Distributed deep neural networks over the cloud, the edge, and end devices Teerapittayanon et al., ICDCS 17
Earlier this year we looked at Neurosurgeon, in which the authors do a brilliant job of exploring the trade-offs when splitting a DNN such that some layers are processed on an edge device (e.g., mobile phone), and some layers are processed in the cloud. They find that partitioning can bring substantial benefits, and that the optimal partitioning varies dynamically according to network conditions, mobile battery life, and so on. Today’s paper choice introduces Distributed Deep Neural Networks or DDNNs. Similarly to Neurosurgeon, DDNNs partition networks between mobile/embedded devices, cloud (and edge), although the partitioning is static. What’s new and very interesting here though is the ability to aggregate inputs from multiple devices (e.g., with local sensors) in a single model, and the ability to short-circuit classification at lower levels in the model (closer to the end devices) if confidence in the classification has already passed a certain threshold. It looks like both teams worked independently and in parallel on their solutions.
Overall, DDNNs are shown to give lower latency decisions with higher accuracy than either cloud or devices working in isolation, as well as fault tolerance in the sense that classification accuracy remains high even if individual devices fail.
The big idea, distributed deep neural networks
Let’s quickly rehash the main arguments for partitioning a network between an end device and the cloud: often the end device isn’t powerful enough to run the full model, yet transmitting all of the raw sensor data to the cloud incurs significant overhead. If we can run the lower layers of the network on an end device then we only need to send the outputs of those layers up to the cloud, normally a significantly smaller data transmission. (See Neurosurgeon for a great analysis). Over and above this baseline, DDNNs can incorporate geographically distributed end devices (the example in the paper is a collection of devices with cameras attached, collectively covering a local area). DDNNs can scale vertically across multiple tiers (e.g., devices, edge / gateway, and cloud) and horizontally across devices.
… we propose distributed deep neural networks (DDNNs) over distributed computing hierarchies, consisting of the cloud, the edge (fog) and geographically distributed end devices. In implementing a DDNN, we map sections of a single DNN onto a distributed computing hierarchy.
Training happens centrally. Let’s explore some of the deployment topologies DDNNs enable:
As a starter for 10, here’s the classic “upload everything to the cloud and process it there” topology:
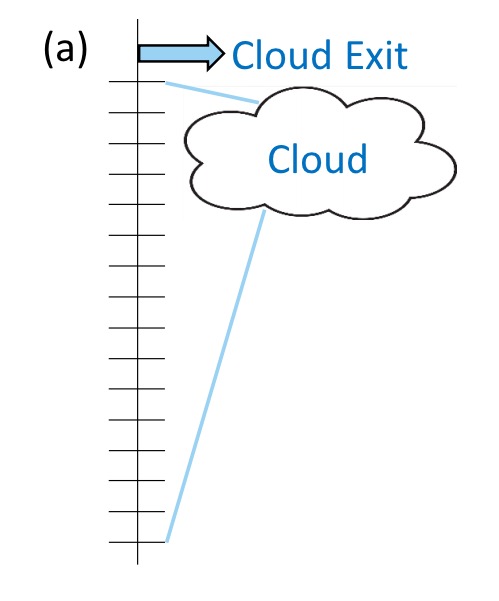
As in Neurosurgeon, we could also do some local processing on device, and then transfer a compressed representation to the cloud for further processing:
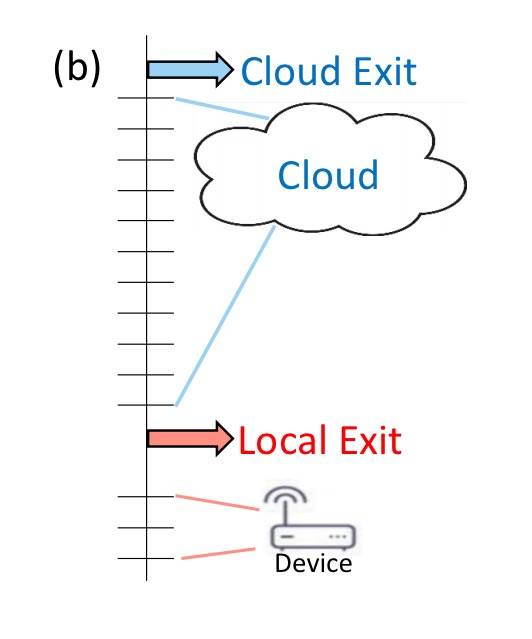
Note here the additional possibility of a fast local exit (we’ll discuss how this is possible in the next section). If we’re confident enough in the classification on the device itself, we can stop right there.
