Adversarial examples for evaluating reading comprehension systems Jia & Liang, EMNLP 2017
We’ve now seen a number of papers investigating adversarial examples for images. In today’s paper choice, Jia and Liang explore adversarial examples for text samples in the context of reading comprehension systems. The results are frankly a bit of a wake-up call for how well those systems really perform. Too much relatively shallow pattern matching, and not enough true depth of understanding.
In the SQuaD reading comprehension task systems are given a paragraph from Wikipedia and have to answer a question about it. The answer is guaranteed to be contained within the paragraph. There are 107,785 such paragraph-question-answer tuples in the dataset. Human performance on this task achieves 91.2% accuracy (F1), and the current state-of-the-art system obtains a respectably close 84.7%. Not so fast though! If we adversarially add a single sentence to those paragraphs, in such a way that the added sentences do not contradict the correct answer, nor do they confuse humans, the accuracy of the published models studied plummets from an average of 75% to just 36%.
For example:

The authors also investigate adversarial models that are not required to add grammatically correct sentences. In the extreme, these adversarial additions reduced accuracy from 80% down to 2.7%!!
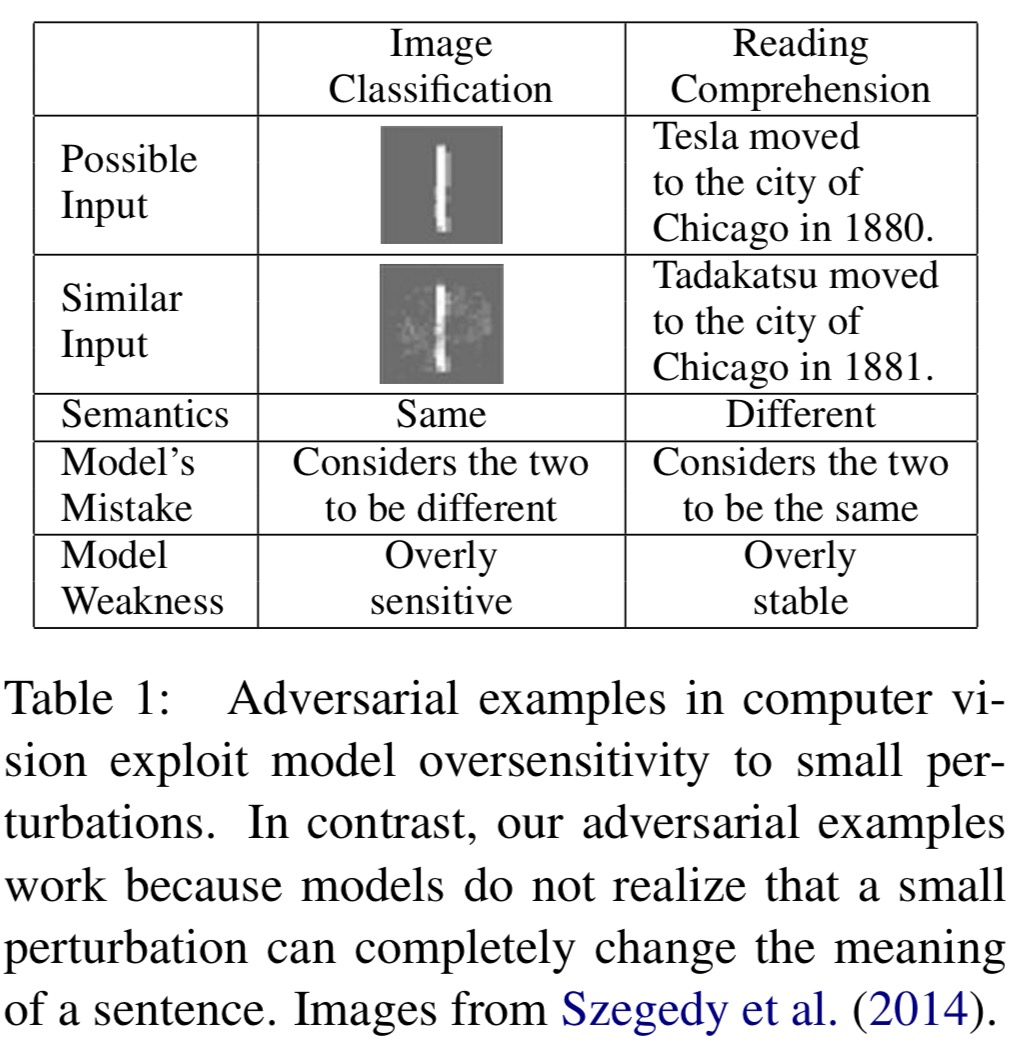
When working with images, adversarial examples exploit model oversensitivity to small perturbations. This causes the model to think that two images which are essentially the same are in fact different classes. In the comprehension setting though we have the opposite problem: models are overly stable and do not realise that a small perturbation can completely change the meaning of a sentence. This causes the model to think that two similar sentences have the same meaning when in fact they actually have different meanings.
