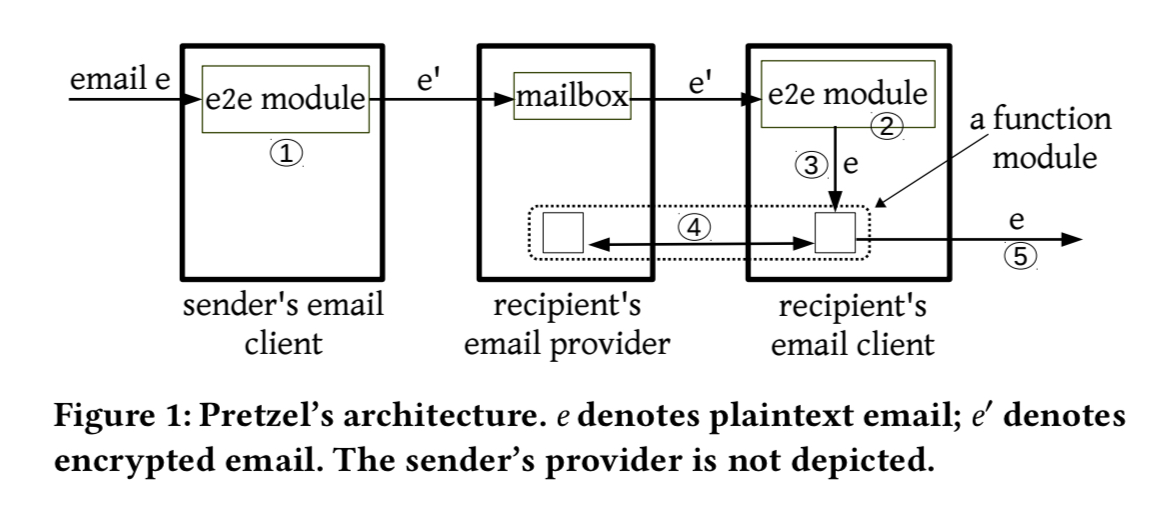
Once a recipient has decrypted an email, it is passed to the client-side components of the function modules (step 3 in the figure above). These correspond with their server-side counterparts (step 4) in a secure two-party computation. The client then processes the decrypted email according to the output (for example, labelling the message as spam), and delivers it to the recipient (step 5).
Pretzel’s e2e module requires cryptographic keys for encrypting, decrypting, signing, and verifying. Thus, Pretzel requires a solution to key management. However, this is a separate effort, deserving of its own paper or product…
Cryptographic building blocks
For the function modules Pretzel builds on two-party computation using Yao. If 




At a very high level, Yao works by having one party generate encrypted truth tables, called garbled Boolean gates, for gates in the original circuit, and having the other party decrypt and thereby evaluate the garbled gates.
Yao is expensive to evaluate though, so Pretzel uses Yao very selectively. Alongside Yao, Pretzel uses a secure dot product protocol called GLLM, which is provable secure, state-of-the-art, and widely used.
One party starts with a matrix and encrypts the entries. The other party starts with a vector and leverages additive (not fully) homomorphic encryption (AHE) to compute the vector-matrix product in cipherspace, and blind the resulting vector. (Multiplying a matrix by a vector is of course a foundational operation in machine learning). The first party decrypts the result to obtain the blinded vector, which is then fed into Yao where the threshold comparison (for spam filtering), or the maximal selection (for topic extraction) happens. The overall process is summarised in the following figure:

