Complete Event Trend detection in high-rate event streams Poppe et al., SIGMOD’17
Today’s paper choice looks at the tricky problem of detecting Complete Event Trends (CET) in high-rate event streams. CET detection is useful in fraud detection, health care analytics, stock trend analytics and other similar scenarios looking for complex patterns in event streams. Detecting CETs efficiently is hard because there’s exponential complexity everywhere you look! The authors lead us to a neat solution that minimises CPU costs given a memory budget, and achieves speed-ups of up to 42x compared to the state-of-the-art.
We’ll start out with some background looking at examples of CET queries, the difficulty of finding CETs, and a baseline algorithm for detecting them. Following that, we’ll look at the CET graph data structure introduced by the authors, and how to optimally partition the graph to balance CPU and memory requirements. Finally we’ll dip into the evaluation to get a sense for how well it all works.
There’s quite a a lot to cover so this post is a little longer than my usual target length.
What is a Complete Event Trend (CET)
[CET] event sequences have arbitrary, statically unknown, and potentially unbounded length.
You know you’re looking at a CET query if it is expressed using a Kleene closure. Queries have the form:
PATTERN P [WHERE preds] WITHIN l SLIDE s
- P is an event pattern: a time-ordered sequence of one Kleene closure pattern and any number of event types.
- l is the sliding window length
- the window slides every s time units
We’re in desperate need of an example! Consider the check kiting use case. Fraudsters write a check against some account A, for an amount greater than the balance. To cover this, they write a check from account B, also with insufficient funds, that pays into account A. You can construct complex chains in this way, taking advantage of float facilities to extract money before the banks can detect what is happening.
Complex versions of this scheme have occurred involving multiple fraudsters posing as large businesses, thereby masking their activity as normal business transactions. This way they coax banks to waive the limit of available funds. To implement this scheme, fraudsters transfer millions among banks, using complex webs of worthless checks. As just one example, in 2014, 12 people were charged in a large-scale “bustout” scheme, costing banks over $15 million.
Here’s a CET query to detect check kiting:

The Kleene closure part is the Check+ c[] pattern that matches check deposit events. Q1 finds chains (or circles) of any length formed by notcovered check deposits during a time window of 1 day that slides every 10 minutes.
To prevent cash withdrawal from an account that is involved in at least one check kiting scheme, the query continuously analyzes high-rate event streams with thousands of financial transactions per second and detects all complete check kiting trends in real time.
The paper contains a couple of other examples, a query looking for doubling heart rates in the absence of physical activity, and a query looking for stock markets trends (in this case, steady increase):


Why is finding CETs hard
Each individual CET is of “unknown and potentially unbounded length” (strictly, it’s bounded by the maximum number of events the system can see within the query window?), but the bigger problem is that the number of CETs is proven to be exponential in the number of relevant events in the worst case ($3^{n/3}$ for 
Given this, and the occurrence of many common event sub-sequences, solutions tend to use either lots of CPU in constantly recomputing CETs, or lots of memory to store partial CETs during detection. The search space for finding an optimal divide-and-conquer partitioning is also exponential!
A baseline algorithm
The overall problem we want to solve is this: given a CET query q, a high-rate stream I, and available memory M, we want to detect all CETs matched by the query q in the stream I while minimising the CPU costs and staying within the memory limit M.
The baseline algorithm simply finds CETs and returns them at the end of the query window, without worrying about memory budgets or CPU optimisation. It maintains a list of event trends seen so far during the window, and at the end of the window, it throws away any incomplete trends, and returns all the complete ones. There are three cases for each incoming event e that can be matched by the query pattern:
- If e is compatible with an existing CET trend tr, it is appended to it.
- If e is not compatible with an existing CTE trend tr, but is compatible with a prefix of it, then a new CET is created by appending e to the prefix
- If e is not compatible with any existing trend or prefix, then a new CET is started.
It’s straightforward, but unfortunately it has exponential CPU and memory costs (proof in Appendix A): shared event sequences are replicated (memory), and each new event needs to be compared to every CET discovered so far (CPU).