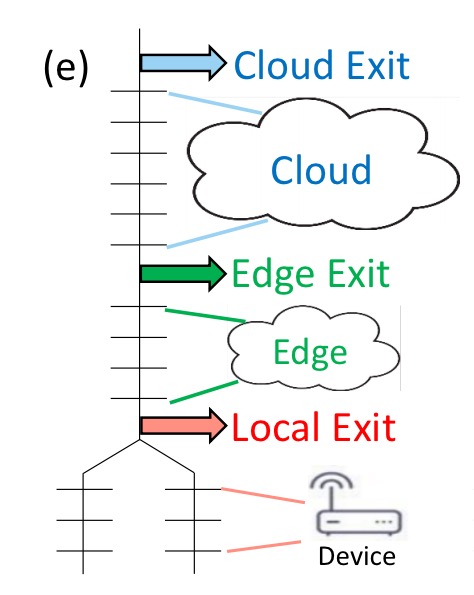
The next scenario shows how DDNNs can scale horizontally to include input from multiple distributed devices. The device inputs are aggregated in the lower layers of the network.
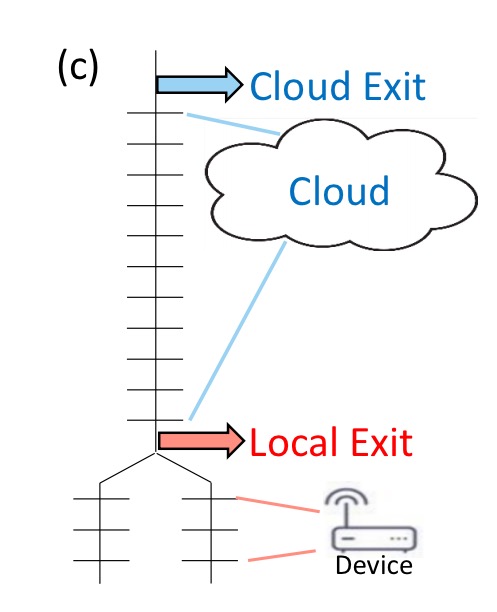
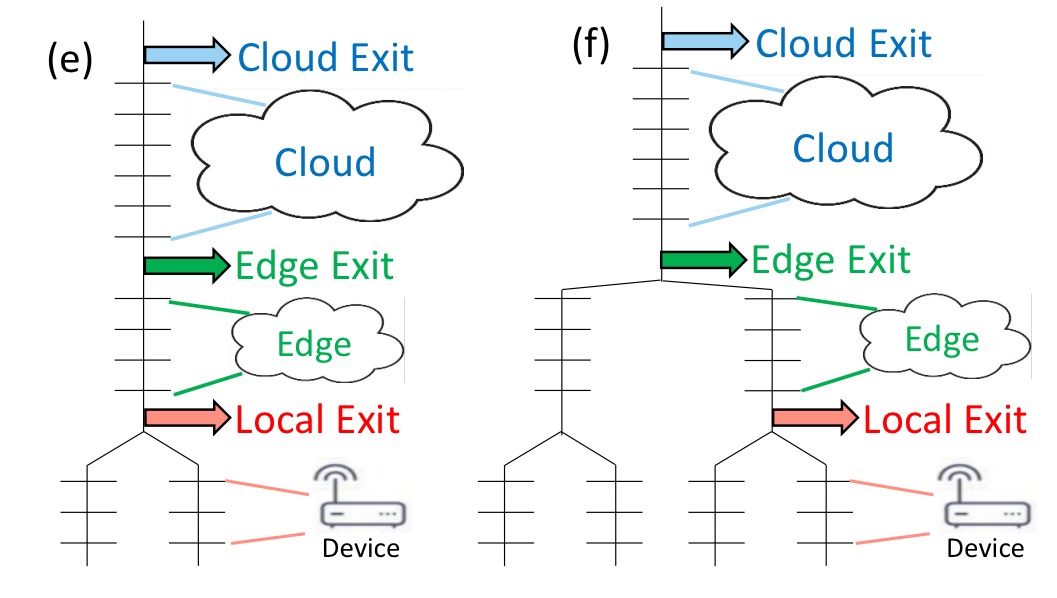
As well as scaling horizontally (the above scenario), we can also scale vertically, for example by introducing an additional tier (with another early exit opportunity) at the edge:
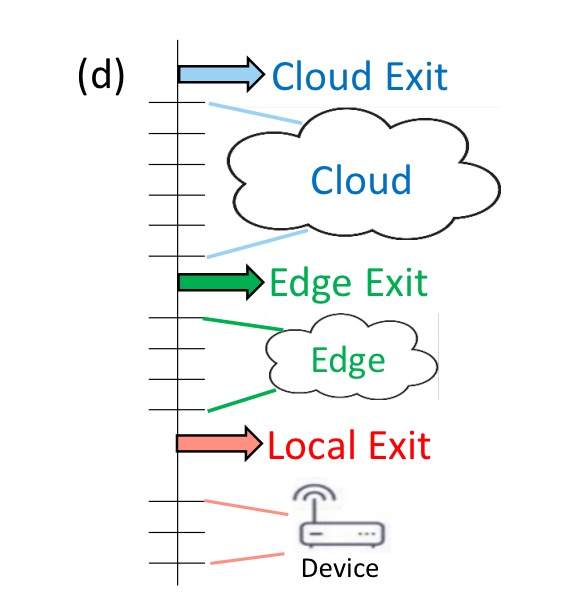
And of course, we can combine horizontal and vertical scaling to create interesting topologies such as these:
Building blocks: BNNs and BranchyNets
For efficiency on devices, DDNN uses Binarized neural networks:
Binarized neural networks (BNNs) are a recent type of neural network, where the weights in linear and convolutional layers are constrained to {-1, 1} (stored as 0 and 1 respectively)… Embedded binarized neural networks (eBNNs) extend BNNs to allow the network to fit on embedded devices by reducing floating point temporaries through re-ordering the operations in inference.