Generating adversarial examples for paragraphs
The generation of adversarial examples for reading comprehension needs to be done carefully – changing even one word of a paragraph may drastically alter its meaning. Thus instead of making perturbations to the original text, the authors create examples by adding distracting sentences to the end of the paragraph. These sentences of course have to be generated in such a way that they don’t contradict the correct answer or introduce ambiguity. This goal is achieved in three stages: first a target sentence is generated using rules that make it likely to comply; then the generated sentence is independently edited by five crowdsourced workers to fix any grammatical errors; finally three additional crowdworkers filter out the results of that phase, to leave us with a smaller set of human-approved sentences.
There are two families of adversarial models explored in the paper: AddSent, and AddAny. AddSent starts with the question, mutates it, generates a fake answer to the mutated question and then converts the answer into a statement sentence. AddAny adds d (=10 in the evaluation) words to the end of the paragraph, starting from random seeds, and does not have to generate grammatically correct sentences.
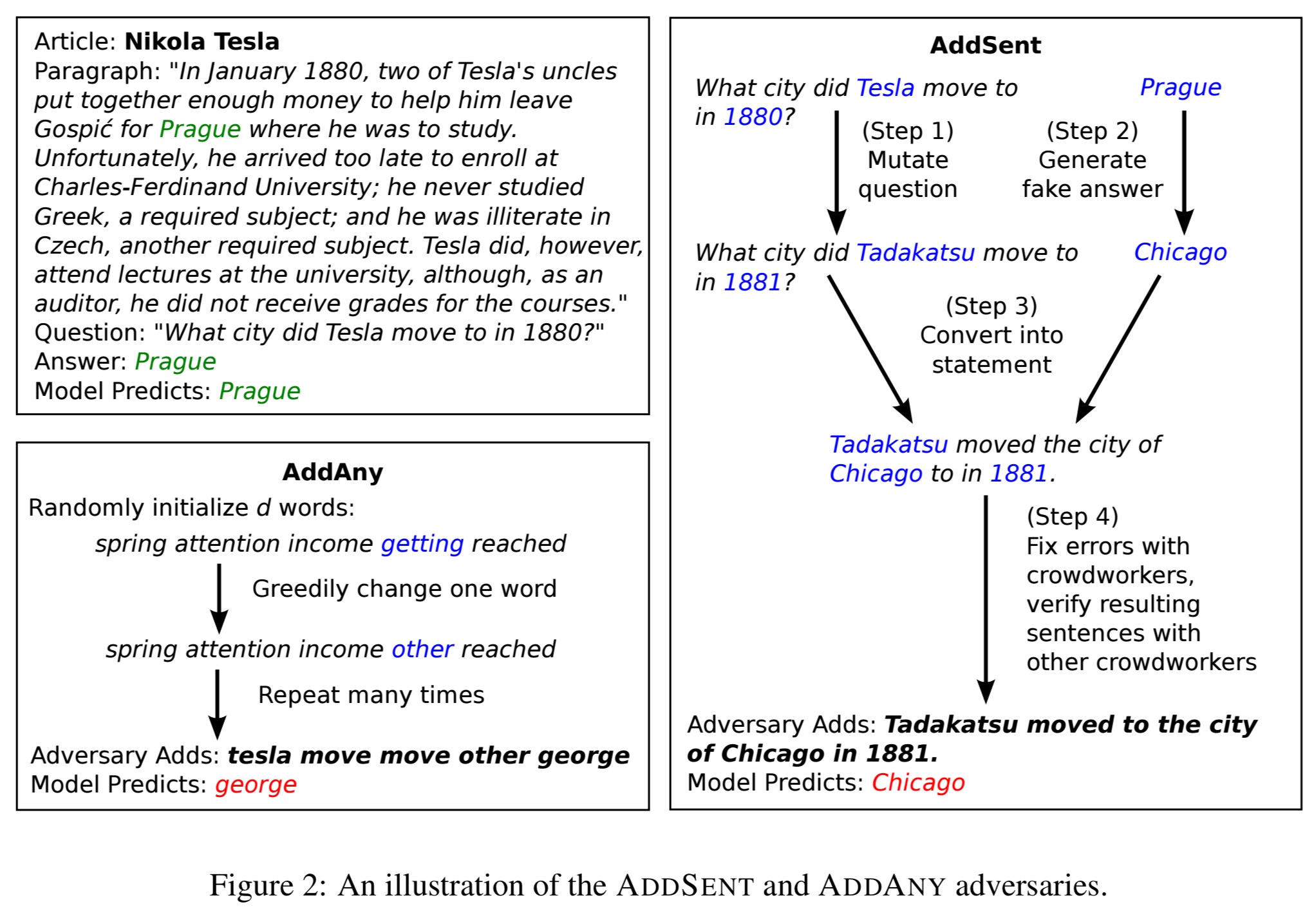
In AddSent, the question is mutated by replacing nouns and adjectives with antonyms from WordNet, and named entities and numbers are changed to the nearest word in a GloVe word vector space (nice use of word vectors!). A fake answer is generated to this new question, that has the same “type” as the original answer: a set of 26 different types are