SoK: Cryptographically proctected database search Fuller et al., IEEE Security and Privacy 2017
This is a survey paper (Systematization of Knowledge, SoK) reviewing the current state of protected database search (encrypted databases). As such, it packs a lot of information into a relatively small space.
As we’ve seen before, there are a wide-variety of cryptographic techniques in play (LIST), and we’re seeing the increasing emergence of commercial solutions:
In the commercial space, a number of established and startup companies offer products with protected search functionality, including Bitglass, Ciphercloud, CipherQuery, Crypteron, IQrypt, Kryptnostic, Google’s Encrypted BigQuery, Microsoft’s SQL Server 2016, Azure SQL Database, PreVeil, Skyhigh, StealthMine, and ZeroDB. While not all commercial systems have undergone thorough security analysis, their core ideas come from published work. For this reason, this paper focuses on systems with a published description.
I’m going to start by jumping to the heart of the paper (for me at least), which looks at the different mechanisms for protected base queries, and their strengths and weaknesses
Approaches to protected search
The section provides systematic reviews of the different cryptographic approaches used across query types and an evaluation of known attacks against them. Due to length limitations, we focus on the Pareto frontier of schemes providing the currently best available combinations of functionality, performance, and security.
To give you an idea where we’re heading, here’s the big summary table, with schemes grouped by query type (equality, boolean, range, or other).

(Click for larger view)
After query type, the schemes are broken down by the primary approach that they take to protection: legacy, custom, oblivious, or other.
Legacy compliant schemes
Legacy schemes insert ciphertexts into a traditional database, without changing the indexing and querying mechanisms. Such schemes are based on property-preserving encryption which produces ciphertexts preserving some property (e.g., equality and/or ordering) of the underlying plaintexts. “As a result, Legacy schemes immediately inherit decades of advances and optimizations in database management systems.” As we saw a couple of weeks ago though, in practice implementations based on existing database engines may leak a lot more than the cryptographic theory taken on its own would lead you to believe.
Within the legacy bucket, deterministic encryption (DET) preserves only equality but applying a randomized but fixed permutation to all messages. Even without a querier making any queries though, the server learns everything about equalities between data items. Order-preserving encryption (OPE) preserves the relative order of the plaintexts, so that range queries can be performed over ciphertexts:
This approach requires no changes to a traditional database, but comes at the cost of quite significant leakage: roughly, in addition to revealing the order of data items, it also leaks the upper half of the bits of each message.
Mutable OPE only reveals the order of ciphertexts at the expense of added interactivity during insertion and query execution. Legacy approaches can be extended to perform boolean queries and joins by combining the results of equality or range queries.
Even the strongest legacy schemes reveal substantial information about queries and data to a dedicated attacker.
Custom schemes
Custom schemes include inverted indices and tree traversal. Inverted index schemes traditionally supported equality searches on single table databases via a reverse lookup mapping each keyword to a list of identifiers for database records containing the keywords. OSPIR-OXT extends this to support boolean queries using a second index. Other inverted index schemes have been introduced to support selection, projection, and Cartesian product at the expense of additional leakage.
Cash and Tessaro demonstrate that secure inverted indices must necessarily be slower than their insecure counterparts, requiring extra storage space, several non-local read requests, or large overall information transfer.
Tree traversal schemes execute queries by traversing a tree and returning the leaf nodes at which the query terminates (sort of). The main challenge is to hide the traversal pattern through the tree. Tree-based schemes have also been developed that can support range queries.
Oblivious schemes
Oblivious schemes aim to hide common results between queries. Oblivious RAM (ORAM) has been researched for decades, and the performance of ORAM schemes has steadily increased, with the Path ORAM scheme being a current favourite.
Applying ORAM techniques to protected search is still challenging.
Of interest here is 3PC-ORAM which shows that by adding a second non-colluding server you can build an ORAM scheme which is much simpler than previous constructions.
Other schemes
There have been several custom schemes supporting other query types such as ranking boolean query results, calculating inner products of fixed vectors, and computing the shortest distance on a graph.
These schemes mostly work by building encrypted indices out of specialized data structures for performing the specific query computation.
Oh, you want to update the data as well???
Not all secure schemes support updating the data, especially those in the custom and oblivious categories. Most legacy schemes allow immediate queries after insertion. For custom schemes that do support updates, new values are typically inserted into a less efficient side index. Periodically a refresh operation updates the main database structures to include these updates – this is expensive though so it can’t be done too frequently.