DDNN uses BNNs and eBNNs (now there’s a mouthful!) for end devices, so that they can be jointly trained with the network layers in the edge and the cloud.
To support early exit points, DDNN builds on prior work in BranchyNet. BranchyNet introduced entropy-based confidence criteria based on computed probability vectors. If confidence exceeds a given threshold, then the input is classified and no further computation is performed by higher network layers. DDNN places exit points at physical boundaries.
Aggregating inputs from multiple devices
In the examples above that included multiple component inputs to a layer (e.g., multiple end devices), we need a way to aggregate the input from each device in order to perform classification. There are three different techniques the authors experimented with for this: simple max pooling (MP) that takes the max of each component, average pooling (AP), and concatenation (CC) -simply concatenating all the input vectors together.
Training
While DDNN inference is distributed over the distributed computing hierarchy, the DDNN system can be trained on a single powerful server or in the cloud.
Training needs to take into account the possibility of early exits. These are accommodated by minimising a weighted sum of the loss functions at each exit point.
Inference
Inference in DDNN is performed in several stages using multiple preconfigured exit thresholds T (one element T at each exit point) as a measure of confidence in the prediction of the sample.
The authors used a normalised entropy threshold as the confidence criteria, yielding an uncertainty level between 0 and 1, where close to 0 means low uncertainty (high confidence).
