Twitter Heron: Towards extensible streaming engines Fu et al., ICDE 2017
We previously looked at the initial Twitter Heron paper that announced Heron to the world. In this ICDE 2017 paper, the team give us an update based on the work done since as a result of open-sourcing Heron.
… we discuss the challenges we faced when transforming Heron from a system tailored for Twitter’s applications and software stack to a system using an extensible, modular architecture which provides flexibility to adapt to various environments and applications.
We get a high level look at the architecture and an investigation into its performance (short version: having a modular architecture doesn’t mean you have to sacrifice performance). The part I find the most interesting though is the comparisons between Twitter Heron’s design and those of Storm and Spark Streaming. (Would be great to see Apache Flink included as well).
Twitter’s daily operations rely heavily on real-time processing of billions of event per day… Heron is now the de facto stream data processing system in Twitter and is used to support various types of applications such as spam detection, real time machine learning, and real time analytics, among others.
Why a modular architecture?
Moving Heron from an internal project to an open source project meant that Heron could no longer be tied to any element of Twitter’s stack. To be externally useful to a broad audience, it needs to consider different environments (public/private cloud), a variety of software stacks, and diverse application workloads. A good example here is Twitter’s use of Aurora for scheduling, whereas many other organisations may already have an alternate scheduler (e.g., YARN).
Heron allows the application developer or system administrator to create a new implementation for a specific Heron module and plug it into the system without disrupting the remaining modules or the communication between them.
The structure also allows different applications built on top of Heron to use different module implementations while operating on the same underlying resources.
The high-level architecture of Heron
Heron’s architecture is inspired by that of microkernel-based operating systems… due to the heterogeneity of today’s cloud environments and Big Data platforms, we decided to design Heron using extensible self-contained modules that operate on top of a kernel which provides the basic functionality needed to build a streaming engine.
There are seven main modules, as shown in the following figure:
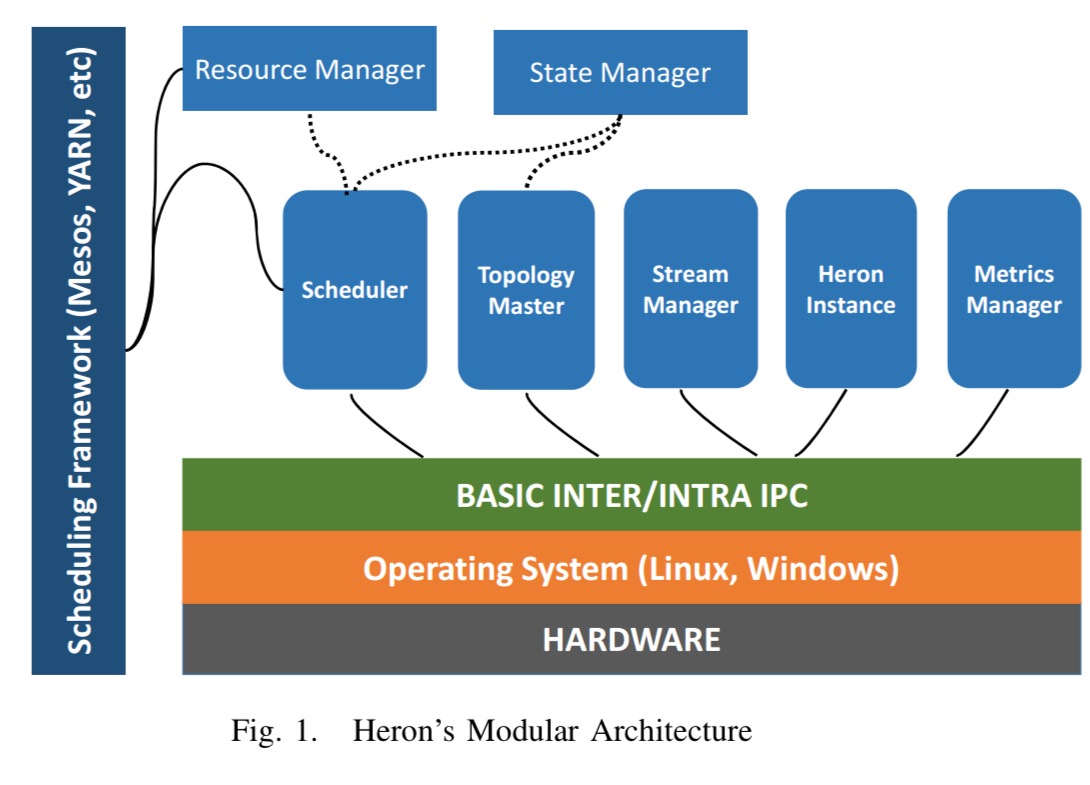
At runtime, everything is container-based.
