CLKSCREW: Exposing the perils of security-oblivious energy management Tang et al., USENIX Security ’17
This is brilliant and terrifying in equal measure. CLKSCREW demonstrably takes the Trust out of ARM’s TrustZone, and it wouldn’t be at all surprising if it took the Secure out of SGX too (though the researchers didn’t investigate that). It’s the deepest, widest impact, hardest to fix security issue I’ve seen in a long time.
Designing secure systems is really hard. One side channel, control over one single bit, and you can be compromised. Fault attacks try to induce bit corruptions at key moments. Differential fault attacks (DFA) compare execution under normal and faulted conditions, and can be use for example to infer AES keys based on pairs of correct and faulty ciphertexts. For example:
Assuming a fault can be injected during the seventh AES round to cause a single-byte random corruption to the intermediate state in that round, with a corrupted input to the eighth round, this DFA can reduce the number of AES-128 key hypotheses from the original 2^128 to 2^12, in which case the key can be brute-forced in a trivial exhaustive search.
Physical fault attacks require access to the device, opening it up, and using e.g., lasers, heat or radiation. But what if you could conduct remote fault attacks via software? It turns out that all of the well-intentioned mechanisms we’ve been adding for power and energy management let you do exactly that.
In this work, we present the CLKSCREW attack, a new class of fault attacks that exploit the security-obliviousness of energy management systems to break security. A novel benefit for the attackers is that these fault attacks become more accessible since they can now be conducted without the need for physical access to the devices or fault injection equipment.
Demonstrating the potency of the attack on commodity ARM devices (a Nexus 6 phone), the authors show how it can be used to extract secret keys from an ARM TrustZone, and can escalate privileges to load self-signed code into Trustzone.
Oh and by the way, energy management technology is everywhere, and there doesn’t seem to be any quick fix for CLKSCREW. It’s not a software bug, or a hardware bug, it’s a fundamental part of the energy management design. SoC and device vendors are apparently “working towards mitigations.”
To understand how CLKSCREW works, we first need a little bit of background on DVFS, Dynamic Voltage and Frequency Scaling.
Dynamic Voltage and Frequency Scaling
DVFS made its debut in 1994, and has become ubiquitous in almost all commodity devices since. It works by regulating frequency and voltage: power, an important determinant of energy consumption, is directly proportional to the product of operating frequency and voltage.
DVFS regulates frequency and voltage according to runtime task demands. As these demands can vary drastically and quickly, DVFS needs to be able to track these demands and effect the frequency and voltage adjustments in a timely manner. To achieve this, DVFS requires components across layers in the system stack.
There are voltage/frequency regulators in hardware, a vendor-specific regulator driver, and an OS-level CPUfreq power governor. Because accurate layer-specific feedback is needed to do a good job of power management, software level access to the frequency and voltage regulators is freely available.
The frequency regulator contains a Phase Lock Loop (PLL) circuit that generates a synchronous clock signal for digital components. The frequency of the clock is adjustable, and typically the operating frequency of each core can be individually controlled. In the case of the Nexus 6 for example, each core can be set to one of three frequencies. Power to the cores is controlled by the Subsystem Power Manager with memory-mapped control registers to direct voltage changes.
Pushing the frequency too high (overclocking) or under-supplying voltage (undervolting) can cause unintended behaviour in digital circuits. Memory flip-flops change their output to the value of the input upon the receipt of the rising edge of the clock signal. The input has to be held stable for a time window while this happens. Overclocking reduces the clock cycle time below this stable period, and undervolting increases the overall circuit propagation time meaning that the period the input needs to be stable increases. The following figure shows an example leading to an erroneous value of 0 due to overclocking.