Considering a topology such as this:
- Each end device first sends summary information to the local aggregator.
- The local aggregator determines if the combined summary information is sufficient for accurate classification.
- If so, the sample is classified (exited). (I’m assuming that if we wanted to communicate the classification result to the cloud, we could do that at this point).
- If not, each device sends more detailed information to the edge in order to perform further processing for clarification.
- If the edge believes it can correctly classify the sample it does so and no information is sent to the cloud.
- Otherwise, the edge forwards intermediate computation to the cloud which makes the final classification.
Evaluation: multi-view, multi-camera scenario
An example really helps here, and there’s a lot of good additional information contained in the evaluation. Consider a surveillance system (I’m not sure what else to call it really!) with six cameras attached to six different networked devices, and each placed at a different location in the same general area. We get image feeds from each camera, and the classifier the authors build simply plays a game of “car, bus, or person.”

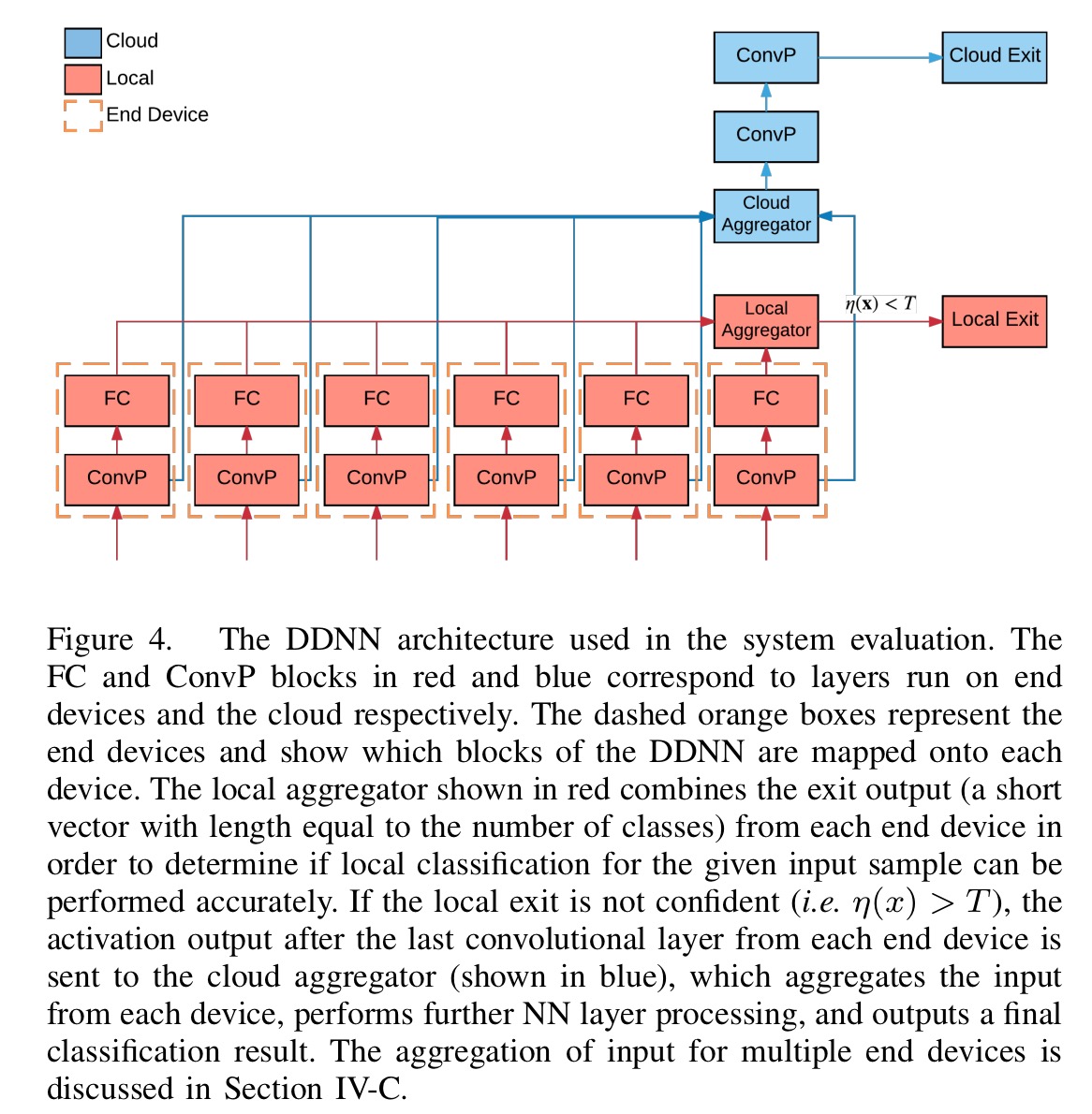
The DDNN architecture used for the evaluation looks like this (there’s some good information in the figure caption, which I won’t repeat here).
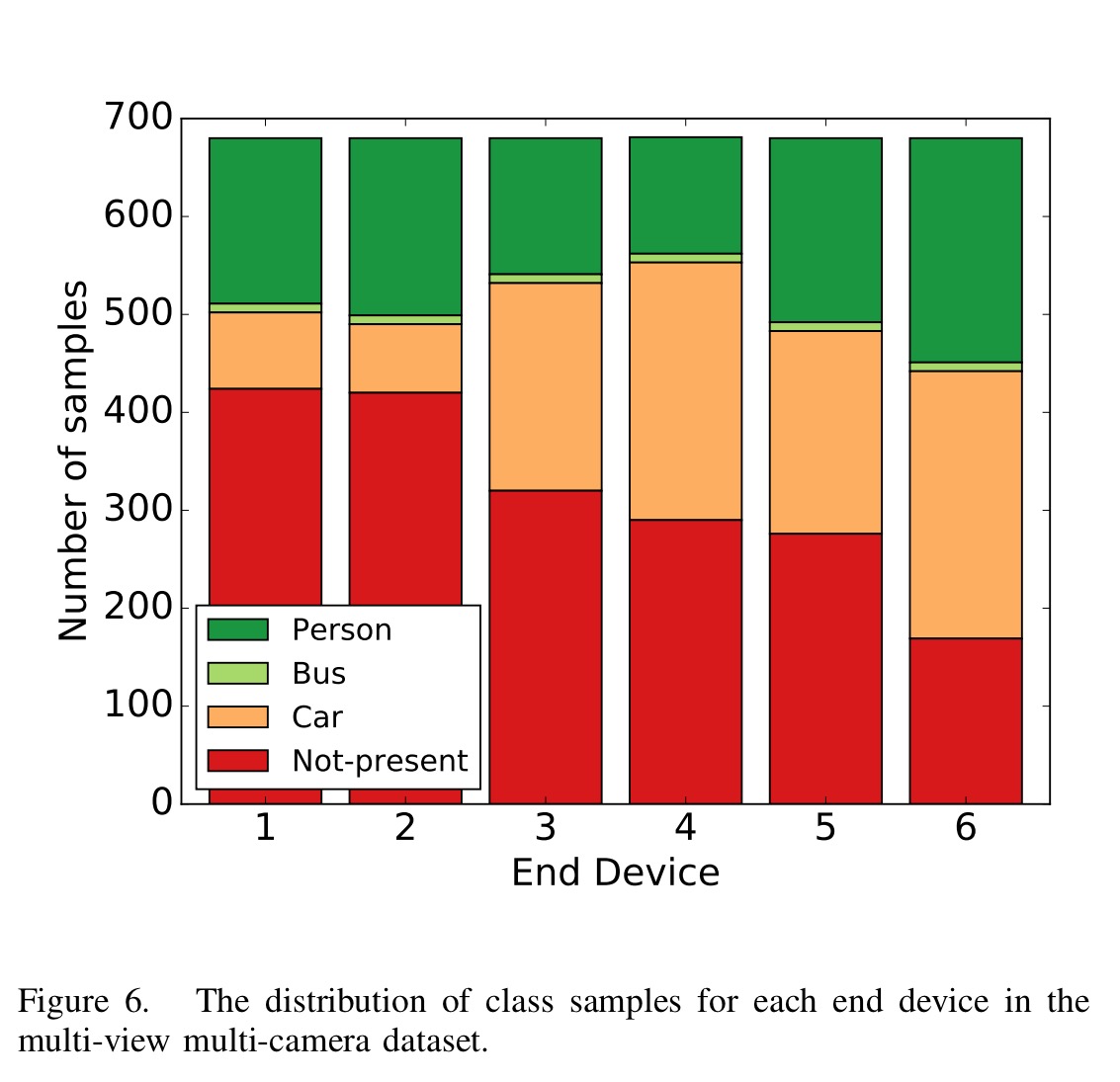
There are 680 training samples and 171 testing samples. Of note, the classes are not evenly represented and each device sees a different mix of samples – meaning that the individual accuracy of each device differs wildly.
