Decoding the representation of code in the brain: an fMRI study of code review and expertise Floyd et al., ICSE’17
fMRI studies have been used to explore how our brains encode expertise in physical tasks involving specialised motor skills (for example, playing golf), in memory development (for example, London taxi drivers), and in mental skills development (for example, chess). But until now, no-one has used fMRI to try and understand what goes on in the brain when interpreting code.
… we have almost no understanding of how the human brain processes software engineering tasks.
Floyd et al. set out to change this through a study of 29 participants completing code comprehension, code review, and prose (natural language) review tasks while in an MRI scanner. What we have here then, are some early insights into how your brain perceives code. And yes, they uncover differences in brain patterns between more experienced and less experienced developers. Read on to find out what they are!
In the code comprehension task, participants are shown a snippet of code and asked a question about it. In the code review task participants are shown a GitHub pull request (a patch and a comment) and asked whether they would accept it. In the prose review task participants are shown English prose with simple editing markups and asked whether they would accept them.

Why these particular tasks? The constraints of fMRI have a lot to do with it. Firstly, you need simple snippets that can be presented on a single screen and questions that the participant can respond to by clicking an Accept button or a Reject button on an MR-compatible button box (the authors subsequently managed to adapt a silicone-and-plastic keyboard that could potentially be used in future experiments to observe people writing code).
Second, fMRI analysis are typically based on contrasts between two different task conditions.
Through our experimental controls, we can isolate one feature of the tasks and observe differences in brain activation. For example, the primary difference between the prose review and code review tasks is whether the subject is English prose or a computer program; any difference in observed brain activity corresponds to a task difference. Similarly, a simple model might posit that code review is code comprehension followed by a code judgment (i.e., understanding what the patch will do and then deciding if it is acceptable); contrasting code review to code comprehension focuses on the judgment aspect, since code understanding is present in both.
Finally, code comprehension and review are important activities since developers spend more time understanding code than any other activity. “Numerous studies have affirmed that code review is one of the most effective quality assurance techniques in software development” (see section II.A in the paper for references). And when it comes to comprehension, we have an appeal to Knuth (among others)!
[Knuth] argued that a program should be viewed as “a piece of literature, addressed to human beings” and that a readable program is “more robust, more portable, and more easily maintained.”
Understanding differences through classifiers
For each participant, the authors train three binary Gaussian Process Classifiers (GPC):
- Code review vs Prose review (is there a difference in the brain when reviewing code, vs reviewing prose)
- Code comprehension vs Prose review (is there a difference in the brain when interpreting code, vs reviewing prose)
- Code review vs code comprehension (is there a difference in the brain when making judgements about code as opposed to just trying to understand it).
If code and prose are processed using highly-overlapping parts of the brain, then it should be difficult to create an accurate classifier due to the entangled patterns of activity.
Gaussian Processes treat the classification problem as an extension of the multivariate Gaussian, defined by a covariance function that is used to make predictions for new data (conditioned on a training set). We elected to use GPC over other common methods (e.g., the support vector machine) for several reasons: 1) predictions are made by integrating over probability distributions (vs. hard linear decisions); 2) model hyperparameters and regularization terms are learned directly from the data (vs. costly nested cross-validation routines);
and 3) maximum likelihood is robust to potential imbalances in class size, which otherwise bias linear classifiers toward predicting the more common class.
Class predictions are made using expectation propagation (EP).
The Automated Anatomical Labeling (AAL) atlas provides labels for the locations in 3-dimensional space where the measurements of some aspect of brain function are captured. Using this atlas the kernel weights from the learned classifiers (the feature set contained 47,187 voxels across 90 regions of the cerebrum) are projected back onto the 3D brain, and the average voxel value is computed for each region. Then a contribution strength is calculated for each region as the region’s average voxel value divided by the sum across all regions, “yielding a proportion that is directly interpretable as regional importance – a larger value indicates more total weight represented within a region.”
Your brain on code
The first key result is that the learned classifiers could accurately distinguish between all trials (code review vs prose, code comprehension vs prose, and code review vs code comprehension).
These results suggest that Code Review, Code Comprehension, and Prose Review all have largely distinct neural representations. Inspection of the average weight maps for each Code vs Prose model revealed a similar distribution of classifier weights across a number of brain regions.