Attacks
Now that we’ve got a basic map of the territory, let’s take a look at the leakage inference attacks the different schemes are vulnerable too. There’s another big table for those too:
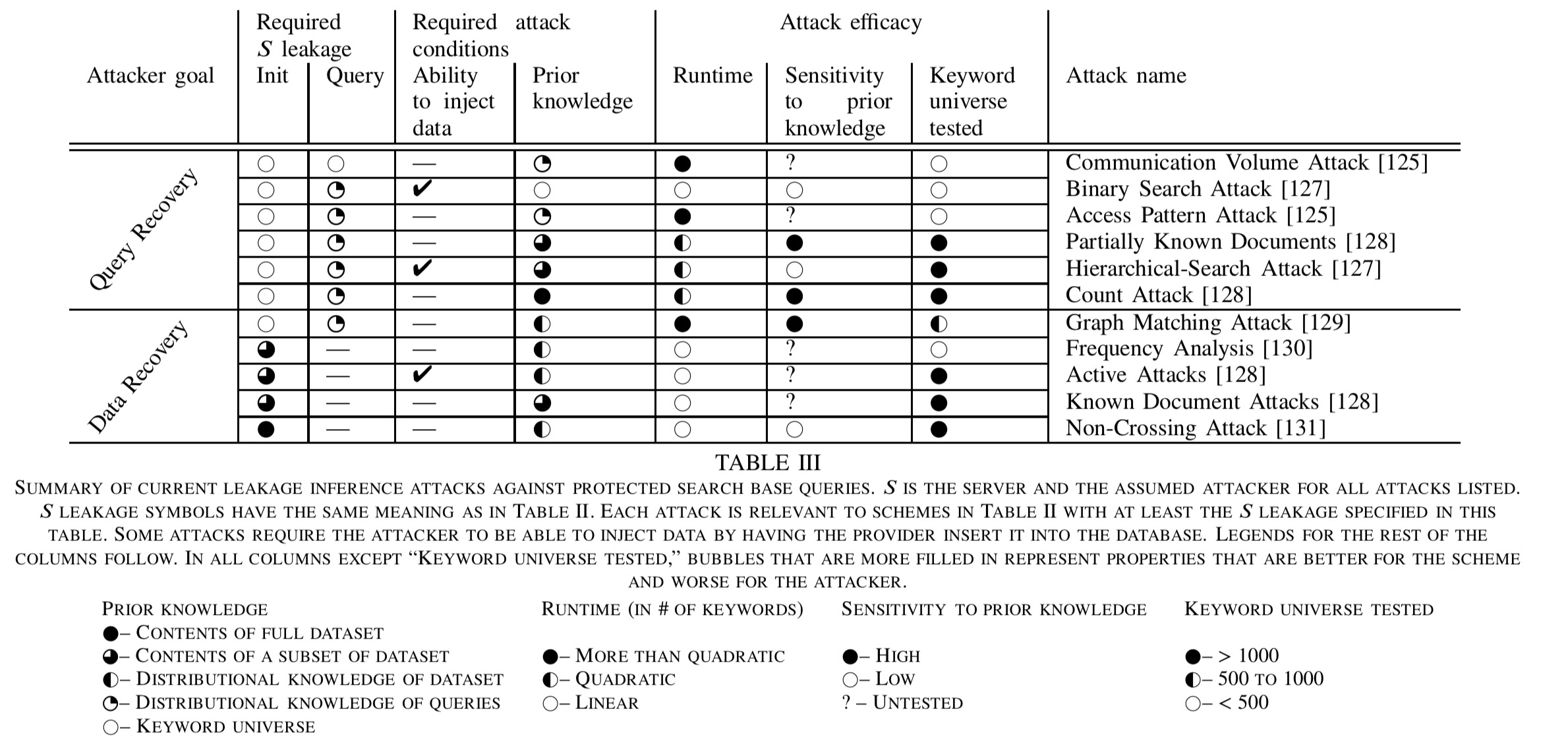
(Click for larger view).
From the first ‘schemes’ table that we looked at, take the ‘S leakage’ (server leakage) column and then look up the values there in this table to find out which schemes are vulnerable to which attacks.
We stress that leakage inference is a new and rapidly evolving field. As a consequence, the attacks in Table III only cover a subset of leakage profiles included in Table II. Additionally, this section merely provides lower bounds on the impact of leakage because attacks only improve over time.
Attacks are divided into two broad groups depending on whether the attacker is trying to recover data stored at the server (data recovery), or to learn the set of queries asked by a user (query recovery).
The required leakage columns tell you what kind of information leakage the attack depends on. ‘Init’ here means that some data is leaked during the initial loading of the data, without any queries being made, and ‘Query’ refers to information leakage during querying.
Examples include the cardinality of a response set, the ordering of records in the database, and identifiers of the returned records. Some attacks require leakage on the entire dataset while others only require leakage on query responses
All current attacks require some prior knowledge – information about the stored data or the queries made. The prior knowledge column indicates how much an attacker needs to know. Some attacks also require the attacker to be able to insert records.
The attack efficacy columns give an idea of runtime required, amount of prior knowledge, and how large a keyword universe the different attacks can deal with.
Most of the attacks rely on the following two facts: 1) different keywords are associated with different numbers of records, and 2) most systems reveal keyword identifiers for a record either at rest (e.g, DET) or when it is returned across multiple queries.
The assumed attacker models for inference attacks are also fairly weak: there is the semi-honest attacker who follows protocols but tries to learn as much additional information as they can from what they observe, and an attacker capable of data injection (i.e., they can take some action that ultimately ends up in a record being updated in the database).
The authors identify the follow open problem, which seems to be saying “it’s an open problem to find real world use-cases where the known leakage attacks don’t matter!”