The best aggregation combination turns out to be max pooling at the local aggregator, and concatenation at the cloud aggregator:
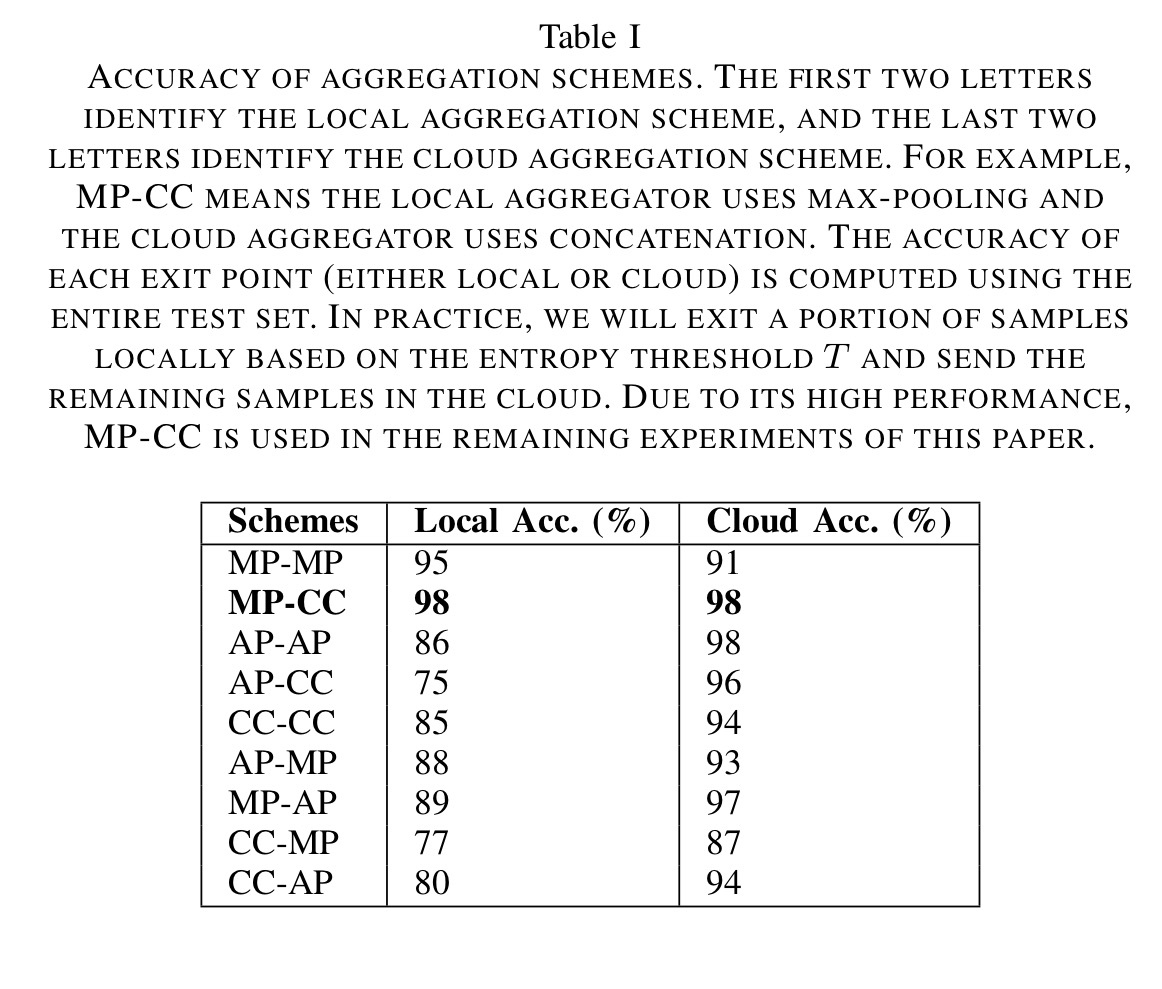
Using CC at the cloud aggregator means that during backpropagation gradients are passed through all devices. Using MP at the local aggregator level forces a relationship between outputs for the same class on multiple devices and improves local accuracy.
The following chart shows what happens when exploring different threshold for local exit.
