Detecting credential spearphishing attacks in enterprise settings Ho et al., USENIX Security 2017
The Lawrence Berkeley National Laboratory (LBNL) have developed and deployed a new system for detecting credential spearphishing attacks (highly targeted attacks against individuals within the organisation). Like many anomaly detection systems there are challenges of keeping the false positive rate acceptable (not flooding security staff with alerts), while dealing with a large class imbalance (most emails are benign) and unknown underlying distribution. From 370M emails for example, they are looking for just 19 such spearphising campaigns. The team manage to achieve a false positive rate of 0.004% within a daily budget of 10 alerts. Security staff can process an entire month’s worth of alerts in just 15 minutes. That’s a very pragmatic and useable anomaly detection system! Even though the system is now deployed at LBNL, it does have a number of limitations,some of which seem quite important to me, but I guess every little helps!
Because of our approach’s ability to detect a wide range of attacks, including previously undiscovered attacks, and its low false positive cost, LBNL has implemented and deployed a version of our detector.
Credential spearphishing: the lure and the exploit
Credential spearphishing involves an attacker sending a carefully crafted deceptive email that attempts to persuade the victim to click on an embedded link. The link is to a website owned by the attacker, set up to look like a legitimate system, when the victim logs on to what they believe is the real system, the attacker steals their credentials.
From an attacker’s perspective, spearphishing requires little technical sophistication, does not rely on any specify vulnerability, eludes technical defenses, and often succeeds.
Spearphishing is the predominant attack vector for breaching valuable targets. Campaigns are specifically targeted at users who have some kind of privileged access or capability (senior executives, system administrators, …). Humans are the weakest link!
There a two elements to a spearphishing attack: the lure and the exploit. The lure aims to get the victim to click on a link, and thus must establish credibility through a sense of trust or authority.
Attackers typically achieve this by sending the email under the identity of a trusted or authoritative entity and then including some compelling content in the email.
Establishing trust starts with fooling the recipient into thinking the email has come from a trustworthy source. There are a variety of impersonation models:

- An address spoofer manipulates email From headers to look exactly like the genuine headers you would see if this really were an email from Alice Good. DKIM and DMARC will block this, so the detector does not look for this class of spoofing.
- A name spoofer spoofs the name component of the From header, but uses a different email address, thus circumventing DKIM/DMARC. Many email clients show only the name by default, and not the email address.
- A previously unseen attacker selects a fake name designed to convey authority, for example “LBNL IT Staff,” and a plausible looking role-based email address, e.g. “helpdesk at enterpriseY.com.”
- A lateral attacker uses a compromised account from within the same organisation as the victim.
For credential spearphising, the exploit (payload) is a link to a credential phishing page.
Detection features
So how do you find suspicious looking senders without generating lots of false alerts?
… a detector that only leverages the traditional approach of searching for anomalies in header values faces a stifling range of anomalous but benign behavior.
You could try looking for a From header with a recognised (previously seen) name, but a different email address. But multiple people do share names, and people also have multiple email addresses (personal accounts and so on).