Introducing the CET graph data structure
The baseline algorithm is inefficient because it does not take common event sequences in CETs into account. To tackle this problem, we propose a compact data structure called a CET graph.
Let the nodes in the graph represent events, and edges connecting events represent adjacency in a CET. Thus any path in the graph from a node with no incoming edges (first event) to a node with no outgoing edges, corresponds to one CET.
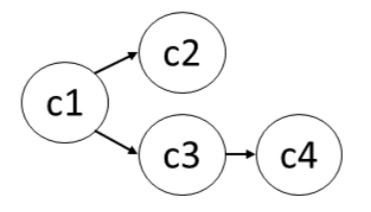
If we take the baseline algorithm and have it build a CET graph instead of maintaining a set of all in-flight CETs, we can get things down to ‘just’ quadratic CPU and memory costs in the number of events.
Given a graph that has been built at the end of a window, we want to extract all the CETs from it. If we do this using a breadth first search then we get a CPU time optimal algorithm (T-CET), since all CETs found so far are stored during the traversal and no backtracking is necessary. If on the other hand we extract CETs using a depth first search then we get a memory optimal algorithm (M-CET) as only one current CET is maintained during the traversal, but we spend extra CPU on backtracking.
Recall that our goal is to to achieve minimal CPU usage for a certain memory budget. If only we could somehow use a combination of depth first and breadth first search to meet that end…
Partitioning the graph
To achieve our goal of minimizing the CPU costs without running out of memory, our CET optimizer partitions the CET graph into smaller graphlets. Based on the partitioned graph, we now propose the H-CET algorithm that exploits the best of both M-CET and T-CET approaches in a divide-and-conquer fashion.
H-CET uses breadth-first-search (T-CET) within each graph partition or graphlet, which results in a set of partial CETs. These are kept in memory and stitched together to yield the final result.
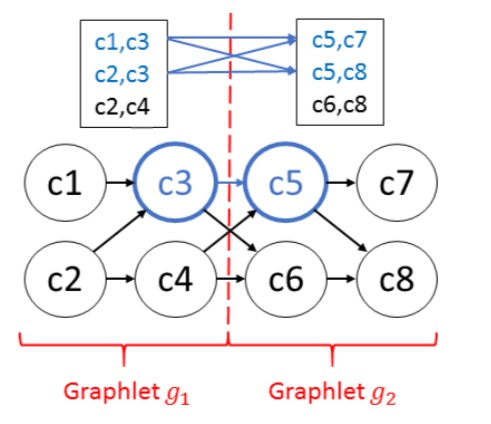
The smaller the graphlets, the fewer CETs per graphlet are computed and stored, but the higher the CPU overhead of constructing the final CETs from these partial results becomes.
The overall memory cost is exponential in the number of events per graphlet, not the number of events per query query window. “This can result in several orders of magnitude reduction for high-rate event streams.”
The following table summarises the memory and CPU costs of T-CET, M-CET and H-CET:

There’s just one small problem. How do we figure out the best way to partition the CET graph?
Generally, the size of the search space is exponential, described by the Bell number which represents the number of different partitions of a set of elements. Thus, streaming graph partitioning is an NP-hard problem.
Fortunately we can apply a few constraints to dramatically simplify the search space, by only considering effective partitioning plans. An effective partitioning plan is one the respects the order of events in a CET so that a graphlet only needs to be visited once in order to construct one final CET.
…we partition the CET graph into non-overlapping consecutive time intervals. All events within a time interval are assigned to the same graphlet (similar to Chunking). Since consecutive time intervals contain consecutive sub-sequences of CETs, a time-centric partitioning plan is guaranteed to be effective. The search space remains exponential, however, now in the number of time intervals, not in the number of events in the window. This results in a substantial reduction for high-rate event streams in which multiple events fall into the same time interval.