defined corresponding to NER and POS tags from Stanford CoreNLP plus a few custom categories (e.g., abbreviations). Then a set of roughly 50 manually-defined rules are used to combine the altered question and fake answer into a declarative form. These sentences are validated by the crowdworkers, and AddSent tests every sentence that passes this filter against the model. Finally it picks the one that makes the model give worst answer.
Slightly more interesting to me is AddOneSent, which proceeds as above but does not test the final sentences against the model to select the one giving the worst answer, but instead just picks one at random. It generates adversarial examples based solely on the intuition that existing models are overly stable.
The AddAny model starts with a seed set of words selected from randomly sampled common words and all of the words in the question. Over a series of iterations it then tries to build a d=10 word ‘sentence’ by greedily selecting the word for each position in the sentence such that the F1 score over the model’s distribution is minimised. The variant AddCommon works like AddAny but does not use any words from the question, it just draws from common words (the 1000 most frequent words in the Brown corpus).
Evaluating models against adversaries
The adversarial models were developed and tested against two published deep learning model architectures: BiDAF and Match-LSTM. Each model has a single and an ensemble version. Under adversarial examination, this is what happened:
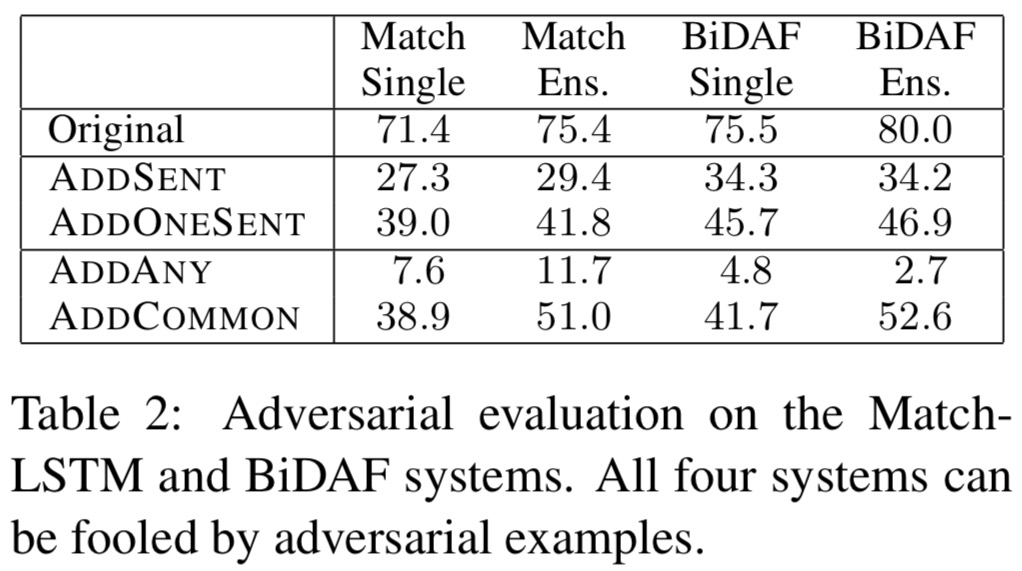
Each model incurred a significant accuracy drop under every form of adversarial evaluation.