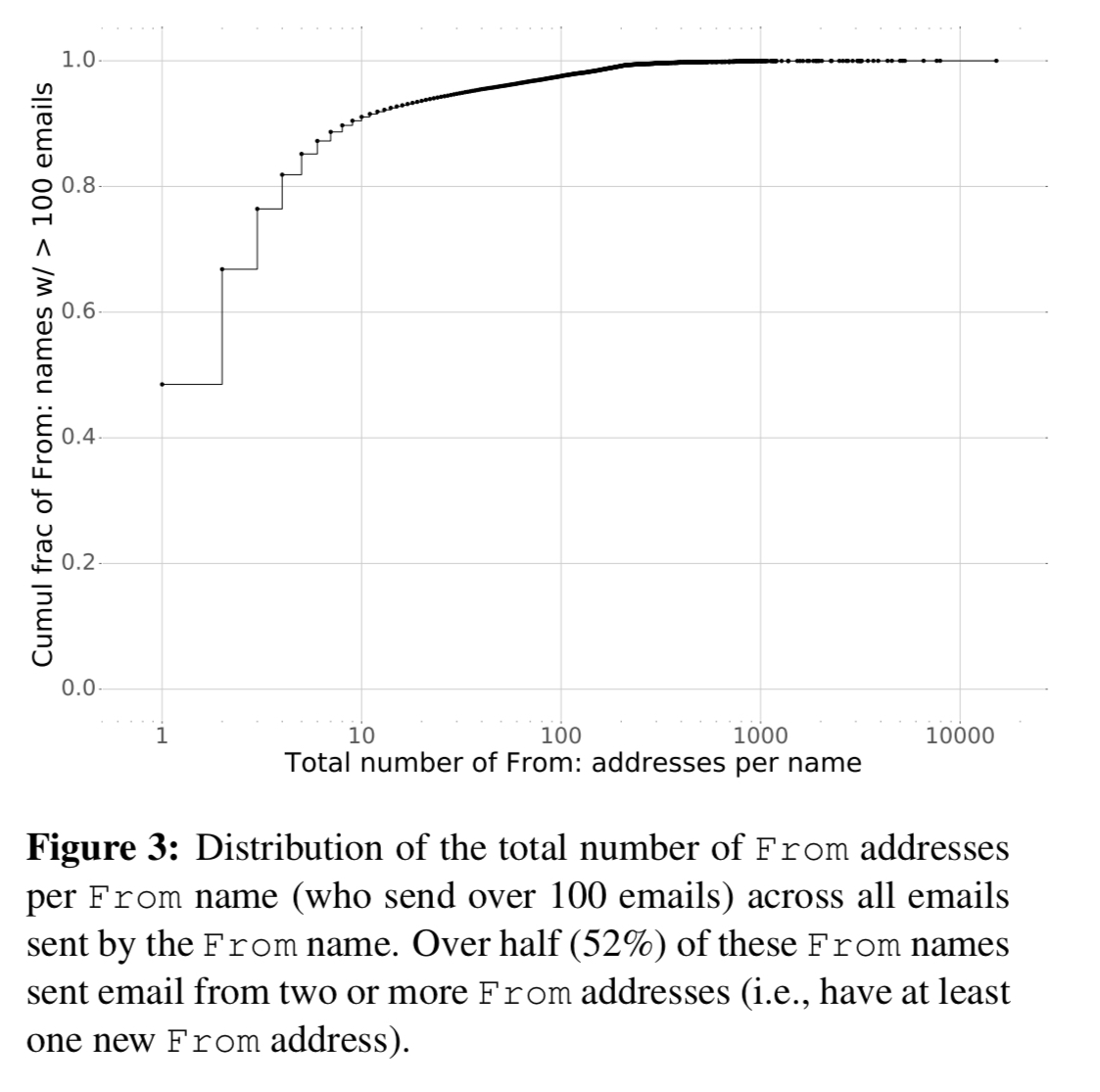
And of course, such an approach can never detect the previously unseen sender attack vector. If you try flagging on emails that come from previously unseen senders, you will generate way too many false positives:
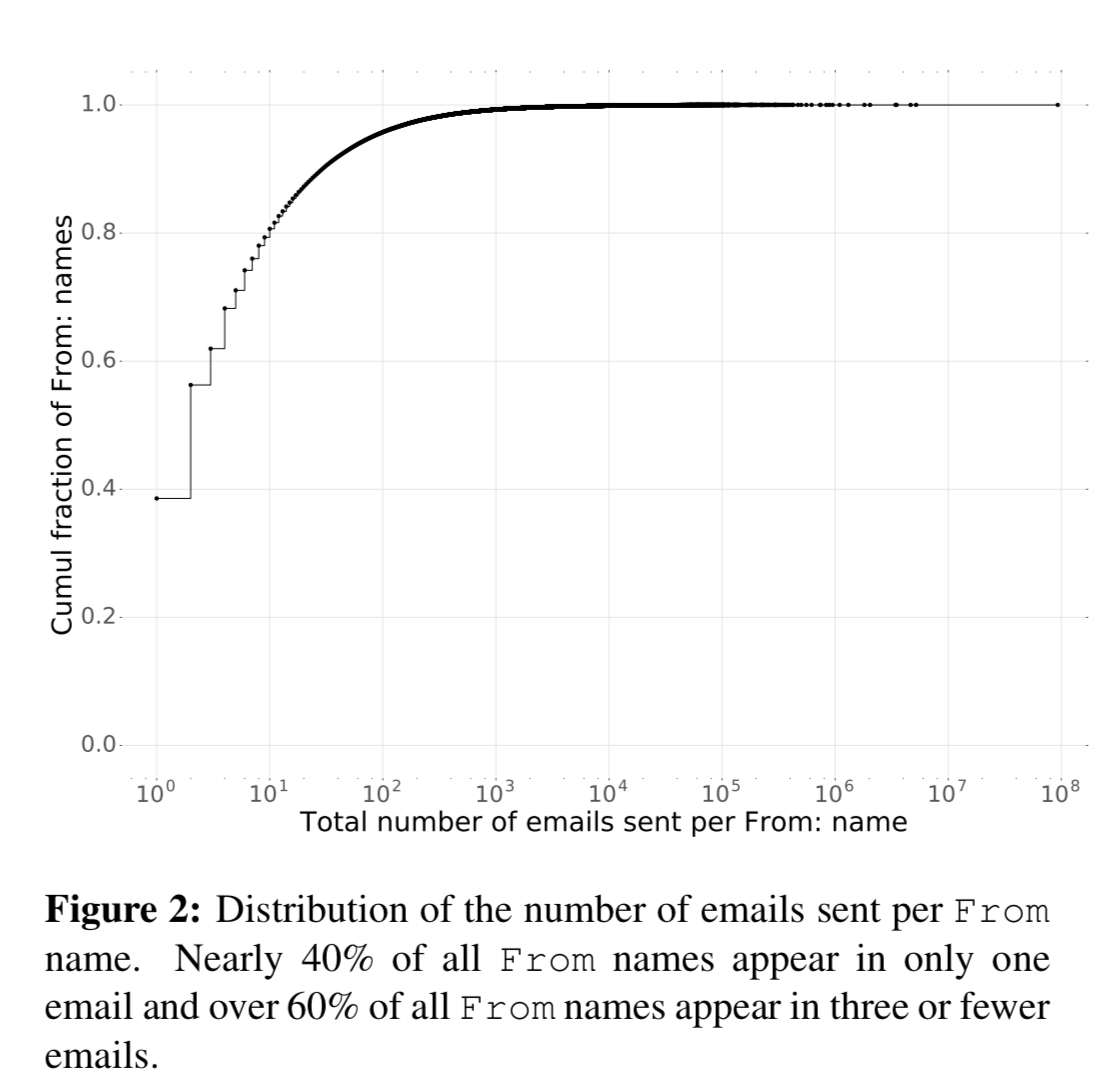
As well as multiple addresses per name, you also run into multiple names per address. For example “Foo <noreply at Foo.com>”, “Foo <help at foo.com>” and so on.
The authors combine two sets of detection features: lure detection features which look at email headers, and exploit detection features which look at clicked links.
For credential spearphishing, the dangerous action is clicking on a link in an email that leads the victim to a credential phishing website. Thus, we analyze every email that contains a link that a user clicked on.
(This is one of the limitations in the current approach, and it seems kind of a big one to me – you can detect credential spearphishing after the victim has already clicked on the link, but in many cases by then the damage will already have been done. Rapid detection is still better than no detection though…).
