A dissection of the test-driven development process: does it really matter to test-first or to test-last? Fucci et al., ICSE’17
Here we have a study with a really interesting aim – to find out which aspects of TDD are most significant when it comes to developer productivity and code quality. What we’d really love to know is how TDD fares in the hands of experienced practitioners. Unfortunately the results of the study come with the usual caveats: it’s a fairly limited group of participants (39), with fairly limited experience, undertaking a somewhat artificial set of tasks. With that pinch of salt firmly in hand, the results show that the most important thing is to work in short uniform cycles with each cycle introducing a small new piece of functionality and its associated tests. The order within the cycle – i.e., test-first or test-last didn’t really seem to matter.
Study tasks and participants
The context of this study is a larger research effort investigating software engineering practices, including test-driven development, in industry. This research initiative involves several industrial partners from the Nordic countries. Two companies, referred to as Company A and Company B in the paper, participated in this study. Company A is a large publicly-traded provider of consumer and business security solutions… Company B is an SME based in Estonia that offers on-line entertaining platforms to businesses worldwide.
Bonus points for the study participants not being computer science undergraduates! ;)
Participants took part in 5-day unit testing and TDD workshops, first teaching the principles of unit testing and how to apply it in an iterative process, and then introducing how to drive development based on a TDD-style test-first approach. Three instances of the workshop were run in company A, and one in company B. In total 22 participants from company A, and 17 from company B took part.
All the subjects except two had at least a bachelor’s degree in computer science or a related field. The average professional experience in Java development was 7.3 years (standard dev. = 4.1, min. = 1, max. = 15 years). Before the workshop, the participants were asked to state their level of skill in Java and unit testing on a 4-point Likert scale. Table 4 shows the breakdown of their answers.
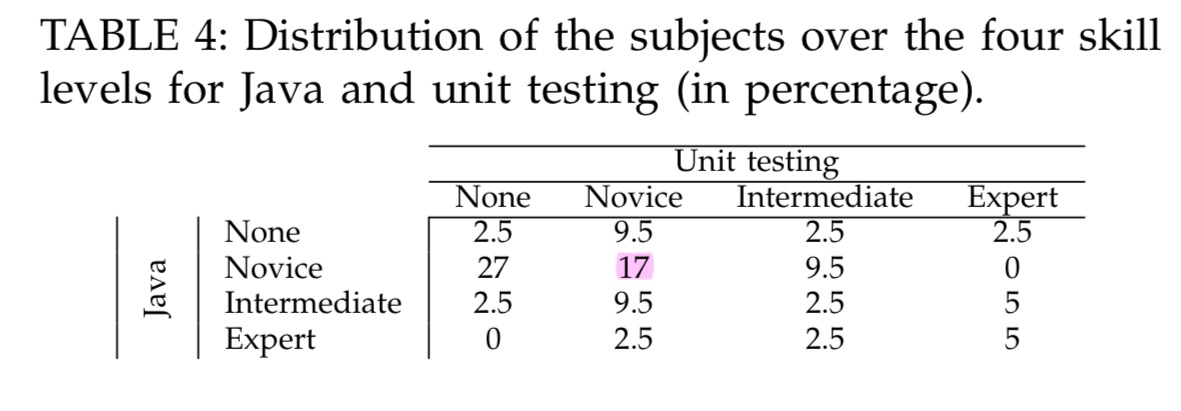
There are a couple of red flags here for me: firstly, studying effectiveness of TDD in a workshop context where participants are pretty much learning unit testing and TDD for the first time means that we’ll learn a limited amount about the benefits in the hands of experienced practitioners – it takes time to adapt your way of thinking; secondly, how can you work professionally in Java development for an average of 7.3 years and still be mostly a novice in terms of Java language and unit testing??
During the workshop, the participants undertook three tasks. The Mars Rover task involved implementing a public API for moving a vehicle on a grid. There are 11 (sub) stories in total, and the participants are given the stub for the class definition, including the full API signature. The Bowling Scorekeeper task is also small with 13 stories to be implemented across two classes, and the class stubs with method signatures already provided. The third task is a larger MusicPhone system with 13 classes and 4 interfaces (i.e., still tiny), and participants had to implement three requirements in the business logic tier (11 sub-stories).
The authors assert:
Two of the three tasks used in the study were artificial and not particularly representative of a real-word situation for a professional software developer. This poses a threat to the generalizability of our results. To mitigate this concern and increase realism, we included a third task, and the three tasks together provided sufficient diversity and balance between algorithmic and architectural problem solving. The resulting diversity moderated the threat to external validity.