Notably, AddOneSent does nearly as well as AddSent, despite being model independent.
The authors then verified that the adversaries were general enough to fool models not used during development, running AddSent on twelve additional published models. They didn’t do too well either!
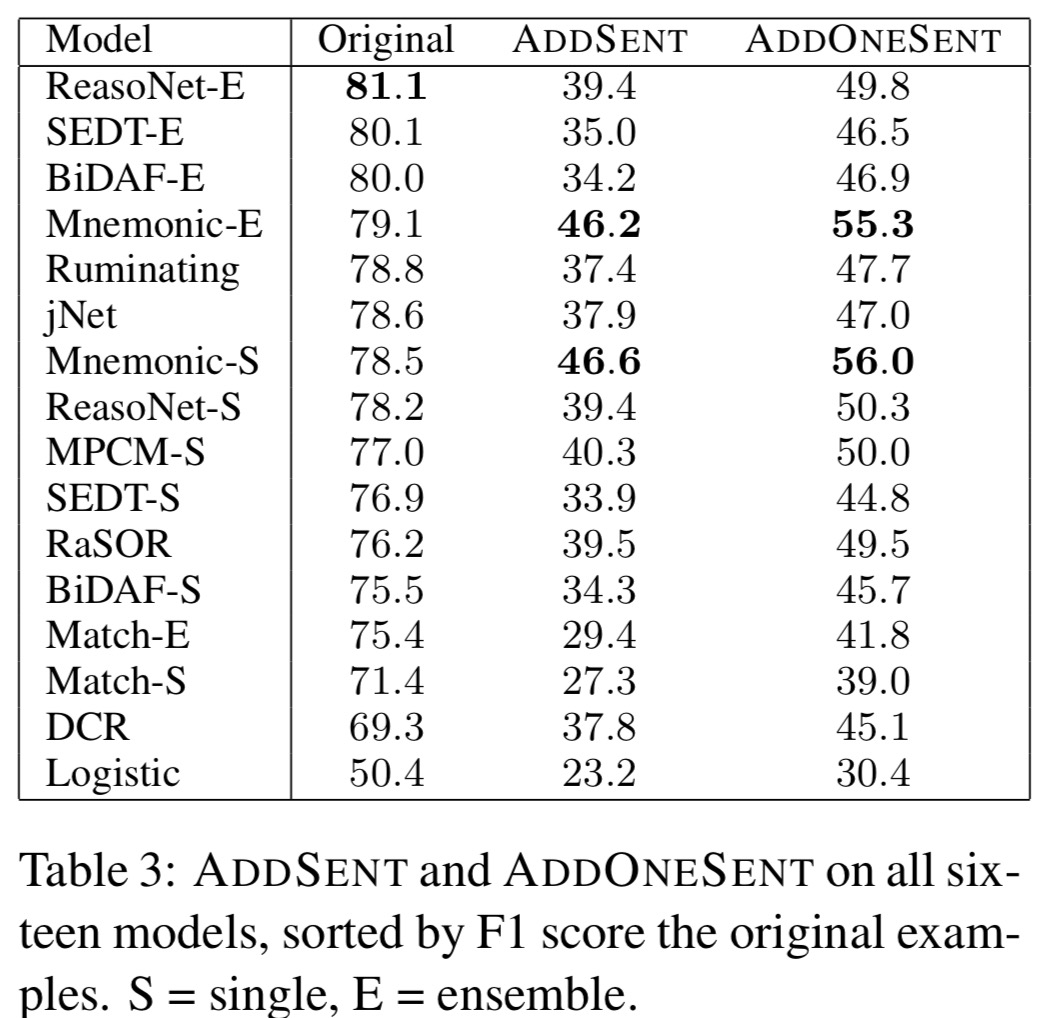
…no model was robust to adversarial evaluation; across the sixteen total models tested, average F1 score fell from 75.4% to 36.4% under AddSent.