A domain’s reputation (the fully-qualified domain name in a URL) is based on two features in the model:
- A count of the number of prior visits to any URL with the same FQDN as the clicked URL. If few employees have ever visited it, this increases suspicion.
- The number of days between the first visit by any employee to a URL on the the clicked link’s FQDN, and the clicking of the link in this email. If the domain also appeared only very recently, this increases suspicion.
There are two features each to detect name spoofing, previously unseen attackers, and lateral attackers. For name spoofing the features are:
- The number of previous days where we saw an email from the same name and address
- The total number of weeks where this name sent at least one email for every weekday of the week (attackers are likely to choose from names likely to be perceived as familiar and trustworthy).
For previously unseen attackers the features rely on the attacker seeking to avoid detection by only using the spoofed identity infrequently:
- The number of prior days that the from name has sent email
- The number of prior days that the from address has sent email
Lateral attacks features look at where the email was sent from during a login session – is this a place the employee being spoofed usually sends email from?
- The number of distinct employees that have logged in from the geolocated city of the session IP address
- The number of previous logins where this sender employee logged in from an IP address geolocating to this city
Finding anomalies
Even with these features, detecting anomalies efficiently is hard. We can’t set manual thresholds because we don’t know the true distribution of feature values. We can’t use supervised learning because there is an extreme class imbalance. Standard unsupervised or semi-supervised anomaly detection mechanisms don’t take into account direction (in our setting, a domain with very few visits is suspicious, one with an unusually large number is not). They also flag anomalies if only one or a small number of features are anomalous, whereas the authors are looking for attacks that are suspicious in all feature dimensions (for each combination of FQDN features + From spoofing attack vector – there are actually three sub-detectors). Finally, classical techniques are parametric, either assuming an underlying distribution or that parameters can be set using domain knowledge.
These requirements are problematic for spearphishing detection since we do not know the true distribution of attack and benign emails, and the underlying distribution might not be Guassian, and we do not have a sound way to select the parameters.