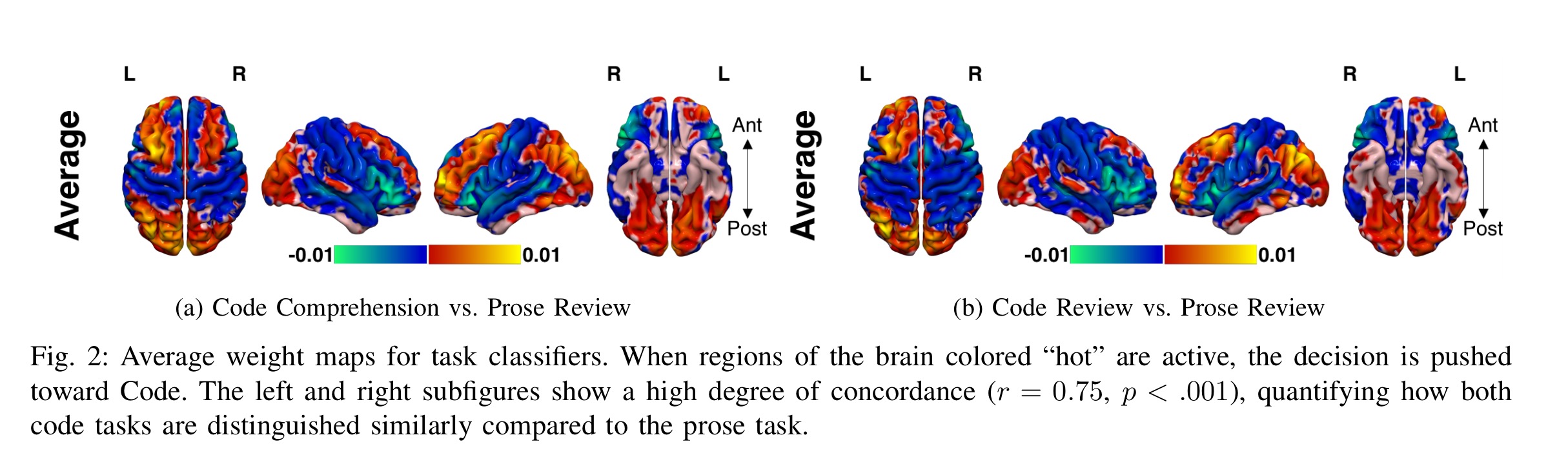
The authors then looked at the regional importance maps for the areas most involved in classification, and the traditional roles and importance of those regions (i.e., what ‘parts’ of the brain are most engaged).
Here you can see the average regional importance maps for classifying code-related tasks (comprehension or review):
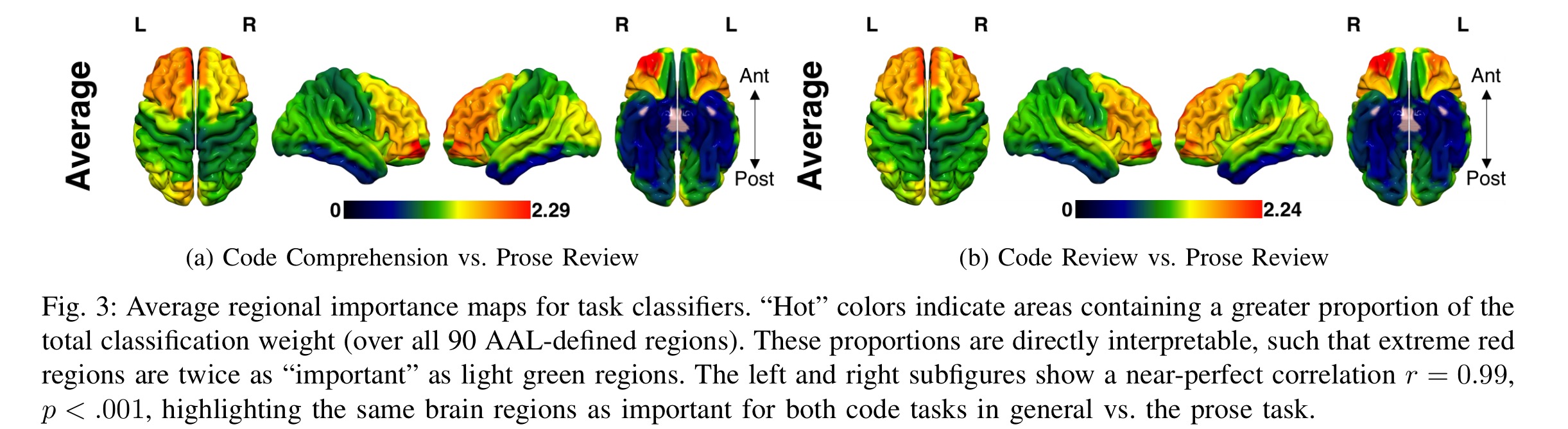
For both classifiers, a wide swath of prefrontal regions known to be involved in higher-order cognition (executive control, decision-making, language, conflict monitoring, etc.) were highly weighted, indicating that activity in those areas strongly drove the distinction between code and prose processing.
There were also large contributions from a region classically associated with language comprehension. Remember that the high weightings here (in the classifier) tell us that these are regions which are more actively engaged when processing code than when processing language.
What difference does experience make?
Finally we turn to the question which I find the most interesting of all: is there a difference in the brains of expert developers as compared to lower skilled participants? Strictly, we don’t really have data from truly experienced practitioners. What we have instead is a expertise rating based on the normalised grade point average (GPA) of participants from the Computer Science courses they took (not every participant majored in CS, but they all took at least some CS classes). Even so, if you plot classification accuracy against expertise, something interesting happens:
… the extent to which classifiers distinguished between Code Comprehension and Prose significantly predicted expertise. The inverse relationship between accuracy and expertise suggests that, as one develops more skill in coding, the neural representations of code and prose are less differentiable. That is, programming languages are treated more like natural languages with greater expertise.
Will the technical interview of the future be replaced by / augmented with “can you please look at these code examples while we study how your brain lights up” ???!
For anyone interested in pursuing these kinds of studies further, the authors end with a nice section (VII) discussing the costs and approvals necessary to carry out this kind of research.
To mitigate these costs, we have made our IRB protocol, experimental materials, and raw, de-identified scan data publicly available at http://dijkstra.cs.virginia.edu/fmri/. This allows other researchers to conduct alternate analyses or produce more refined models without the expense of producing this raw data.

One thought on “Decoding the representation of code in the brain: an fMRI study of code review and expertise”
Comments are closed.