… it is important to understand what these leakage attacks mean in real-world application scenarios. Specifically, is it possible to identify appropriate real-world use-cases where the known leakage attacks do not disclose too much information? Understanding this will enable solutions that better span the security, performance, and functionality tradeoff space.
Full database solutions
The following table summaries protected search systems that have made the transition to full database solutions.
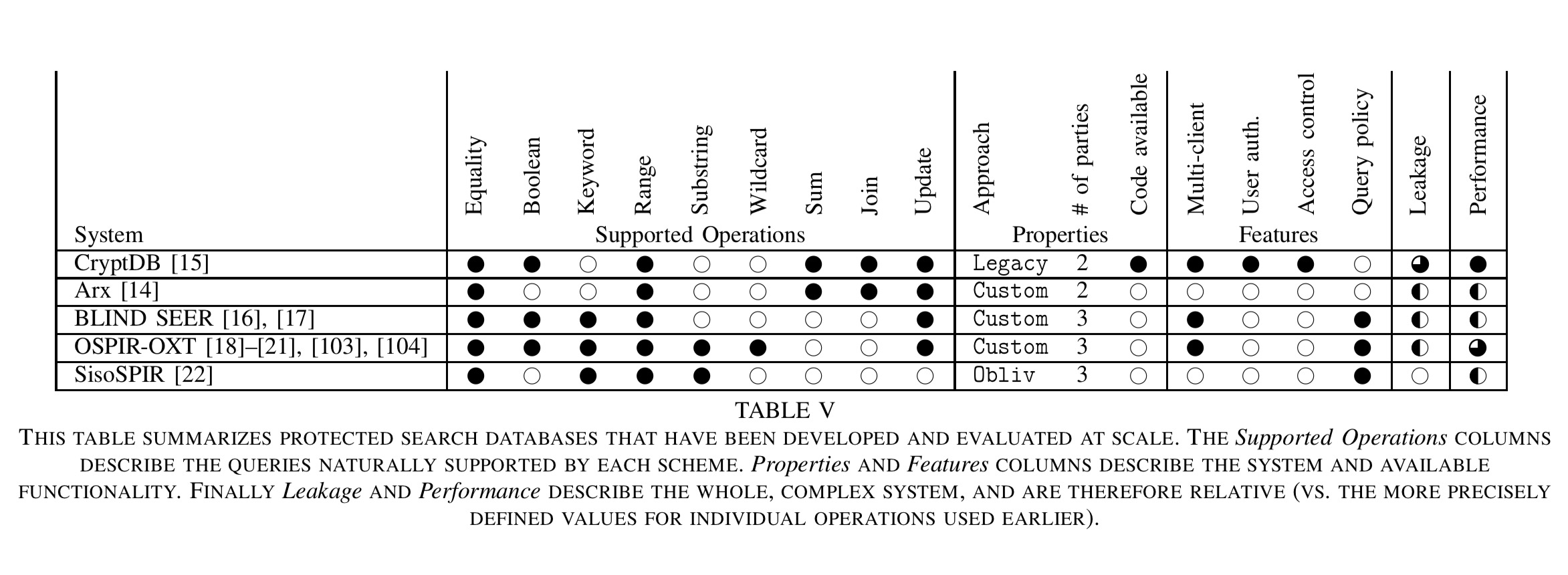
- CryptDB enables most DBMS functionality with a performance overhead of under 30%.
- Arx is built on top of MongoDB and reports a performance overhead of approximately 10%.
- BlindSeer reports slowdowns of between 20% and 300% for most queries
- OSPIR-EXT can occasionally beat a MySQL system with a cold cache (a somewhat strange comparison!), but are an order of magnitude slower than MySQL with a warm cache.
- SisoSPIR reports a 500% slowdown compared to a baseline MySQL system on keyword equality and range queries.
The systems offer different performance/leakage trade-offs. Considering just those based on relational algebra for the moment:
CryptDB is the fastest and easiest to deploy. However, once a column is used in a query, CryptDB reveals statistics about the entire dataset’s value on this column. The security impact of this leakage should be evaluated for each application. Blind Seer and OSPIR-OXT also leak information to the server but primarily on data returned by the query. Thus, they are appropriate in settings where a small fraction of the database is queried. Finally, SisoSPIR is appropriate if a large fraction of the data is regularly queried. However, SisoSPIR does not support Boolean queries, which is limiting in practice.
It is an open problem to construct protected search systems that leverage distributed server architectures.
In conclusion
There’s a lot of information in this paper that I didn’t have space to cover, but the overall message is that the market is early and adopters need to be careful to understand what guarantees they’re really getting and if those are sufficient for their use cases. I’ll leave you with this thought from the author’s own conclusions which I rather like, as it speaks to the value of not knowing something:
Governments and companies are finding value in lacking access to individual’s data. Proactively protecting data mitigates the (ever-increasing) risk of server compromise, reduces the insider threat, can be marketed as a feature, and frees developer’s time to work on other aspects of products and services.
I’m not quite so sure about how much time it frees up, but I agree with the other points.