From what we’ve been told, I’m not so convinced that the third task is sufficiently realistic to introduce the balance the authors seek, but it’s certainly better than not having it. Also note that in the first two tasks, the precise method signatures to be filled in have already been provided (we don’t know whether this was also the case in the third task). This nullifies one of the expected benefits of the TDD process in my mind – helping you to shape and refine the design / interface.
When requirements may change or are not well known, leading the cycles with tests can provide advantages that were not detectable in this study: test-first can help to understand the requirements, discover new/missing requirements, and find and fix requirements bugs.
While completing the tasks, participants used an Eclipse IDE with the Besouro tool monitoring what they did.
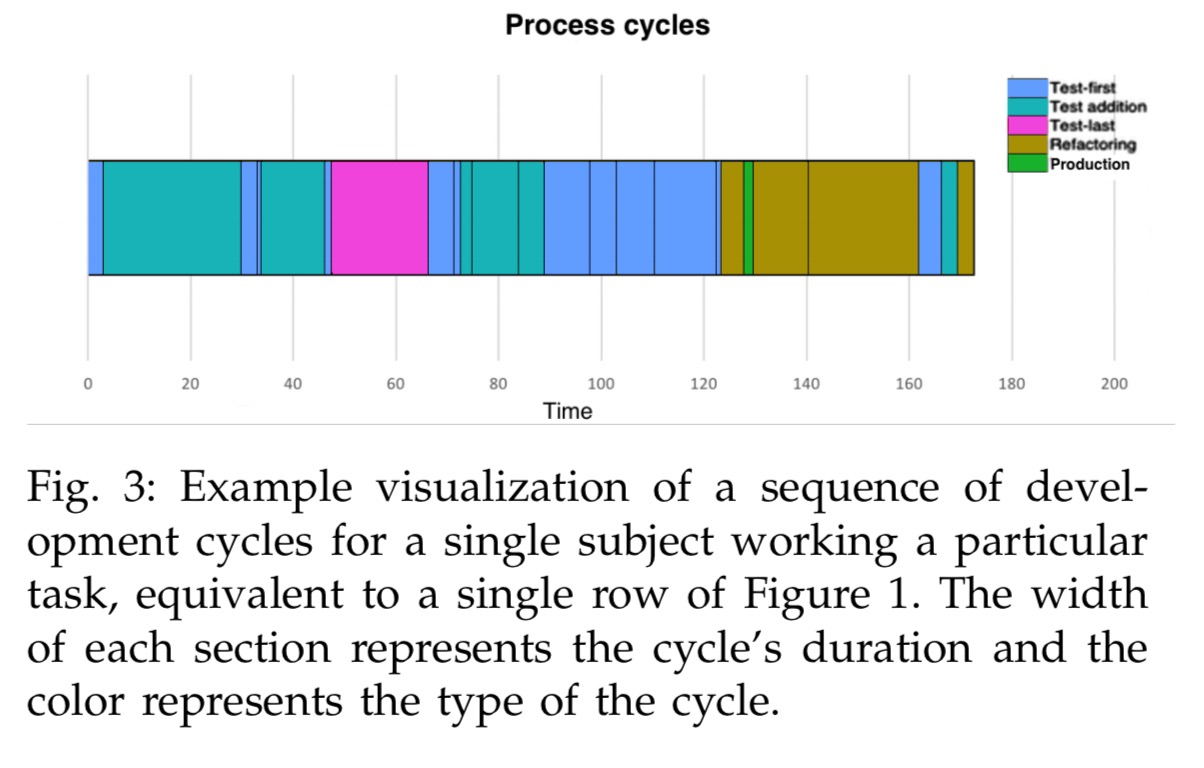
The heuristics used by Besouro to infer the development cycle type are shown in the following table:

Breaking down TDD
The authors analyse four main TDD process dimensions, and two outcome dimensions.
The process dimensions are granularity, uniformity, sequence, and refactoring:
- Granularity is measured as the median cycle duration in minutes. The lower the value, the more fine-grained in general the process is.
- Uniformity measures how well a subject was able to keep the rhythm of development cycles – i.e., do cycles all tend to have a similar duration, or is there more variation in cycle length?
- Sequence addresses the order in which steps are carried out within a cycle. It is measured as the percentage of cycles which are test-first.