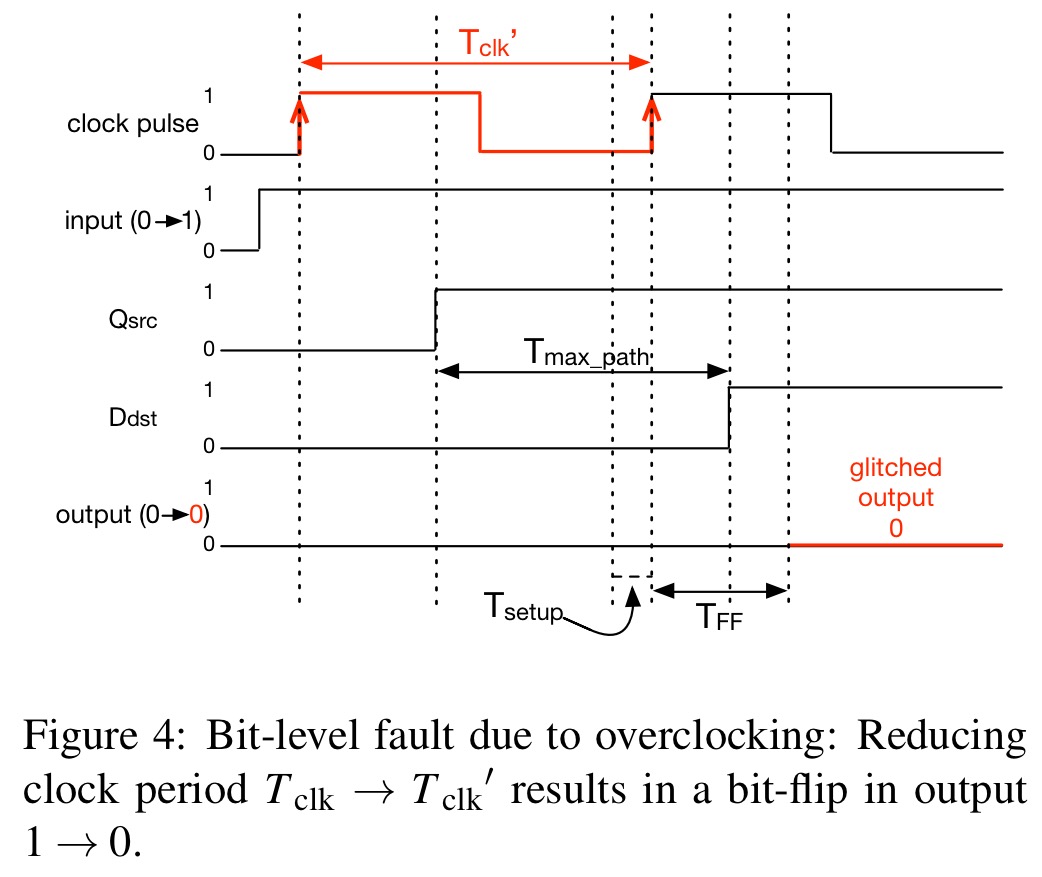
Challenges in constructing a CLKSCREW attack
We need to be able to:
- push the operating limits of regulators to a point where such attacks can take place.
- conduct the attack in a manner that does not affect the execution of the attacking code
- inject a fault into the target code without causing too much perturbation to non-targeted code
- be relatively precise in when the fault is injected
- target a specific range of code execution that may take orders of magnitude fewer clock cycles within an entire operation
The authors demonstrate how to achieve all of these.
