Adding concurrency to smart contracts Dickerson et al., PODC’17
Yesterday we looked at how analogies from concurrent objects could help us understand smart contract behaviour. In today’s paper choice from PODC’17 (which also has one Maurice Herlihy on the author list) we get to borrow some ideas from concurrent objects to increase the concurrency of smart contracts.
Back in 2008 Herlihy & Koskinen published a paper on ‘Transactional boosting: a methodology for highly-concurrent transactional objects.‘ In the context of software transactional memory (STM), transactional boosting showed how to transform highly-concurrent base objects implemented without any notion of transactions into equally concurrent transaction objects that can safely be used with STM. Taking some ideas from transaction boosting, …
… This paper presents a novel way to permit miners and validators to execute smart contracts in parallel, based on techniques adapted from software transactional memory. Miners execute smart contracts speculatively in parallel, allowing non-conflicting contracts to proceed concurrently, and “discovering” a serialized concurrent schedule for a block’s transactions.
Why do we want more concurrency?
When a miner creates a block, includes a sequence of transactions, computing the new state for the transactions’ smart contracts serially, in the order in which they appear in the block. If the block is subsequently successfully appended to the blockchain, that block’s transactions are re-executed by every node to confirm that the state transitions were computed honestly and correctly.
To summarize, a transaction is executed in two contexts: once by miners before attempting to append a block to the blockchain, and many times afterward by validators checking that each block in the blockchain is honest. In both contexts, each block’s transactions are executed sequentially in block order.
Miners are rewarded for blocks that they successfully append to the blockchain, so they have an incentive to increase throughput by parallelizing smart contract executions. But simply executing contracts in parallel without any special precautions won’t work as the contracts may perform conflicting accesses to shared data leading to an inconsistent final state. Validators on the other hand end up performing the vast majority of contract executions and parallel execution here could bring significant benefits if it could be done safely.
Speculative smart contracts
We’ve seen previously that writing bug free smart contracts is hard.
Clearly, even sequential smart contracts must be written with care, and introducing explicit concurrency to contract programming languages would only make the situation worse. We conclude that concurrent smart contract executions must be serializable: indistinguishable, except for execution time, from a sequential execution.
Smart contracts read and modify shared storage, and they are written in Turing-complete languages – so it is impossible in the general case to determine statically whether or not contracts have data conflicts. Instead, contracts can be instrumented to detect synchronization conflicts at runtime, in a manner similar to that done in transaction boosting. Contracts are executed speculatively, and if a conflict does occur at runtime the conflict is resolved either by delaying one contract until the other completes, or rolling back and restarting one of the conflicting executions.
Speculation is controlled by two run-time mechanism, invisible to the programmer, and managed by the virtual-machine: abstract locks and inverse logs.
Storage operations are protected by abstract locks. If two storage operations map to distinct locks, then they must commute. Or to put it another way, operations that don’t commute must be protected by the same lock. It wasn’t clear to me from reading the paper whether this mapping of operations to locks can be performed automatically, or whether it requires human intervention. Before executing the operation, a thread must acquire the associated lock. When the lock is acquired, it records an inverse operation in a log (think undo log), and then proceeds with the operation.
If the action commits, its abstract locks are released and its log is discarded. If the action aborts, the inverse log is replayed, most recent operations first, to undo the effects of that speculative action. When the replay is complete, the actions’ abstract locks are released. The advantage of combining abstract locks with inverse logs is that the virtual machine can support very fine-grained concurrency.
If one contract calls another, a nested speculative action is created.
At the end of this process, the miner will have discovered a concurrent schedule for a block’s transactions, that is equivalent to some sequential schedule, only faster.
Validation
So far so good for the miners, but not so great for the validators. The problem is that the validators need to produce the same or an equivalent schedule of execution to that discovered by the miner. The solution is for miners to produce and publish extra information concerning the constraints discovered during execution. Why would miners make this available?
… that block [produced by the miner] may be competing with other blocks produced at the same time, and the miner will be rewarded only if the other miners choose to build on that block. Publishing a block with a parallel validation schedule makes the block more attractive for validation by other miners.
Here’s how it works:
- Each lock includes a use counter keeping track of the number of times it has been released by a committing action during the construction of the current block.
- When a speculative action commits, it increments the counters for each of the locks it holds, and registers a lock profile with the VM recording the abstract locks and their counter values.
- When all the actions have committed, the common schedule can be reconstructed by comparing lock profiles. It is these profiles that the miner includes in the blockchain along with the usual information.
For example, consider three committed speculative actions, A, B, and C. If A and B have no abstract locks in common, they can run concurrently. If an abstract lock has counter value 1 in A’s profile and 2 in C’s profile, then C must be scheduled after A.
Using the algorithm below, a validator can construct a simple fork-join program that deterministically reproduces the miner’s original speculative schedule. Using a work-stealing scheduler, the validator can exploit whatever degree of parallelism it has available.

