Bolt: I know what you did last summer… in the cloud Delimitrou & Kozyrakis, ASPLOS’17
You get your run-of-the-mill noisy neighbours – the ones who occasionally have friends round and play music a little too loud until a little too late. And then in the UK at least you get what we used to call “Asbos,” named after the Anti-Social Behaviour Orders that were introduced to try and curb deliberate disturbances of the peace. The same thing happens on the public cloud. You have accidental interference from neighbouring processes, and then you have your cloud ASBOs – which make deliberate attacks on neighbouring processes.
… unmanaged contention leads to security and privacy vulnerabilities. This has prompted significant work on side-channel and distributed denial of service attack (DDoS), data leakage exploitations, and attacks that pinpoint target VMs in a cloud system. Most of these schemes leverage the lack of strictly enforced resource isolation between co-scheduled instances and the naming conventions cloud frameworks use for machines to extract confidential information from victim applications, such as encryption keys.
By the time you’ve glanced through the long list of references to such attacks in the related work section (we’ll look at a few attack examples later on), you’ll be quite glad you’re not trying to run a public cloud service yourself! It’s a bit of an arms race of course, with cloud providers also mounting defences. Today’s paper selection, Bolt, shows just how hard that job is becoming. When Bolt pops up as your cloud neighbour, it is able to fingerprint the resources used by your own process to determine what type of process you are running (e.g., memcached, Spark job, …).That’s invaluable information to an attacker.,
Extracting this information enables a wide spectrum of previously impractical cloud attacks, including denial of service attacks (DoS) that increase tail latency by 140x, as well as resource freeing (RFA) and co-residency attacks.
Using the information that Bolt provides, attackers can mount these attacks in a way that circumvents traditional detection and prevention mechanisms. The paper concludes with a look at the isolation mechanisms available to see how well they can protect against Bolt’s process detection.
Existing isolation techniques are insufficient to mitigate security vulnerabilities, and techniques that provide reasonable security guarantees sacrifice performance or cost efficiency, through low utilization. This highlights the need for new fine-grain, and coordinated isolation techniques that guarantee security at high utilization for shared resources.
Let’s now take a look at (a) the process detection mechanism, (b) the security attacks that can take advantage of it, and (c) how well existing isolation mechanisms can defend against them. Ready?
I know what you’re doing in the cloud
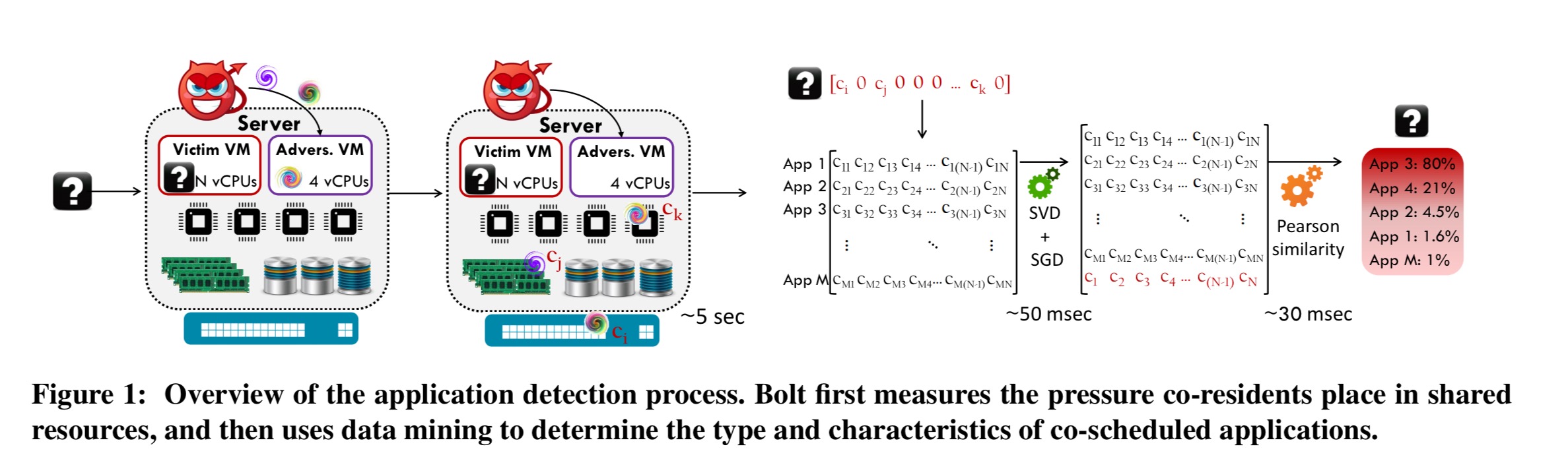
Let’s start with the simple case of one Bolt detection process co-scheduled with a victim process. Bolt attempts to figure out how much the victim process depends on different types of shared resources, resulting in a fingerprint of shared resource sensitivity for the victim. It does this by running a series of micro-benchmarks, each targeting a given shared resource (L1 instruction and L1 data cache, L2 and last level cache, memory capacity and memory bandwidth, CPU, network bandwidth, disk capacity and disk bandwidth).
Each microbenchmark progressively increases its intensity from 0 to 100% until it detects pressure from the co-scheduled workload, i.e., until the microbenchmark’s performance is worse than its expected value when running in isolation. The intensity of the microbenchmark at that point captures the pressure the victim incurs that shared resource.