To make sure the results are valid, the authors also verified that humans are not fooled by the adversarial examples. Short version: human accuracy only drops a small amount, nothing like the drop seen by the models.
A look at what went wrong…
Using AddSent, the authors conducted an investigation into why the models were getting confused. In 96.6% of model failures, the model predicted a span (i.e., a part of) the adversarial sentence. Looking at the sentences generated by AddSent for 100 of the BiDAF Ensemble failures, in 75 of them an entity name was changed, in 17 cases numbers or dates were changed, and in 33 cases an antonym of a question word was used. (Generated sentences can have changes in more than one category).
Conversely, when the models proved robust to a particular adversarial sentence, it was often the case that the question had an exact n-gram match with the answer in the original paragraph.
… 41.5% of BiDAF Ensemble successes had a 4-gram in common with the original paragraph, compared to only 21.0% of model failures.
Models also did comparatively better with short questions…
This effect arises because AddSent always changes at least one word in the question. For long questions, changing one word leaves many others unchanged, so the adversarial sentence still has many words in common with the question. For short questions, changing one content word may be enough to make the adversarial sentence completely irrelevant.
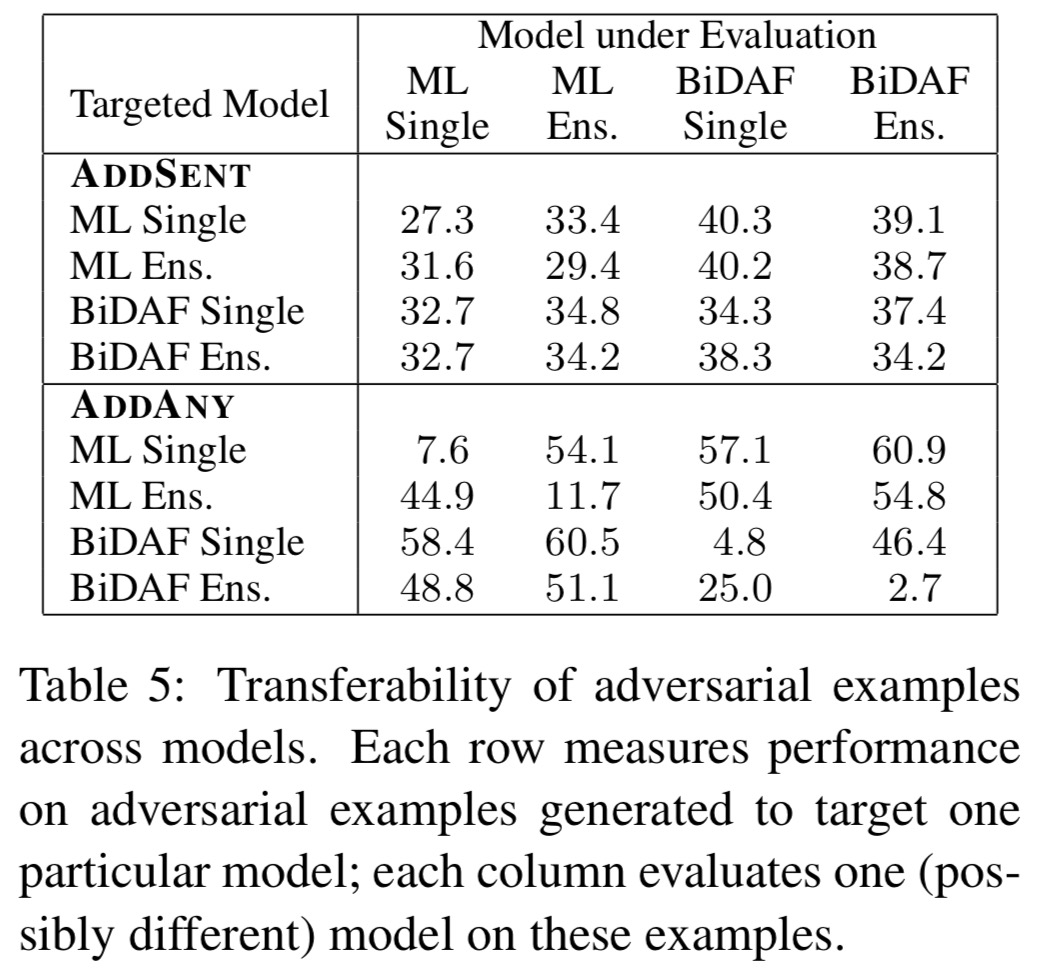
Transferability and fine-tuning
Similarly to images where adversarial examples that fool one model tend to fool others, the authors investigated the same effect with AddSent. (Note that the AddOneSent examples clearly do transfer, because they are model-independent to start with). AddSent examples transfer between models quite effectively, and the fact that they remain harder than AddOneSent examples implies that examples that fool one model are more likely to fool others.
Attempting fine-tuning by training on adversarial examples appears on the surface to have much more benefit than it does in the image case, bringing accuracy back up from 34.8% to 70.4%, close to the original 75.8% accuracy. However, a variant using a different set of fake answers and adding the sentence at the start sent the accuracy rate plummeting again.
The retrained model does almost as badly as the original one on AddSentMod, suggesting that it has just learned to ignore the last sentence and reject the fake answers that AddSent usually proposed…