On the Nexus 6 as an example, there are 15 possible official Operating Performance Points. By probing the device by stepping through voltage and frequency ranges until it either reboots or freezes, the authors demonstrate large areas beyond the official operating performance points where the regulators can be configured:
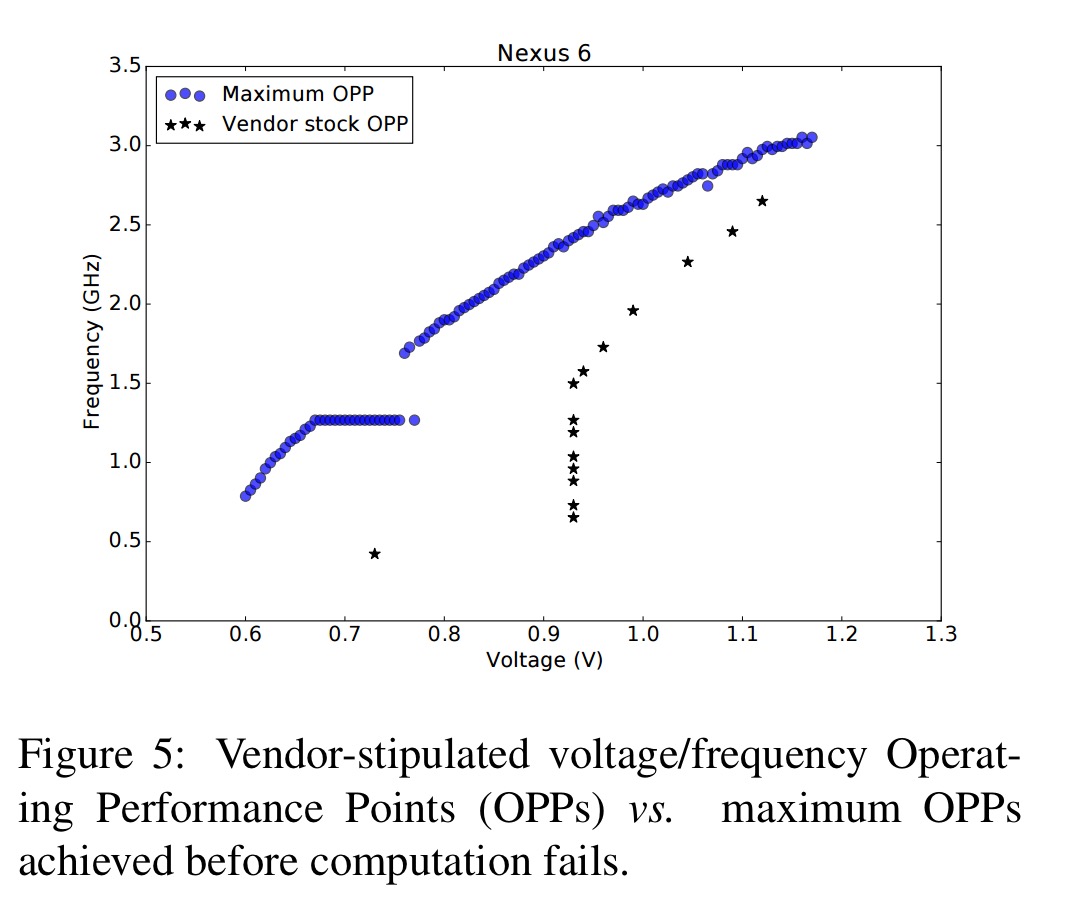
Attack enabler #1: There are no safeguard limits in the hardware regulators to restrict the range of frequencies and voltages that can be configured.
In the figure above we can see that reducing the operating voltage simultaneously lowers the minimum required frequency needed to induce a fault in an attack (push the system above the blue line). Thus if the frequency settings don’t let us set the clock fast enough, we can always reduce the voltage.
Attack enabler #2: reducing the operating voltage lowers the minimum required frequency to induce faults.
To attack target code without disrupting the attacker, we can simply pin the attack code and the victim code to different cores, since this allows each of them to operate in different frequency domains.
Attack enabler #3: the deployment of cores in different voltage/frequency domains isolates the effects of cross-core fault attacks.
To attack trusted code running in ARM Trustzone (Intel SGX works the same way), we can take advantage of the fact that ARM can execute both trusted and untrusted code on the same physical core. “On such architectures, the voltage and frequency regulators typically operate on domains that apply to cores as a whole.” Thus any frequency or voltage change initiated by untrusted code inadvertently affects the trusted code execution.
Attack enabler #4: hardware regulators operate across security boundaries with no physical isolation.
For timing of the attack (to flip a bit at the moment we want to), we can combine profiling to find out how long to wait, with a spin-loop in the attacking code to delay this amount of time before triggering the fault. A couple of Trustzone specific features help with the profiling part of the puzzle:
Attack enabler #5: execution timing of code running in Trustzone can be profiled with hardware counters that are accessible outside Trustzone
And…
Attack enabler #6: memory accesses from the non-secure world can evict cache lines used by Trustzone code, thereby enabling Prime+Probe style execution profiling of Trustzone code.