So instead, the authors use a simple ranking approach they call Directed Anomaly Scoring (DAS).
At a high level, DAS ranks all events by comparing how suspicious each event is relative to all other events. Once all events have been ranked, DAS simply selects the N most suspicious (highest-ranked) events, where N is the security team’s alert budget.
The score for an event E is computed by looking at the total number of other events where E’s feature vector is at least is suspicious as the other event in every dimension.
The whole system runs end-to-end like this:
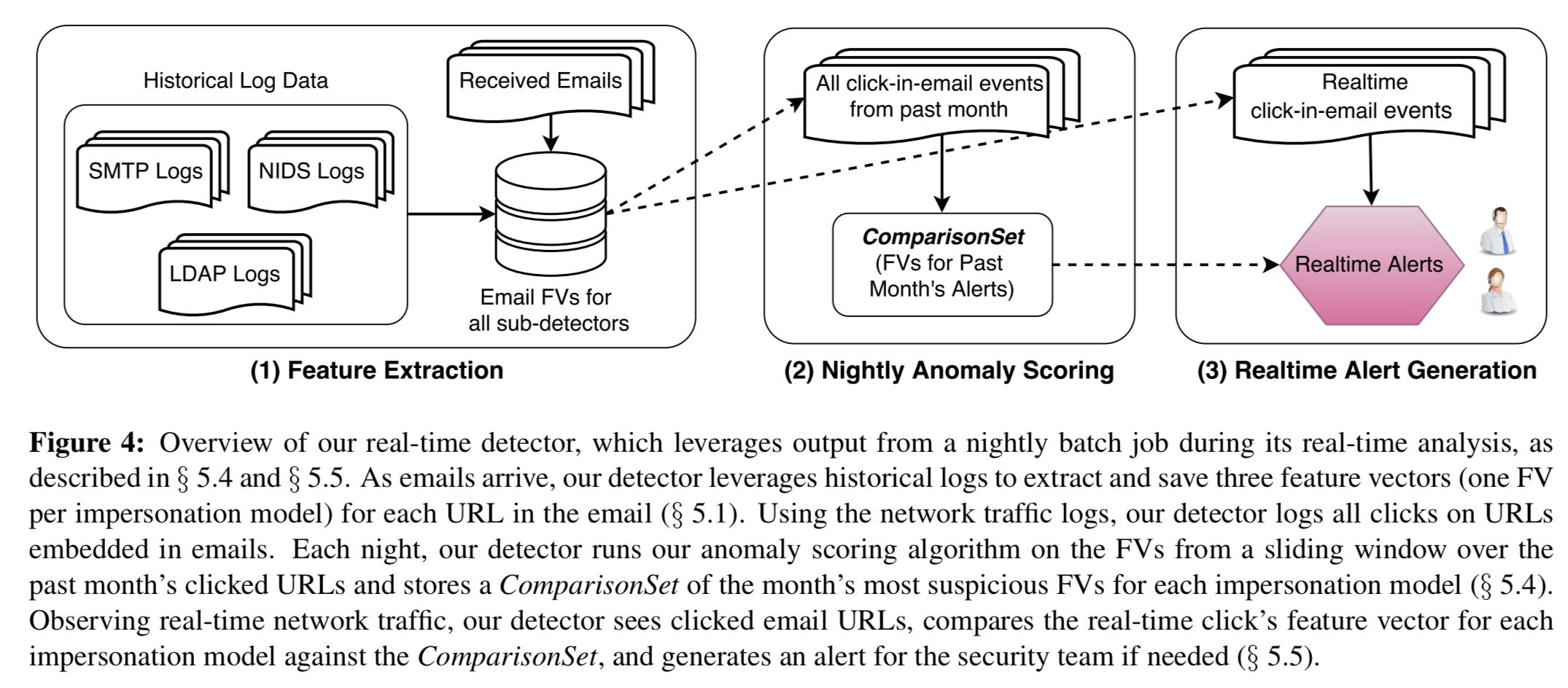
Every night the detector collects all the click-in-email events for the past month and computer their associated feature vectors. For each sub-detector, the 
Detection results
With the alert threshold set at 10 alerts per day, the system was evaluated over 4 years worth of email logs and the LBNL incident database containing 7 known successful spearphishing attacks, and 15,521 manually investigated and labelled alerts.
… we identified a total of 19 spearphishing campaigns: 9 which succeeded in stealing an employee’s credentials and 10 where he employee clicked on the spearphising link, but upon arriving at the phishing landing page, did not enter their credentials… Overall, our real-time detector successfully identifies 17 out of 19 spearphishing campaigns, a 89% true positive rate.

The detector missed one successful attack from the LBNL database – this used a now deprecated Dropbox feature that allowed users to host static HTML pages under one of Dropbox’s primary hostnames. This feature led to a large number of phishing attacks against Dropbox users! The detector also found 2 previously undiscovered attacks that did in fact successfully steal credentials.
Limitations
Some limitations that jumped out to me with the current system:
- Email and network activity conducted outside of LBNL’s borders does not get recorded in NIDS logs.
- LBNL made a conscious decision not to man-in-the-middle HTTPS, so any attacks where the email links to an HTTPS website will go undetected (!). A detector could potentially use SNI to develop a domain reputation for HTTPS.
- It only works after the horse has already bolted. A solution here is to rewrite URLs in suspicious emails (scoring them as-if the links were clicked) before delivering them.

The paper looks at the links clicked to assess the effectiveness of the approach. Couldn’t a real system could be preemptive by looking at the pages at the links in the email? That would address what you point out is a weakness of the approach and would be fairly easy to automate robustly.
Thanks for these, absolutely fascinating way to learn a lot about CS in a little amount of time. :)