Applying the effective filter leaves us with just the partitioning plans indicated by rectangles in the following figure to consider:
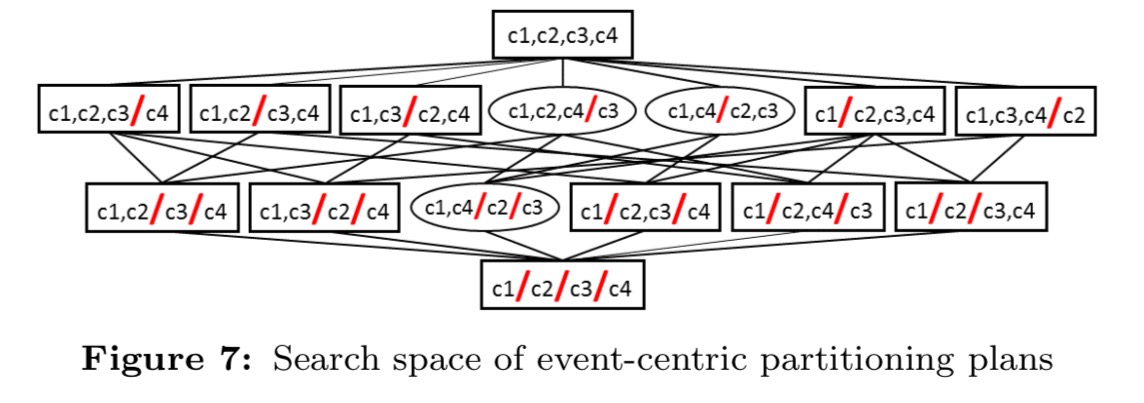
Note that the partitioning plans sit in a hierarchy: at the top level we gave only on graphlet with all events in it, and the bottom node has as many graphlets as there are events. Every time we drop down a layer, we reduce the memory requirement, and increase the CPU requirement. So we can traverse the search space top down until we find the first level with a partitioning plan that fits into the memory budget. Within that level, we choose the most CPU efficient partitioning.
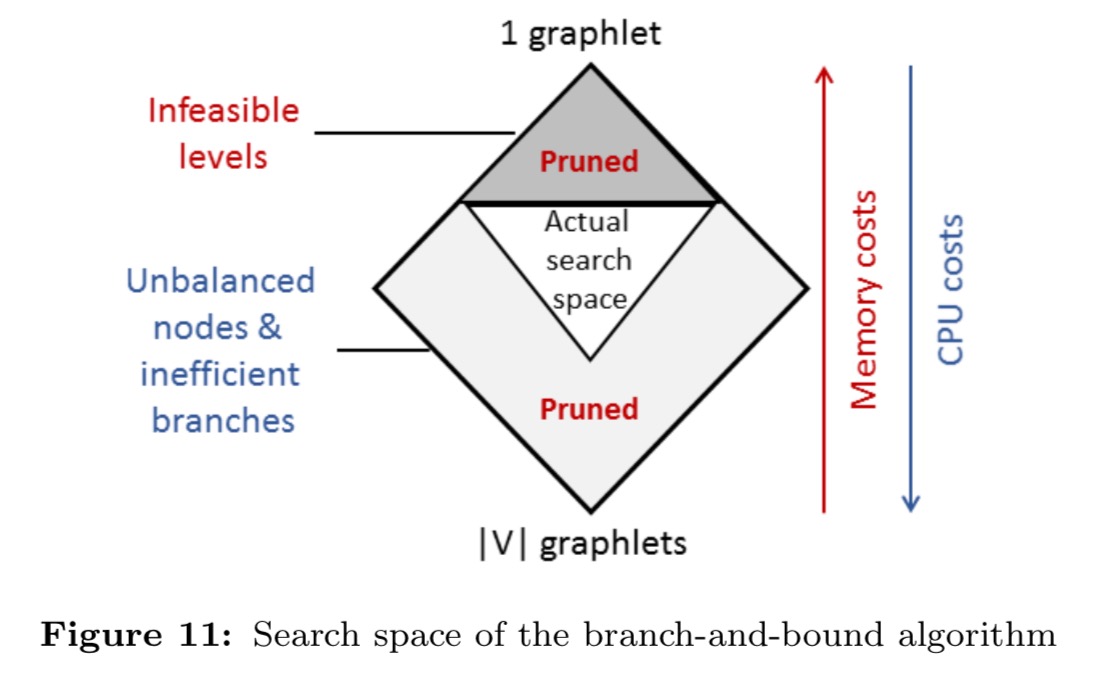
Even when working within one level though,…
The number of partitioning plans at one level of the search space is exponential, described by the Stirling number that represents the number of ways to partition n elements into k partitions.