What now for reading comprehension systems?
Existing models appear successful on the surface, but when probed with adversarial examples their weaknesses quickly show.
Standard evaluation is overly lenient on models that rely on superficial cues. In contrast, adversarial evaluation reveals that existing models are overly stable to perturbations that alter semantics. To optimize adversarial evaluation metrics, we may need new strategies for training models.
Progress on building systems that truly understand language is only possible when the evaluation metrics can distinguish real intelligent behaviour from shallow pattern matching. To assist with this, the authors have released scripts and code for AddSent and AddAny on the CodaLab platform at https://worksheets.codalab.org/worksheets/0xc86d3ebe69a3427d91f9aaa63f7d1e7d/.

Are you aware of any other reading comprehension system, possibly working by building a knowledge base and updating it with new knowledge?
Computationally expensive as this may be, it could still be the best way to achieve true understanding and perform inference.
I’m also thinking about implementing the cognitive domain of the Bloom’s Taxonomy, assuming a strong NLP system has already been achieved.
Are you aware of any other reading comprehension system, possibly working by building a knowledge base and updating it with new knowledge?
At http://ai.neocities.org/EnParser.html one finds the rudiments of the conceptual Perl Ghost AI natural-language comprehension system based on NLP in English and in Russian. The ghost.pl AI comprehends simple Subject-Verb-Object inputs and also prepositional phrases and detection of indirect versus direct objects.
You probably saw this one too “Hacking Voice Assistant Systems with Inaudible Voice Commands”:
https://www.schneier.com/blog/archives/2017/09/hacking_voice_a.html
Also, thank you for this awesome blog!
That’s a really fun one isn’t it! I never cease to be amazed at the ingenuity of hackers.
Maybe the confusions are way too similar to the original sentences after all though. One thing to always consider is that human beings possess much more background knowledge than the systems trained. If they had that much more background knowledge to realize that jersey number and age can definitely not be the same, or that Tadakatsu and Tesla, though looking similar, must be different people (since they also know all the background knowledge about what Tesla actually did etc.), then their performance could naturally get much better.