Heron Instances are essentially the spouts or bolts that run on their own JVM. The Metrics Manager collects process metrics, and the Topology Master manages the directed graph of spouts and bolts (a topology). Let’s now take a look at the remaining modules in more detail.
Resource Manager
The resource manager is invoked on demand to manage resource assignments (CPU, memory, disk) for a particular topology. It does this by assigning Heron Instances to containers through a packing plan. An initial packing plan is created when a topology is first submitted, and can be repacked in response to user requests to scale up and down.

Different resource management policies can be selected for the different topologies running on the same cluster.
A generated packing plan is passed to the Scheduler.
Scheduler
The Scheduler module interacts with an underlying scheduling framework such as YARN or Aurora to allocate the resources needed by a packing plan. Heron accommodates both stateful and stateless schedulers, depending on the level of support provided by the underlying scheduling framework.
A stateful
Schedulerregularly communicates with the underlying scheduling framework to monitor the state of the containers of the topology. In case a container has failed, the statefulSchedulertakes the necessary actions to recover from failure… A statelessScheduleron the other hand, is not aware of the state of the containers while the topology is running. More specifically, it relies on the underlying scheduling framework to detect container failures and take the necessary actions to resolve them.
Heron today has support for Aurora and YARN. A Mesos scheduler is being developed in the community.
State Manager
The State Manager is used for distributed coordination and storing topology metadata. It stores for example topology definitions, packing plans, host and port information for all containers, and the location of the underlying scheduling framework. Heron provides a ZooKeeper based implementation, as well as a local file system version for local development and testing.
Stream Manager
The Stream Manager handles all inter-process communication. It’s implemented in C++ to provide tighter control over the memory and CPU footprint, and to avoid copying data between the native and JVM heaps.
The Stream Manager uses several techniques to achieve high performance:
- Protocol Buffers are allocated in memory pools and reused, avoiding new/delete operations
- In-place updates of Protocol Buffers are performed
- Lazy deserialization is used whenever possible
The communication layer offers two important configuration parameters to tune its behaviour for a given deployment: max spout pending determines the maximum number of tuple that can be pending on a spout task at any point in time, and cache drain frequency determines how often the tuple cache is drained. The tuple cache store incoming and outgoing data tuples before routing them to the appropriate Heron Instances.
Heron vs Storm
Heron is designed with the goal of operating in a cloud environment on top of a scheduling framework such as Aurora or YARN (although it can also run in local mode). As a result, it leverages the resource isolation mechanisms implemented by these frameworks. Storm, on the other hand implements parts of the functionality of the Heron
Resource Manager, the HeronSchedulerand the underlying scheduling framework in the same abstraction.
In Storm, this creates confusion between Storm’s scheduling decisions and those of any underlying scheduler. Furthermore, in Storm all resources for a cluster must be obtained up front, whereas Heron acquires resources on demand. Thus Storm clusters will tend to be over-provisioned.
Heron provides resource isolation between topologies (through the underlying scheduling framework), and also between processes of the same topology. Storm can do neither – it packs multiple spout and bolt tasks into a single executor, and several executors share the same JVM.
Finally, Heron’s Stream Manager handles all data transfers separately from processing units, which helps to make the system scalable. Storm shares communication threads and processing threads in the same JVM. “As a result, it is much harder to isolate performance bottlenecks and thus optimize the overall performance.”
Heron vs Spark Streaming
Spark Streaming depends on Spark itself for extensibility. Because Spark supports a wide diversity of use cases, it is not easy to customize it particularly for streaming.