- Refactoring effort captures energy expended on refactoring the code base without introducing any new functionality (or at least, any new tests!). It is measured as the percentage of cycles which include some refactoring.

The outcome dimensions are quality and productivity:
- Quality is defined based on the basis of how successful a participant was at the stories they actually tackled. A tackled story is considered to be one in which at least one JUnit assert statement passes. The quality of an individual tackled story is defined to be the percentage of assert statements for that story which pass. The overall quality score for a user is their average tackled story quality.
- Productivity is defined as the percentage of assert statements that a participant got to pass (regardless of whether the associated story is considered ‘tackled’ or not), divided by the total time taken.
Results and caveats
Overall, the dataset contained 82 complete observations. The authors examined correlations between the variables, and then sought to find the simplest possible model with the most predictive power using Akaike’s Information Criterion (AIC)p.
- Granularity and uniformity are positively correlated – i.e., the shorter your cycles, the more consistent you tend to be from one cycle to another.
- Quality is negatively correlated with granularity – i.e., the smaller the cycle, the higher the quality.
- Quality is also negatively correlated with uniformity; the more consistent your cycles, the better the quality (Although this might just be following from the first two points).
… we explore the relationships between the four factors and two outcome variables and find optimal models that explain how useful the factors are in predicting the observed outcomes. We start with a full model that includes all the factors and employ a backward elimination approach to find the model that minimizes information loss according to Akaike’s Information Criterion (AIC).
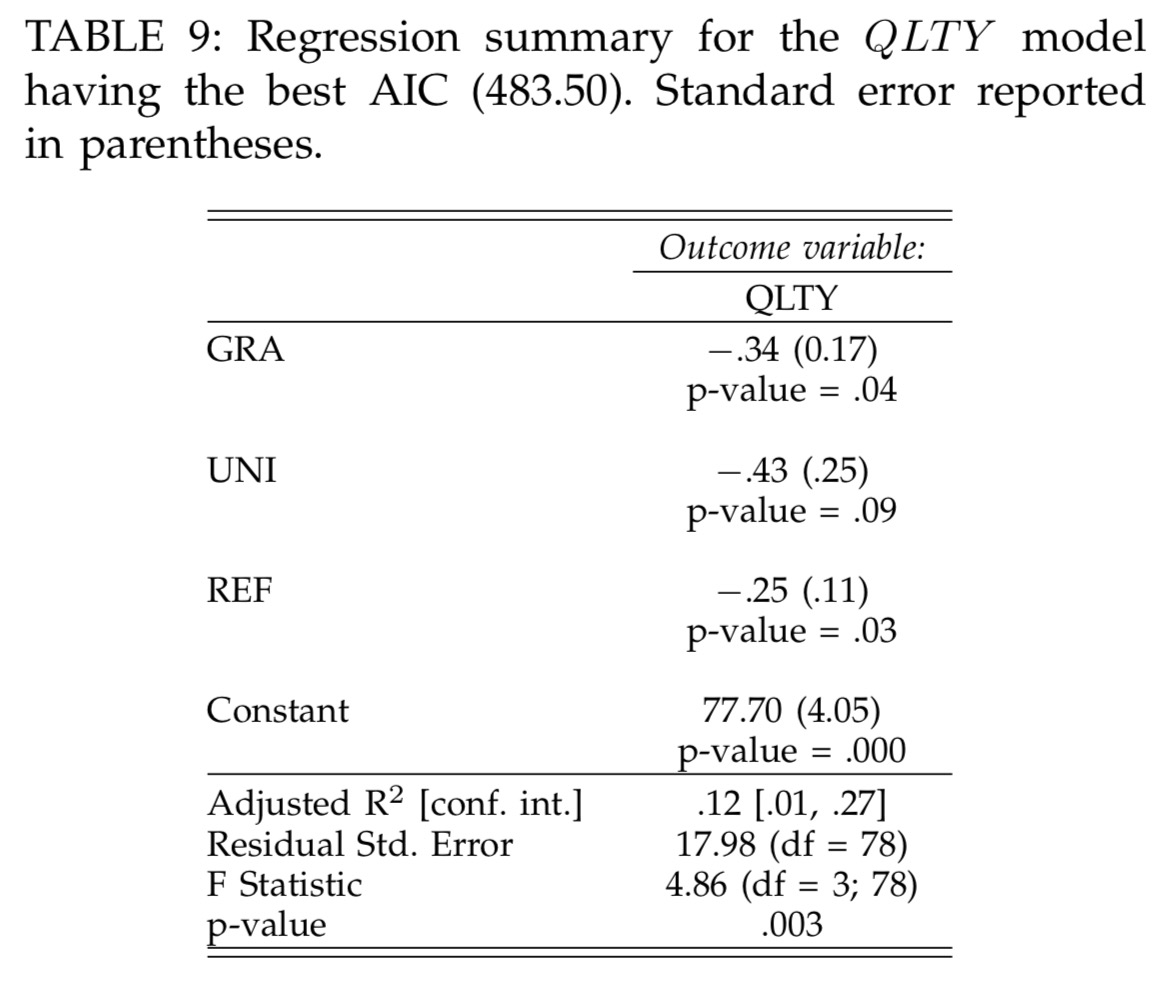
At the end of this process, the the factors in the quality prediction model are granularity, uniformity, and the amount of refactoring undertaken:
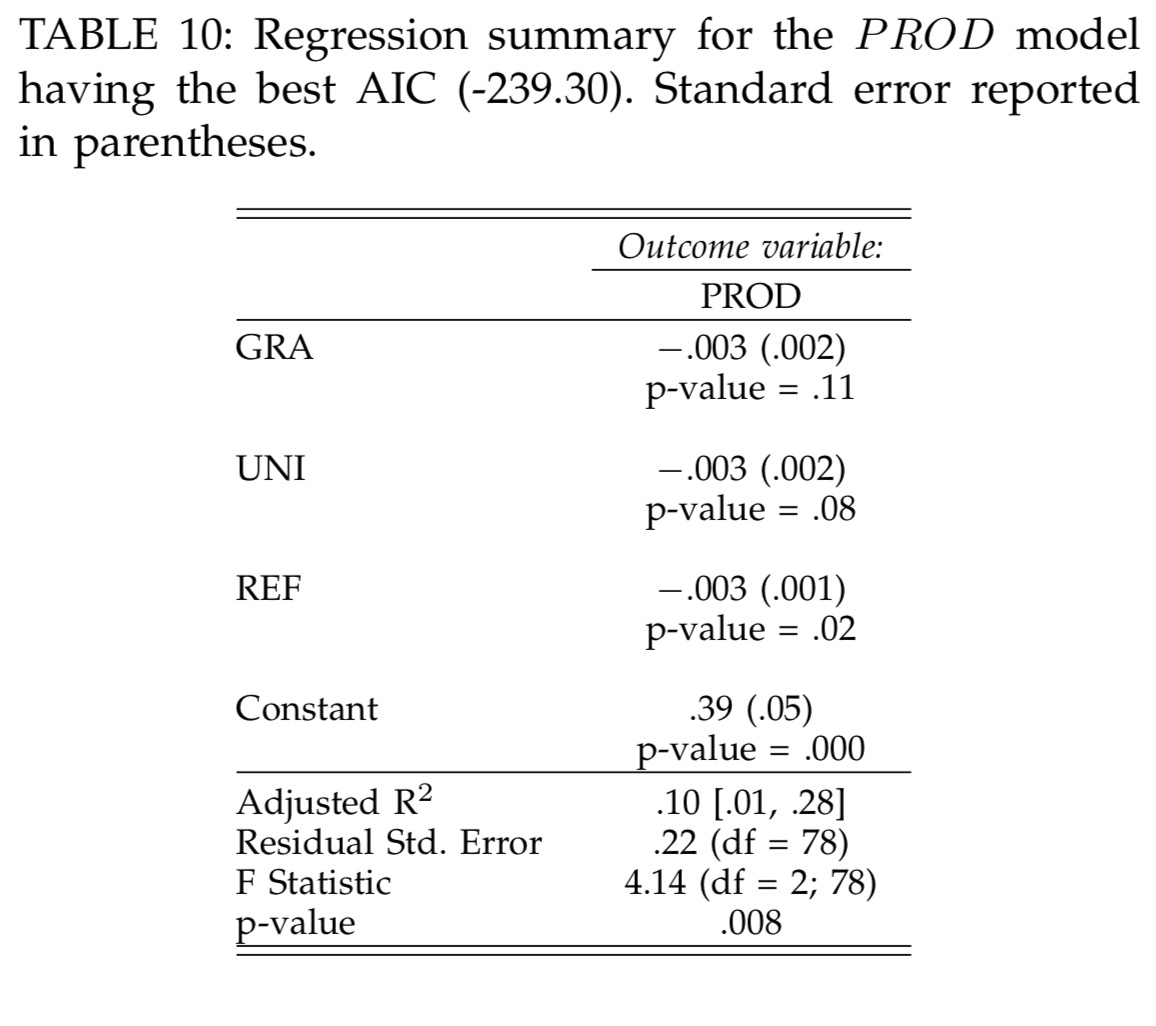
The factors in the productivity prediction model are the same:
Note that sequence does not appear in either model:
This is surprising as it implies the sequence in which writing test and production code are interleaved is not a prominent feature. The finding counters the common folklore within the agile software development community.