(Enlarge)
From possible to practical
The baseline just described is a promising foundation for private classification. But adapting it to an end-to-end system for encrypted email requires work. The main issue is costs. As examples, for a spam classification model with N = 5M features, the protocol consumes over 1GB of client-side storage space; for topic extraction with B=2048 categories, it consumes over 150ms of provider-side CPU time and 8MB in network transfers.
The traditional choice for the additive homomorphic encryption required by Pretzel is Pallier, but its decryption operation takes hundreds of milliseconds on modern CPUs. So Pretzel instead uses a cryptosystem based on the Ring-LWE assumption, “a relatively young assumption (which is usually a disadvantage in cryptography) but one that has nonetheless received a lot of attention. Using the XPIR system which implements this idea, the cost of each invocation of the decryption operation comes down by over an order of magnitude to microseconds, and similarly for encryption.
A disadvantage of this swap, is that ciphertexts get 64x larger. But by using a packing technique this can be contained. Packing compresses a matrix enabling more to be represented in a single ciphertext. The base GLLM algorithm packs matrix rows, Pretzel incorporates recent developments in packing techniques that can pack across both rows and columns.
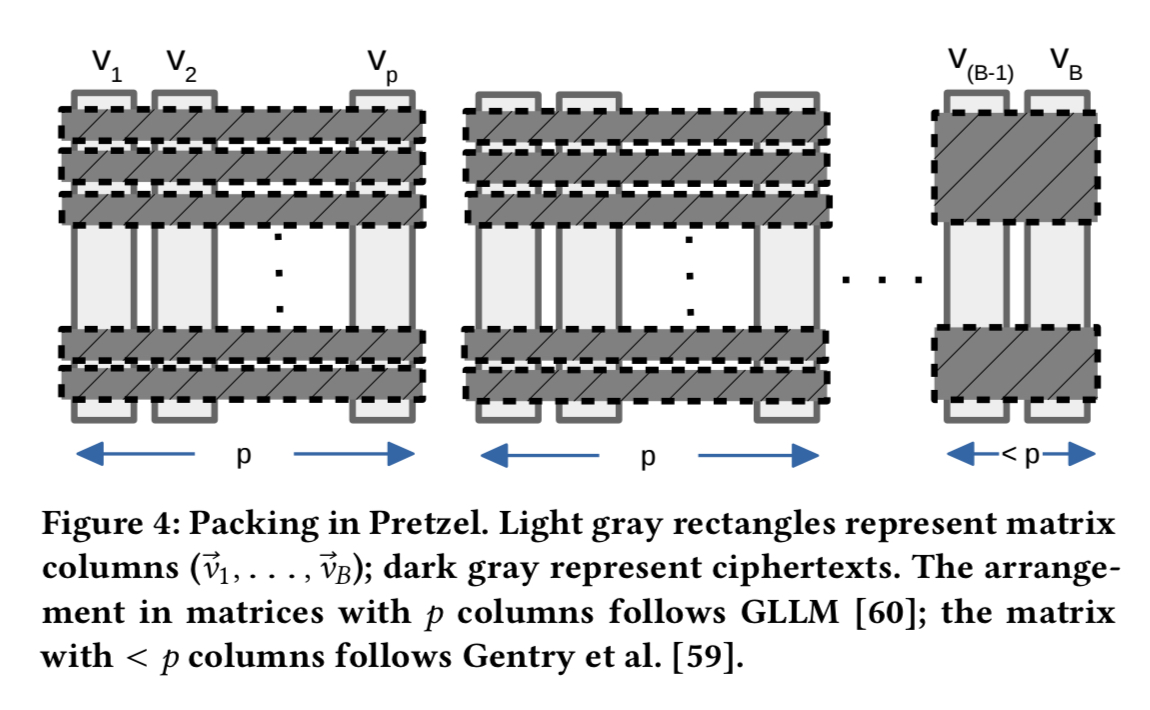
Thus far the costs are largely proportional to the number of classes in the classifier – that works great for spam, but it’s more of an issue for topic extraction, where we may have thousands of classes. Pretzel uses a two-stage process the authors call decomposed classification to get around this.
- First the email is mapped (by the client) to a set of candidate topics. The size of this set is capped at e.g., 20 topics.
- Then secure two-party machinery is used to map this smaller set down to a single topic.
This is made possible because the topic lists the client needs to use in the first step are already public (they have to be, so that advertisers can target based on them).
… at a high level, this protocol works as follows. The provider supplies the entire proprietary model (with all B topics); the client obtains B dot products, in encrypted form, via the inexpensive component of Yao+GLLM (secure dot product). The client then extracts and blinds the B’ dot products that correspond to the candidate topics. The parties finish by using Yao to privately identify the topic that produced the maximum.
By reducing the number of features in the model, Pretzel can make further large improvements in client-storage costs. They find that reductions of up to 75% in the number of features is a plausible operating point, with accuracy dropping only modestly.
Overheads
- Pretzel’s provider-side CPU consumption for spam filtering and topic extraction is, respectively, 0.65 and 1.03-1.78x of a non-private arrangement, and respectively, 0.17x and 0.01-0.02x of its baseline (before optimisations). The provider side CPU consumption is sometimes lower than in a non-private setting because the protocols shift work to the client).
- Network transfers are between 2.7-5.4x of a non-private arrangement, and 0.024-0.048x of the baseline.
- Client-side CPU consumption is less than 1s per email, and storage space use is a few hundred MBs. (A ‘few factors’ lower than the baseline).
- For topic extraction, the reduction in number of features leads to a drop in accuracy of between 1-3%.
For an average user receiving 150 emails daily of average size (75KB), and using a mobile device with 32GB of storage the total spam filtering time is less than a minute per day. An encrypted model with 5M features would occupy 183.5MB, 0.5% of the device’s storage. The network overheads add up to 2.8MB per day. Topic extraction uses less than 75 seconds of CPU time per day, and another 720MB of storage space. Client transfers add an extra 59MB per day (5x the base email size).
Overall, these costs are certainly substantial — and we don’t mean to diminish that issue — but we believe that the magnitudes in question are still within tolerance for most users.
Limitations
Pretzel today only handles spam filtering, topic extraction, and basic keyword search. It would need to be extended to handle other functions such as virus scanning. Adapting Pretzel to also hide metadata (which can leak a lot of information!) is future work.
More fundamentally, Pretzel compromises on functionality; by its design both user and provider have to agree on the algorithm, with only the inputs being private. Most fundamentally, Pretzel cannot achieve the ideal of perfect privacy; it seems inherent in the problem setup that one party gains information that would ideally be hidden. However, these leaks are generally bounded, and concerned users can opt out, possibly at some dollar cost.

{kind=link}