The validator keeps a thread-local trace of the abstract locks each thread would have acquired. If these traces don’t match the lock profiles provided by the miner the block is rejected.
Is it safe?
Correctness is argued by appeal to the analogy with transactional boosting, where serial equivalence has been proven.
Experimental results
The authors built an implementation based on the JVM for experimental purposes, using the Scala STM library for speculative action execution.
Examples of smart contracts were translated from Solidity into Scala, the modified to use the concurrency libraries. Each function from the Solidy contract is turned into a speculative transaction by wrapping its contents with a ScalaSTM atomic section. Solidity mapping objects are implemented as boosted hashtables, where key values are used to index abstract locks.
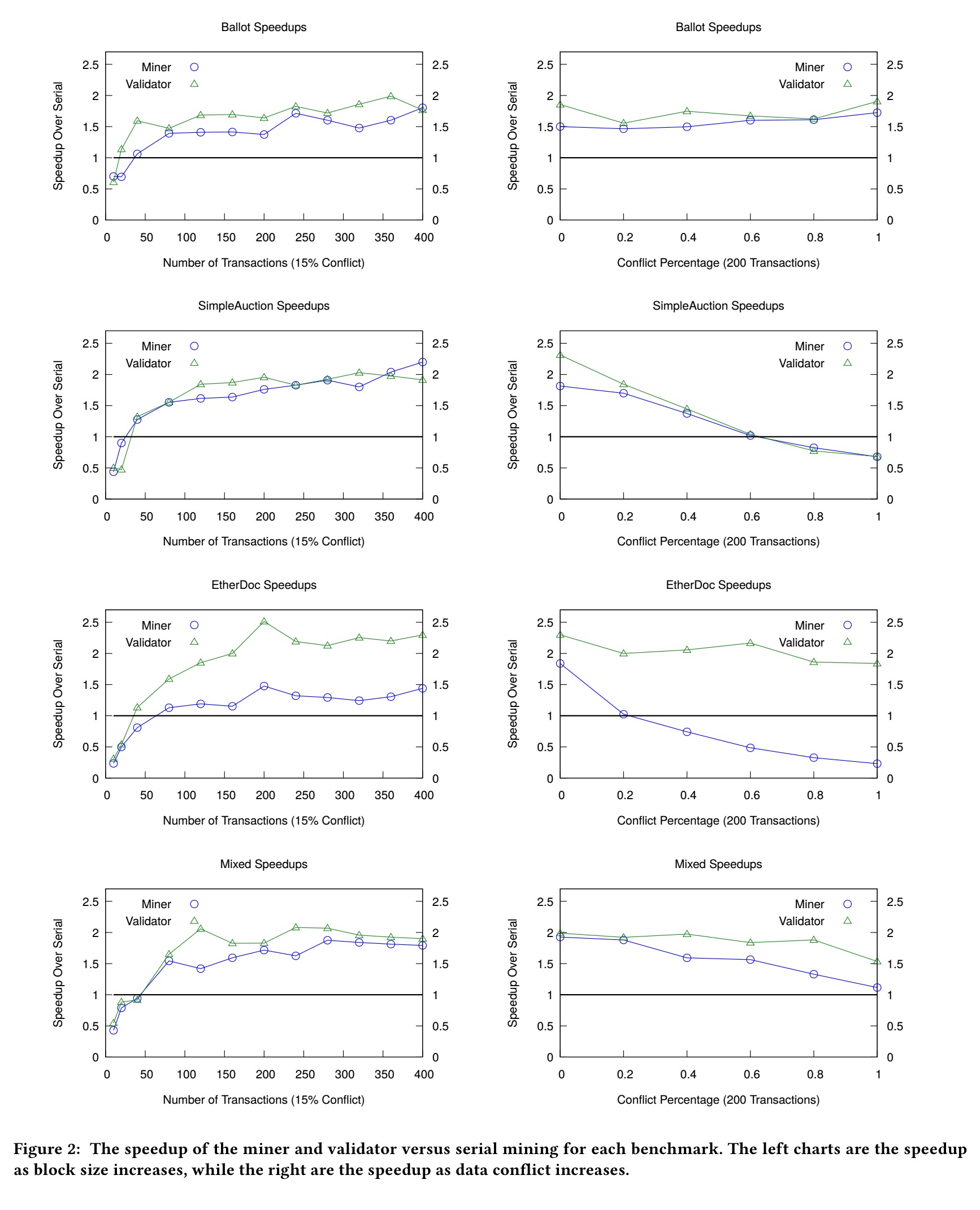
The benchmarks are based on Ballot, SimpleAuction, and EtherDoc contracts, as well as a workload mixing all three. The experiments used only three concurrent threads, but this was still sufficient to show a benefit:

The charts below give more detail of the speedups obtained at different conflict levels.
Our proposal for miners only is compatible with current smart contract systems such as Ethereum, but our overall proposal is not, because it requires including scheduling metadata in blocks and incentivizing miners to publish their parallel schedules. It may well be compatible with a future “soft fork” (backward compatible change), a subject for future research.

Reblogged this on Paul Gazzillo's Blog.
“It wasn’t clear to me from reading the paper whether this mapping of operations to locks can be performed automatically, or whether it requires human intervention. ”
In the implementation section, the paper mentions that in their prototype, these locks “are implemented via interfaces exported by ScalaSTM, relying on ScalaSTM’s native deadlock detection and resolution mechanisms.”
So, I guess ScalaSTM does it for you. Pretty convenient, huh!