It is worth noting that Spark (and, as a result, Spark Streaming) has a similar architecture to Storm that limits the resource isolation guarantees it can provide… each executor process can run multiple tasks in different threads. As opposed to Heron, this model does not provide resource isolation among the tasks that are assigned to the same executor.
All Spark Streaming communication relies on Spark, and is not customisable.
Performance evaluation
If we compare Heron and Storm on a workload chosen to expose framework overheads we see that Heron beats storm on both throughput and latency:
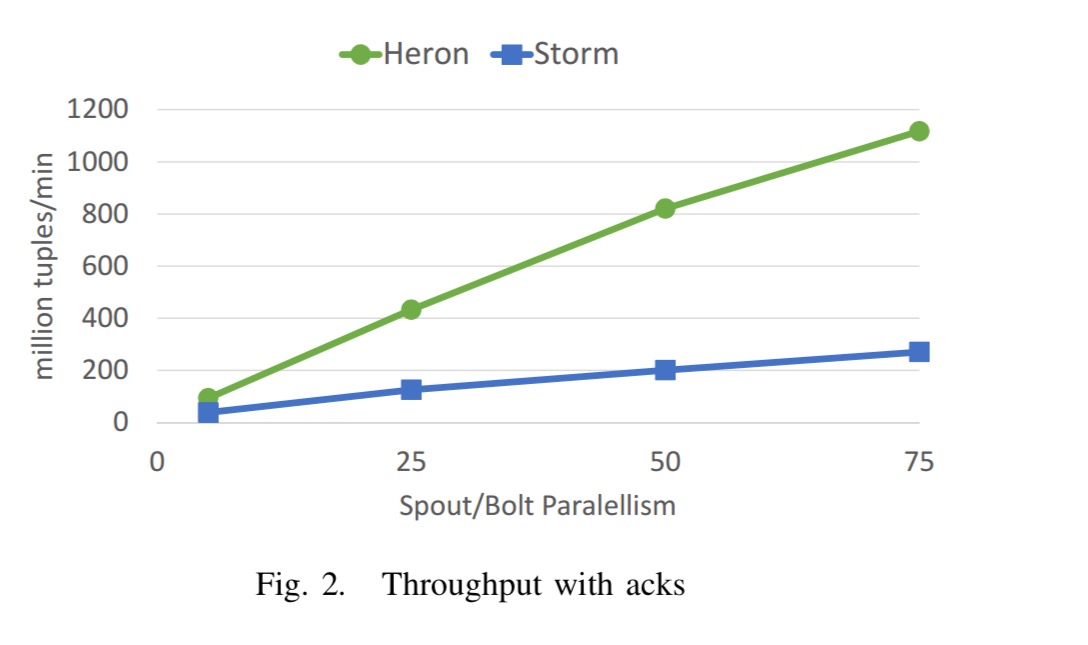
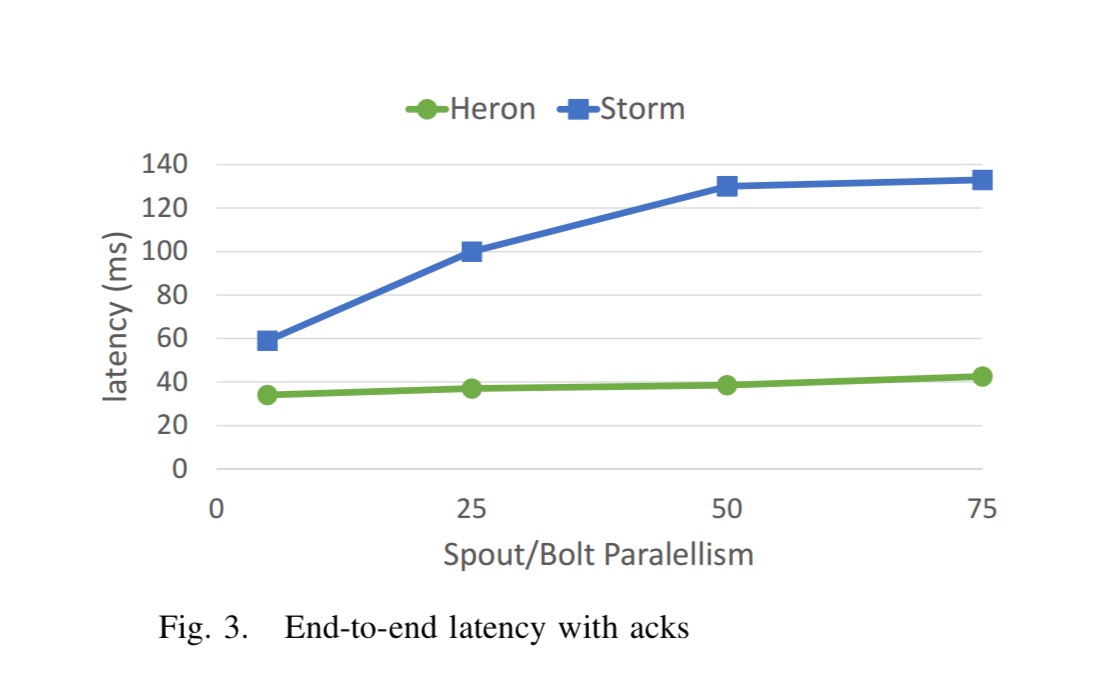
The above figures are with acks enabled.