(Remember from our earlier discussion though that the task setup precludes some of the expected benefits of test-first).
Refactoring also shows up in both models as a negative factor – i.e., the more refactoring you do, the worse the productivity and quality. For productivity at least, this seems to me to be an artefact of the chosen measurements. Since productivity is simply a measure of passing assert statements over time, and refactoring doesn’t change that measure, time spent on refactoring must by this definition lower productivity. Not accounted for at all are the longer term impacts on code quality (and hence future productivity) that we hope to attribute to refactoring. The model is set up to exclusively favour short-term rewards.
Regarding the GRA coefficient in QLT Y (Table 9), reducing the cycle length further from the often suggested values of five to ten minutes results in little improvement. The improvement can be as high as 14% when cycle length is reduced from its maximum observed value at around 50 minutes down to the average observation of eight minutes in the nominal range of the dataset.
Given all the caveats, what can you take away from this study? For me the main takeaway is that much (most?) of the value is in working in small cycles introducing both code and its associated tests in each cycle. Whether you test-first or last within a cycle is secondary to that, but test-first may well have other benefits not measured in the study.
… we have not tackled the potential benefits of test-first in resolving requirements uncertainty, formalizing design decisions, and encouraging writing more tests, all of which may kick in the longer term and tip the balance in favor of an emphasis for test-first.
And I certainly wouldn’t rush to stamp out all refactoring!!!

Grrr, you don’t recognise good work when you see it (and sometimes praise complete nonsense)! Having 39 professional participants with a mean of 7.3 years professional experience is gold-dust. A 5-day workshop? Most studies teach the material for an hour or so before the experiment.
Self-rated skill level is essentially a random number, biased by novices who think they know everything rating themselves high and experts who are aware how little they know rating themselves low.
I’m not too worried about the nature of the tasks. What makes tasks artificial? Is size really that important a factor (apart from complicating the setup process)?
You forgot to mention that the authors provide the experimental materials and results, so others can replicate their results (this is becoming more common). I have not yet had time to look at their data, but they appear to have only done some basic statistical analysis, i.e., there may be more patterns of behavior to be uncovered..
Thanks for featuring this paper, addressing an area where there are more opinions than facts. As perhaps is inevitable for such an area, I have a different take on a couple of the issues you raise.
I don’t see the provision of class and method signatures in the requirements as specifically disadvantaging TDD. Your argument for it doing so is based on the claim that TDD helps you to shape and refine the design / interface, but AFAIK that is not strongly supported at this point – it is one of the assumptions used to suggest there is some credence to those claims about TDD that are nominally being tested here, which I think gives your objection a hint of circularity. It would be interesting to see the same requirements, but with or without the signatures, being assigned randomly to the subjects, then we would have something to go on.
Secondly, there is an alternative possible explanation for the negative correlation of productivity and refactoring: the more productive of the subjects were closer to being right on their first pass, and so did not do as much refactoring. If this were the case, there is no reason to believe the more refactored code would have greater long-term quality, and in fact my guess is that, if anything, it would, in general, continue to be inferior, though perhaps with a tendency to converge on the quality of the less-reworked code.
My personal take is that test-first might be helpful in getting developers to think more deeply about the requirements before they code – writing tests requires that you take the rather abstract requirements and think about their implications in concrete terms, but maybe not in terms of a specific implementation. This, of course, is just as much a guess as most of the other claims about TDD, but it suggests that one problem of this study was that the requirements were too over-specified to reveal all the differences in the approaches to development.
On the other hand, TDD seems to have had the unfortunate effect that a subset of developers seem to have assumed that any sort of abstract analysis of the problem is anathema. This may be a misunderstanding of TDD, or just a case of taking its principles to the point of dogma, but it is out there – such opinions surface with some regularity on Stack Overflow / Exchange, for example. To me, it is completely unclear how you can apply this interpretation of TDD alone in situations where the requirements place nontrivial demands on emergent features of a design, such as performance, reliability, fault-tolerance or scalability.