Putting it all together, the key steps in a CLKSCREW attack are as follows:
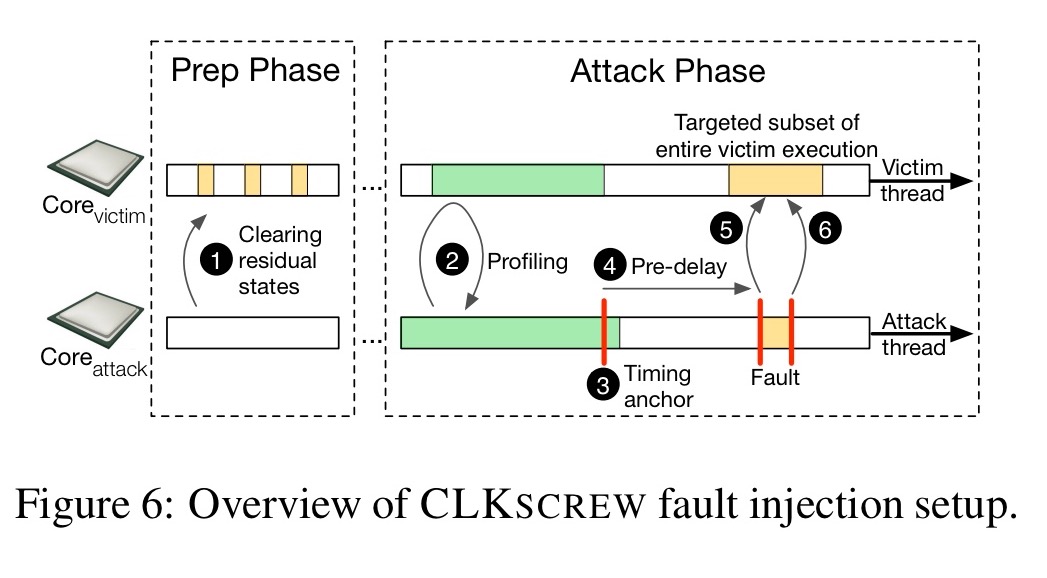
- Invoke both the victim and attack threads a few times in quick succession to clear away any microarchitectural residual states remaining from prior executions of other code.
- Profile for a timing anchor to determine when to deliver the fault injection
- For high-precision delivery, configure the attack thread to spin-loop a predetermined number of times before inducing the fault
- Given a base operating voltage, raise the frequency of the victim core, keep it high for long enough to induce the fault, then restore it to its original value.
Example attack: inferring AES keys
In section 4 of the paper the authors show how AES keys stored within Trustzone can be inferred by lower-privileged code from outside Trustzone. Using a hardware cycle counter to track the execution duration (in cycles) of the AES decryption operation allows an attacker to determine the execution time. Here’s a plot over 13K executions:
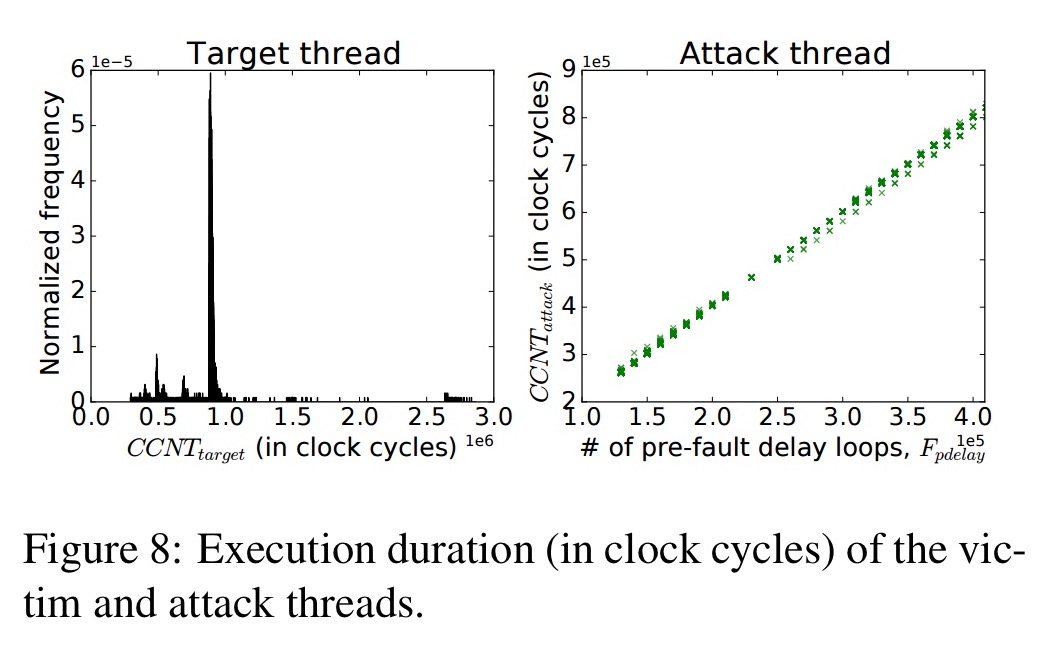
A grid search finds the faulting frequency and duration that induce erroneous AES decryption results. Then by varying the delay before inducing the fault they find that about 60% of faults are precise enough to affect exactly one AES round, and more than half of these cause random corruptions of exactly one byte.
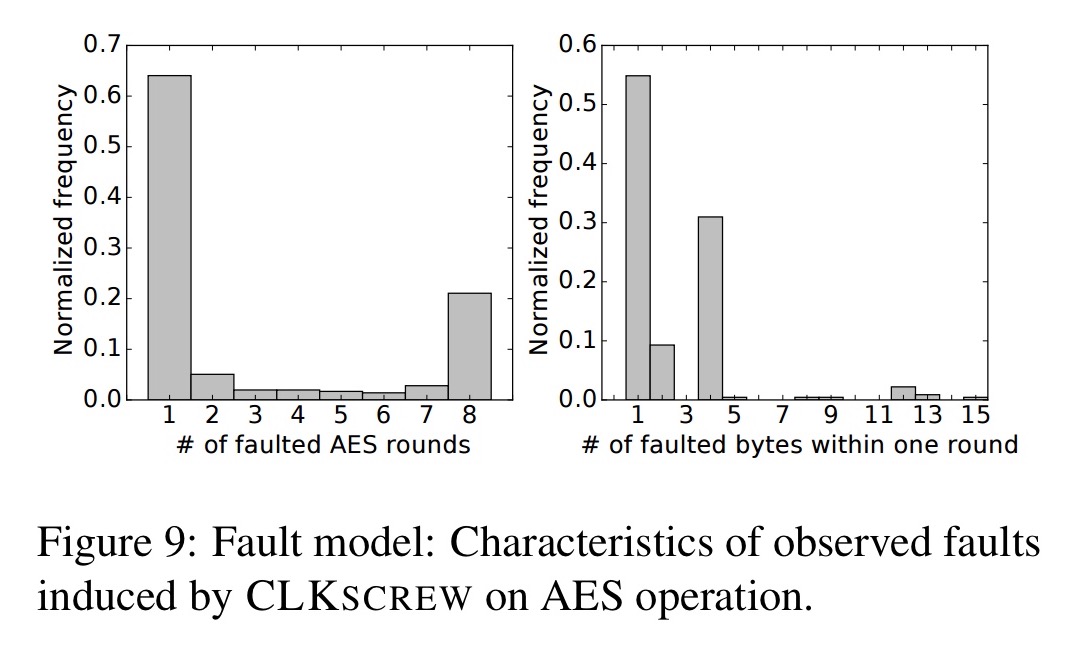
As we saw in the introduction…
… Being able to induce a one-byte random corruption to the intermediate state of an AES round is often used as a fault model in several physical fault injection works.
With all the parameters worked out, it took on average 20 attempts to induce a one-byte fault to the input of the eight AES round. Given the faulty plaintext produced by this, and the expected one, it took about 12 minutes using Tunstall et al.’s DFA algorithm to generate 3650 key hypotheses – one of which is the key stored within Trustzone.