Heron outperforms Storm by approximately 3-5x in terms of throughput and at the same time has 2-4x lower latency.
With acks disabled, the throughput of Heron is 2-3x higher than Storm’s.
The following two charts show the impact of the max spout pending configuration parameter. As you might expect, allowing more queuing tasks increases throughput up to a point, at the expense of latency.
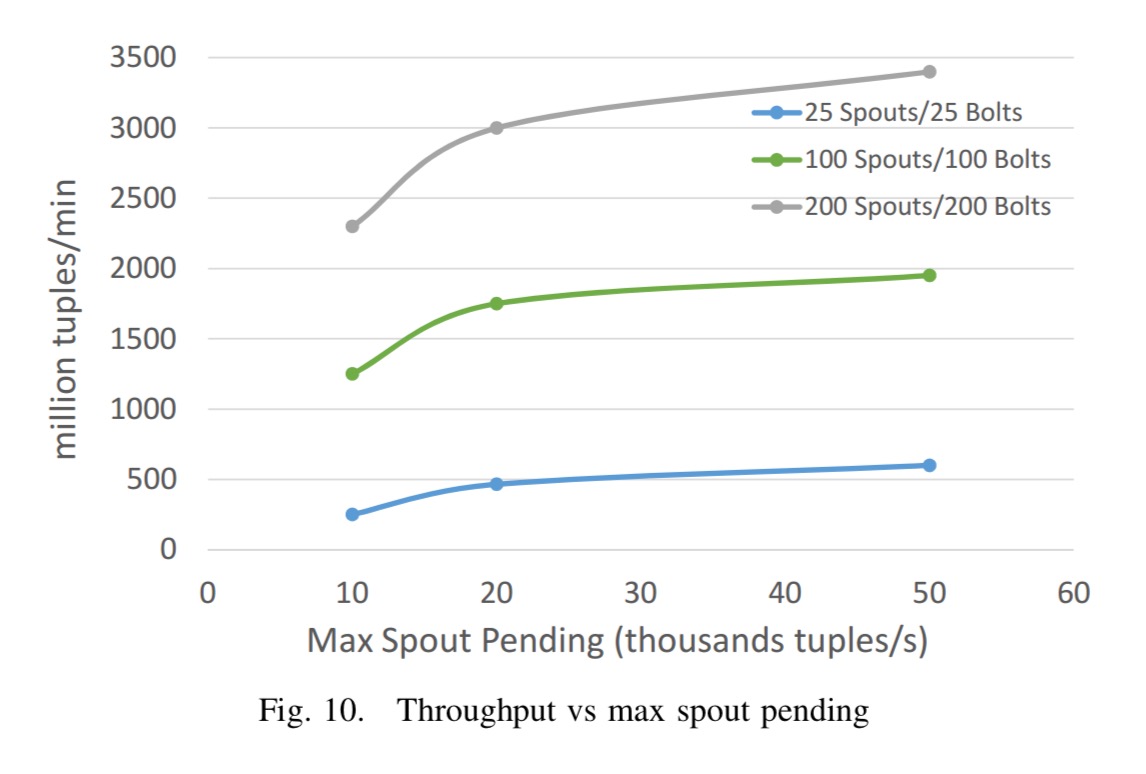
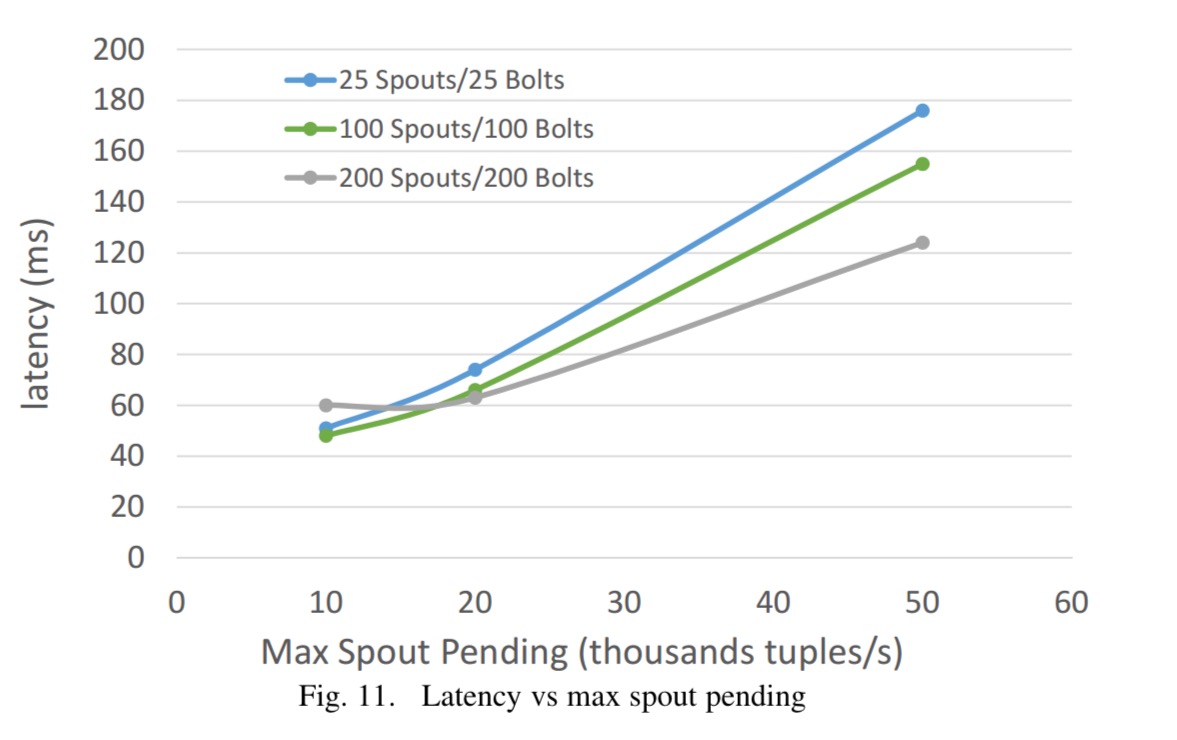
See section V in the paper for a more detailed performance breakdown.
Despite the benefits of general-purpose architectures, such as Heron’s modular architecture, a common belief is that specialized solutions tend to outperform general-purpose ones because they are optimized for particular environments and applications. In this paper, we show that by carefully optimizing core components of the system, Heron’s general-purpose architecture can actually provide better performance than specialized solutions such as Storm.

The post says: “Heron today has support for Aurora and YARN. A Mesos scheduler is being developed in the community.”
Aurora actually is a scheduler that runs on top of Mesos. Do you mean that a scheduler is being developed that allows Heron to run directly on top of Mesos (ie a “Mesos framework”, like Aurora)?
Yes, this is a directly-on-Mesos w/out Aurora piece of work. Details at https://twitter.github.io/heron/docs/operators/deployment/schedulers/mesos/
Heron supports more schedulers now – Native Mesos, DC/OS, Mesos/Aurora, Slurm and YARN.
https://github.com/twitter/heron/tree/master/heron/schedulers/src/java/com/twitter/heron/scheduler