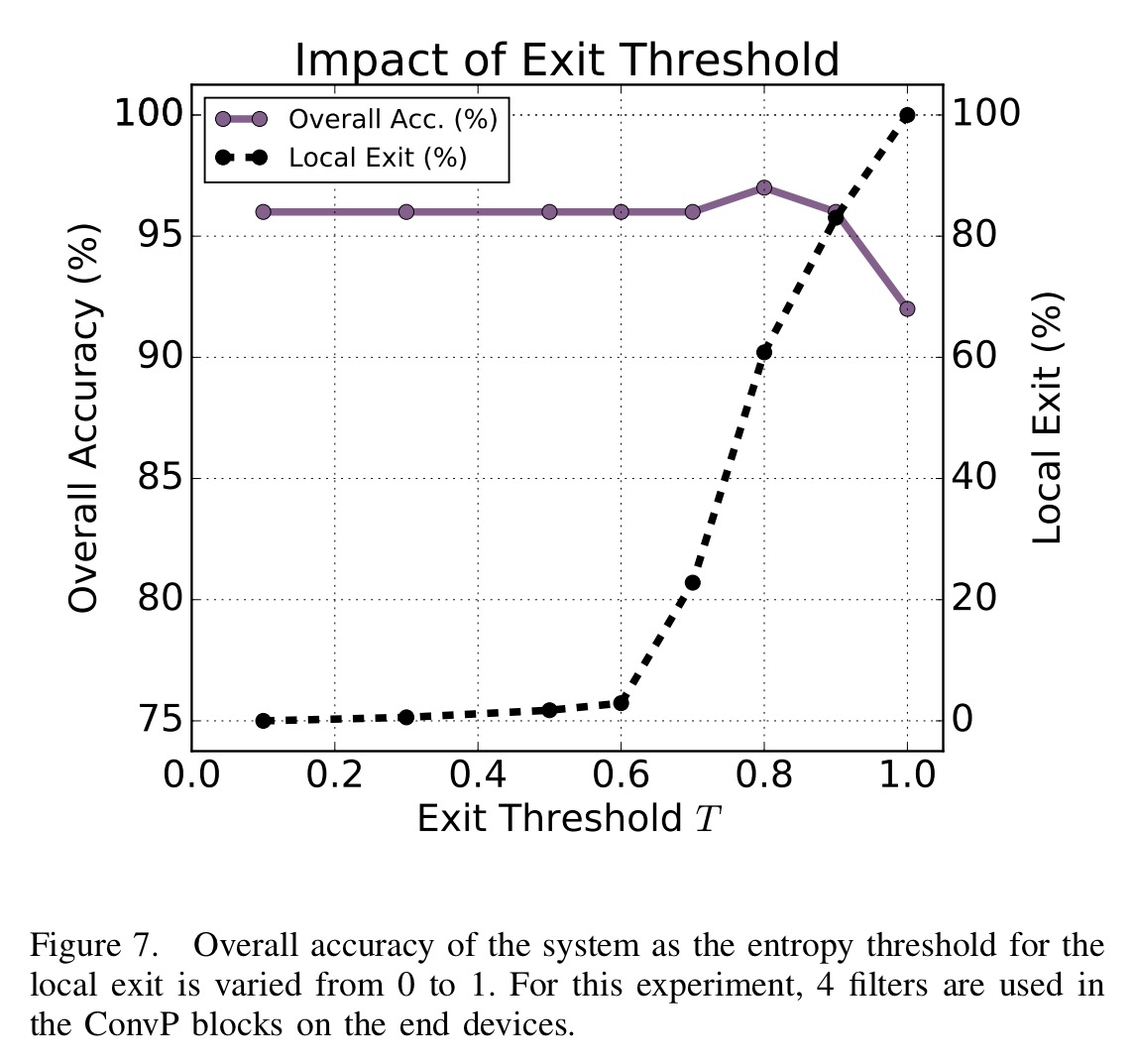
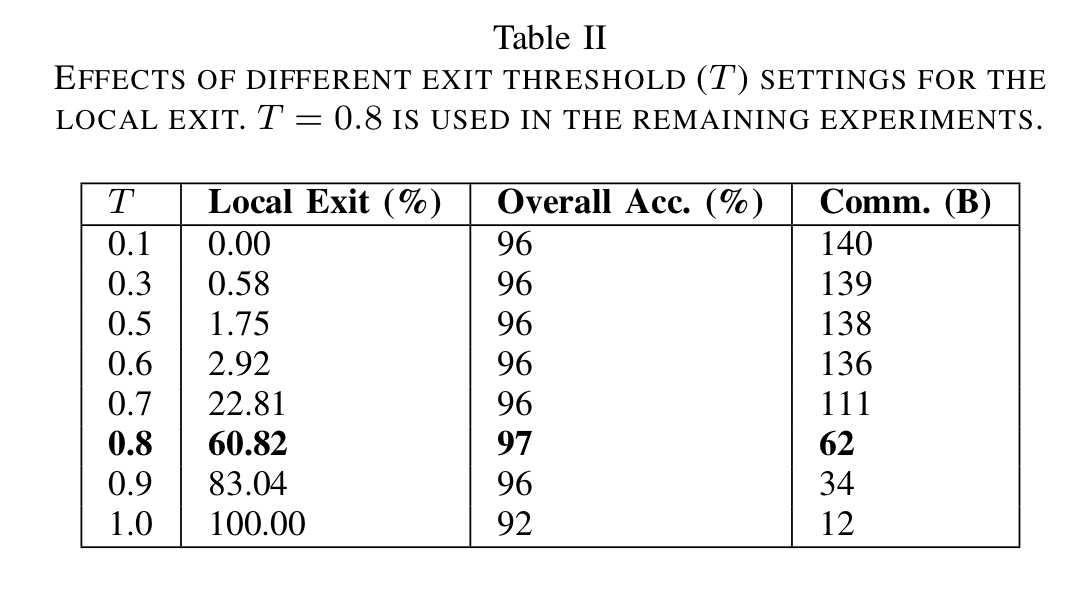
… setting the threshold to 0.8 results in the best overall accuracy with significantly reduced communication, i.e., 97% accuracy while exiting 60.82% of samples locally as shown in the table below.