Example attack: loading self-signed apps
In section 5 of the paper the authors show how CLKSCREW can subvert RSA signature chain verification used in loading firmware images into Trustzone. The details are ingenious, and I don’t have space to cover them all here (do check out the full paper if you’re interested, you’re missing a lot otherwise). The aha moment for me was as follows: the RSA cryptosystem depends on the computational infeasibility of factorizing a modulus N into its prime factors p and q. If we can corrupt one or more bits in N, then it’s likely we’ll end with a composite number of more than two prime factors – some of which are small – which we can factorize.
About 20% of faulting attempts resulted in a successful fault within the target buffer, yielding 805 faulted values, of which 38 were factorizable. Selecting one of the factorizable N_s the authors embed an attack signature into the _widevine trustlet and conduct CLKSCREW faulting attempts while invoking the self-signed app. On average, one instance of the desired fault occurred with every 65 attempts.
Defenses??
Section 6 discusses possible hardware and software defenses. The short version is that none of them seem particularly compelling. We’re probably looking at a deep and invasive redesign.
Our analysis suggests that there is unlikely to be a single, simple fix, or even a piecemeal fix, that can entirely prevent CLKSCREW style attacks. Many of the design decisions that contribute to the success of the attack are supported by practical engineering concerns. In other words, the root cause is not a specific hardware or software bug but rather a series of well thought-out, nevertheless security-oblivious design decisions.
A new class of attacks
I’ll leave you with this thought: CLKSCREW isn’t just the latest in a known exploit genre, CLKSCREW opens the door to a whole new class of energy-management based attacks.
As researchers and practitioners embark upon increasingly aggressive cooperative hardware-software mechanisms with the aim of improving energy efficiency, this work shows, for the first time, that doing so may create serious security vulnerabilities… Furthermore, CLKSCREW is the tip of the iceberg: more security vulnerabilities are likely to surface in emerging energy optimization techniques, such as finer-grained controls, distributed control of voltage and frequency islands, and near/sub-threshold optimisations.

Wow, that’s indeed scary. In the case of SGX, our SGX+TSX paper that appeared at the same conference could potentially hinder some prerequisites for the attack like a shared physical core and susceptibility to Prime+Probe.
An awesome and scary piece of work. Thanks for the write-up Adrian.
Great write-up… one question: Why is untrusted application code allowed to change the regulator/clk settings? Or am I misunderstanding the nature of the vulnerability?
That is the problem, it is an actual hardware implementation bug (and therefore hard to fix), where security on the electrical level was simply forgotten.
A secure implementation would: 1. Allow Vdd/Freq. pairs to be programmed only by trusted code (trusted in terms of “TrustZone”). 2. untrusted code (the linux kernel in this case) would only be allowed to select certain Vdd/Freq. pairs, but not Vdd and Freq individually.
That is similar to how x86 systems are calibrated during manufacturing, and the software side typically just uses certain speed levels (Vdd/Freq pairs), where also e.g. turbo-boosting is directly handled in the hardware. That gives less responsibility to the OS power management.
In lower-cost ARM systems, the OS typically has to do all of the power management, with therefore higher responsibility for safe&secure operation.
However, I guess x86 systems could also be vulnerable, as soft-mods to change Voltage/Frequency pairs exist.
As I read it the untrusted code is user-code, so the OS *could* still protect against this… or am I wrong?
Just to clarify: Sorry if it sounded like it, I also just read the paper and I am not involved with the work.
To the question: I think it depends which OS you mean. The Linux Guest, System Supervisor? From my understanding, the attack needs to have access to manipulate the running Linux Kernel’s internals. However ARM TrustZone operates to protect below that level. So, even when the untrusted guest OS (Linux) has a vulnerability and one can manipulate it to this extent, TrustZone should protect from further consequences to the rest of the system. This was shown to be not the case (however, if anyone has to be blamed it would probably rather be the SoC vendor, and not ARM).
This kind tells u why HW based Sec is the based and discrete TPM has ways to shut this down via active monitoring mechanism
Would it be a big step beyond this work to try to find the hardware-embedded manufacturer secret keys for SGX/TrustZone?