An ideal balanced plan would have each partition contain the same number of events plus or minus one. “The closer a partitioned CET graph is to balanced, the lower the CPU and memory costs of CET detection are.” Instead of finding the optimal balanced partitioning, a greedy algorithm examines the first nearly balanced partitioning it finds within a level. If this satisfies the memory constraint it is returned, otherwise we drop down to the next level. This strategy has constant memory cost and O(k) CPU complexity with k graphlets.
Graphlet sharing
When the window slides, graphlets that can span windows are shared across overlapping windows such that repeated partitioning and traversals can be avoided.
Experiments
A workload of 10 CET queries (variations of the examples we saw earlier) is evaluated over three different data sets: physical activity, stock data, and financial transaction data. The efficiency of H-CET is compared to the baseline algorithm, as well as to SAFE++, a state-of-the-art system supporting Kleene closure computation, and to an implementation in Apache Flink (official Kleene operator support is coming in the next Flink release, and its performance may differ from the authors’ implementation here).
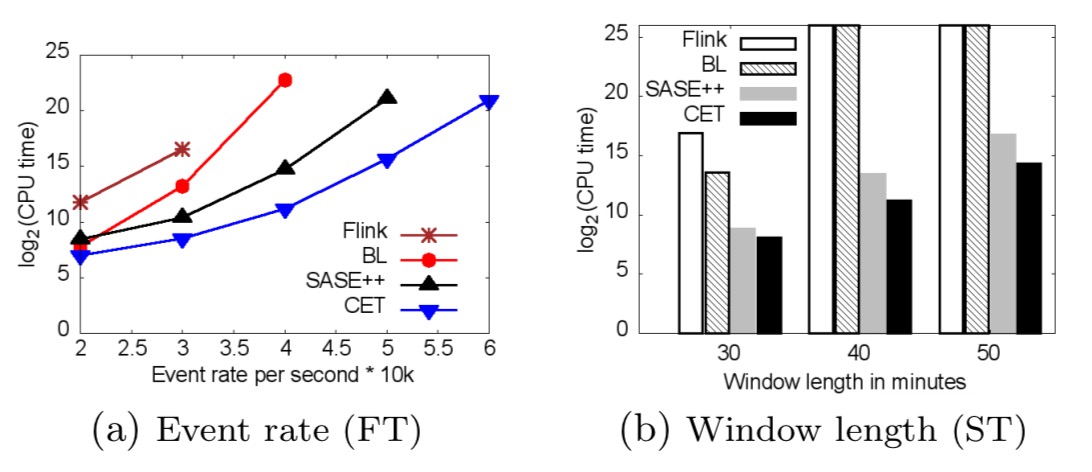
CPU costs of all approaches grow exponentially with an increasing stream rate and window length (Figures 13(a)–13(b) below). For large numbers of events per window, Flink, BL, and SASE++ do not terminate within several hours. These approaches do not scale because they construct all CETs from scratch – provoking repeated computations. In contrast, our CET approach stores partial CETs and reuses them while constructing final CETs. Thus, CET is 42–fold faster than SASE++ if stream rate is 50k events per second and 2 orders of magnitude faster than Flink if stream rate is 3k events per second. Flink is even slower than BL in all experiments because Flink expresses each Kleene query as a set of event sequence queries. Thus, the workload of Flink is considerably higher than other approaches tailored for Kleene computation.
For a more detailed analysis, see section 7 in the paper.
To the best of our knowledge, we are the first to guarantee optimal CPU time of complete event trend detection over high-rate event streams given limited memory.

6 thoughts on “Complete event trend detection in high-rate data streams”
Comments are closed.