The next experiment looks at what happens to accuracy as you add more end devices. Devices are added in order from least accurate to most accurate.
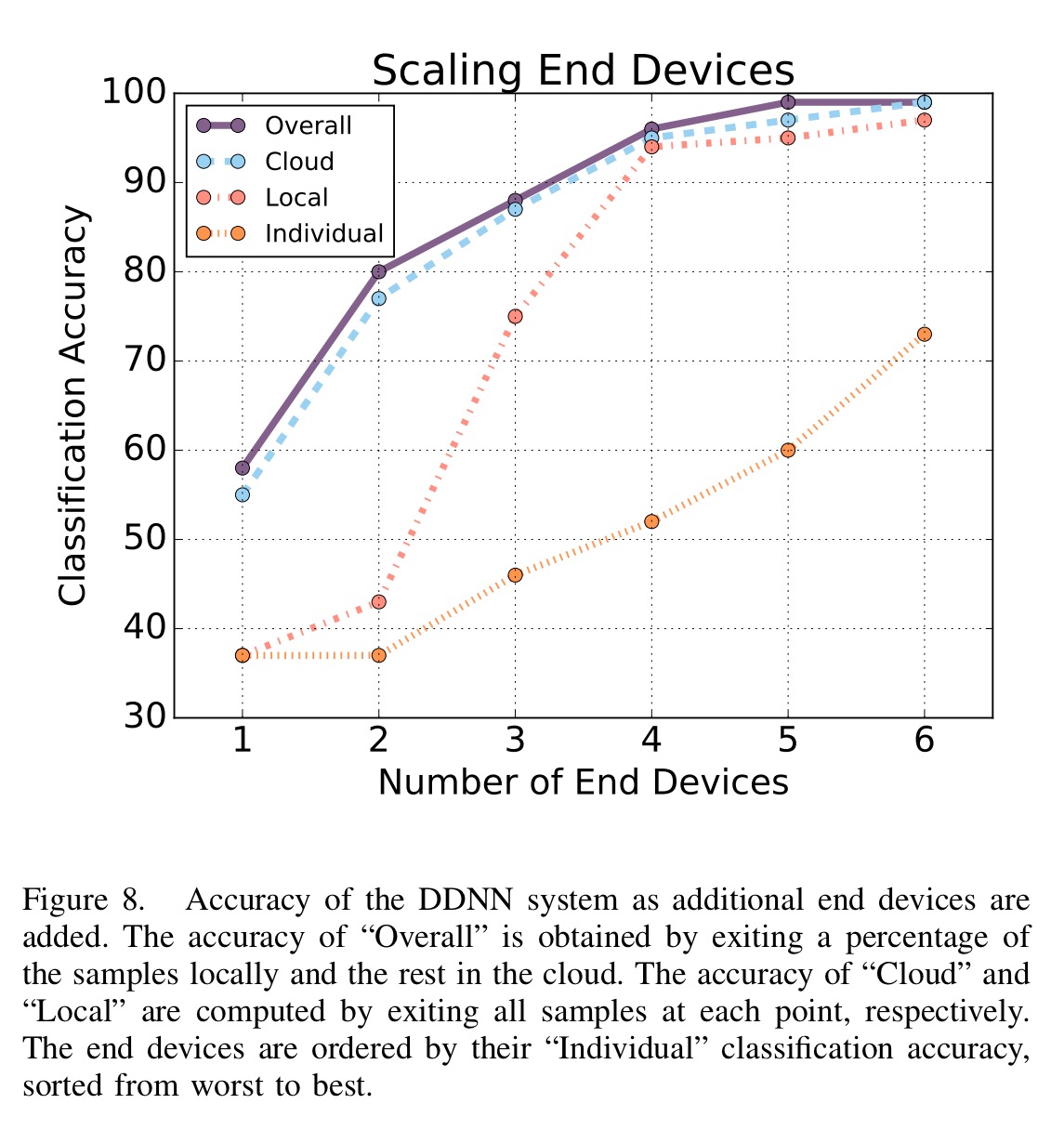
The more devices we add the better it gets, but the cloud exit point always outperforms the local exit point regardless of the number of devices.
Generally these results show that by combining multiple viewpoints we can increase the classification accuracy at both the local and cloud level by a substantial margin when compared to the individual accuracy of any device. The resulting accuracy of the DDNN system is superior to any individual device accuracy by over 20%. Moreover, we note that the 60.82% of samples which exit locally enjoy lowered latency in response time.
One last thing… the authors also test the fault tolerance of the system by simulating end device failures and looking at the resulting accuracy of the system.
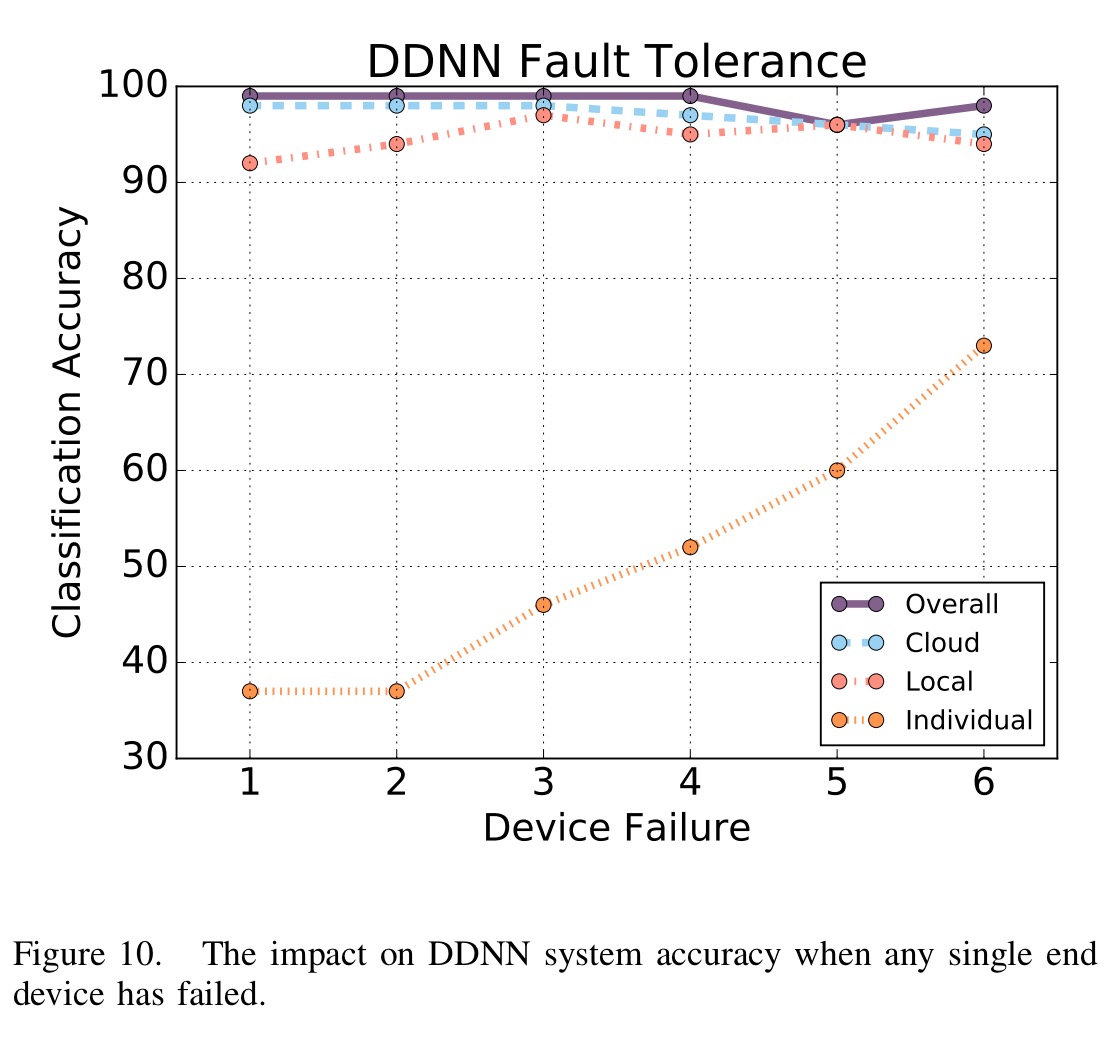
Regardless of the device that is missing, the system still achieves over a 95% overall classification accuracy. Specifically, even when the device with the highest individual accuracy has failed, which is Device 6, the overall accuracy is reduced by only 3%.
At present all layers in the DDNN are binary. Future work includes looking at larger datasets, more end devices, and alternative layer types in the cloud.

Figure 8 seems to be in there twice.
I’d like to understand why there is a suspicious improvement of overall accuracy at 0.8 threshold in Figure 7. Some fine scale experiments at this part of the graph would be interesting.
Finally, in Figure 10, there seems to be coincidence of accuracies when device 5 fails. And poorest accuracy overall. Why? What is special about device 5 — it doesn’t have the most accurate individual classification!
That first figure 8 was supposed to be table II. I just update the post, thanks Steve!
Excellent observation and use of Deep learning..