Bolt runs microbenchmarks for 2-5 seconds, with one core benchmark and one ‘uncore’ benchmark (zero pressure will be detected in the core resource if it is not shared). This is long enough to gather all the data Bolt needs.
 (Click for larger view)
(Click for larger view)
At this point we’ve essentially got what looks like a classification problem, mapping resource fingerprint to workload type. At the core of this process Bolt uses SVD and Pearson correlation to figure out how similar the victim process resource profile is to workloads that have been seen before. The analysis also reveals information on the resources the victim is most sensitive too, which is useful in crafting attacks.
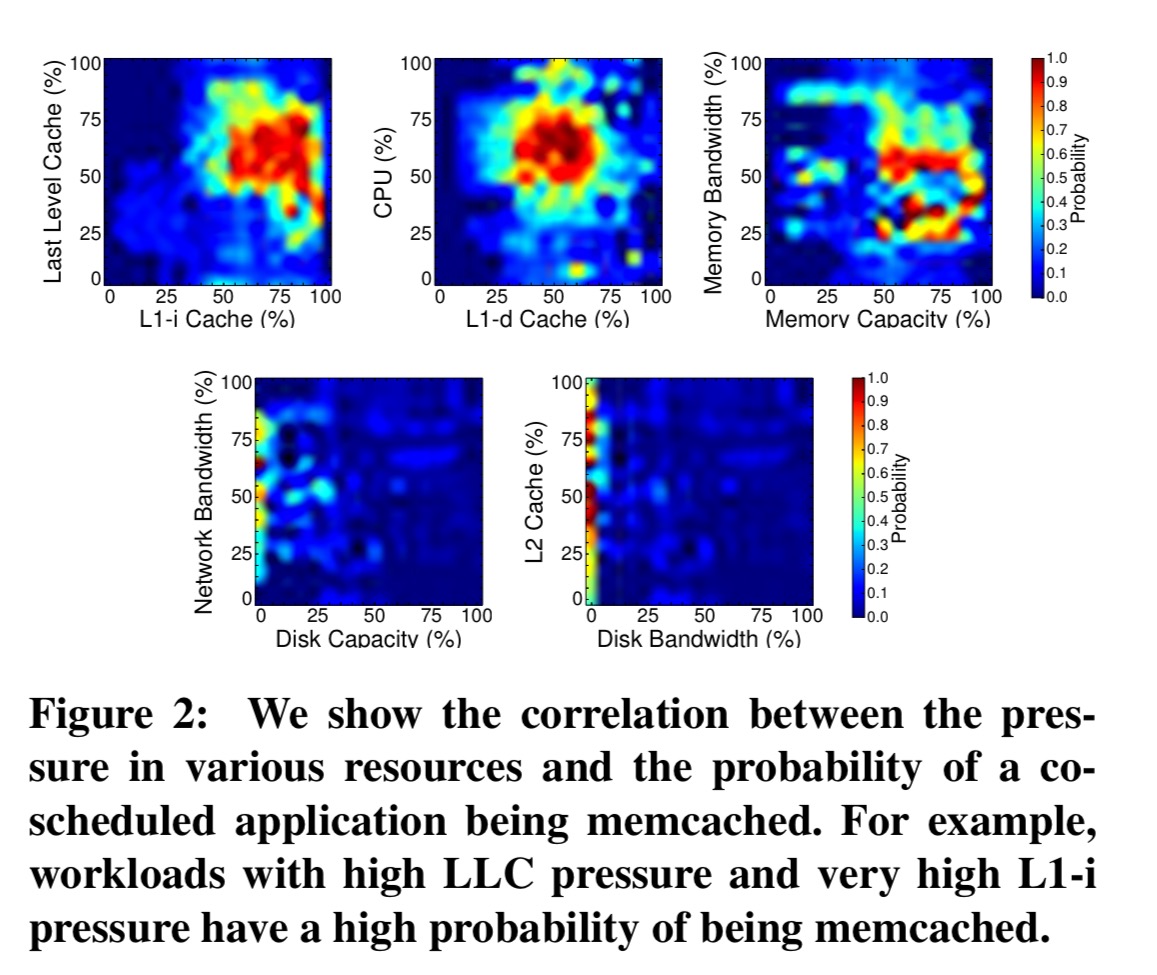
Here you can see, for example, that high LLC pressure and very high L1-instruction cache pressure indicated a high probability the victim process is memcached.
With multiple co-residents, Bolt needs to disentangle the contention caused by several jobs. If one of the co-resident applications shares a core, we can exploit that. Otherwise Bolt runs a shutter profiling mode using frequent brief profiling phases in uncore resources. Say there are two co-resident victim processes. If Bolt manages to capture a moment when one of them is at low load, the resource pressure mechanism will enable effective detection of the other (highly loaded) process.
How well does the detection process work?
The first evaluation is conducted on a 40-node cluster with 8 core servers and a total of 108 different workloads. The training set comprises 120 diverse applications selected to provide sufficient coverage of the space of resource characteristics (everything from web servers to analytics and databases).
Here we see Bolt’s detection accuracy under a standard ‘least loaded’ scheduling algorithm, and also under Quasar, which also uses job fingerprinting to deliberately try to place jobs where they will see the least interference.
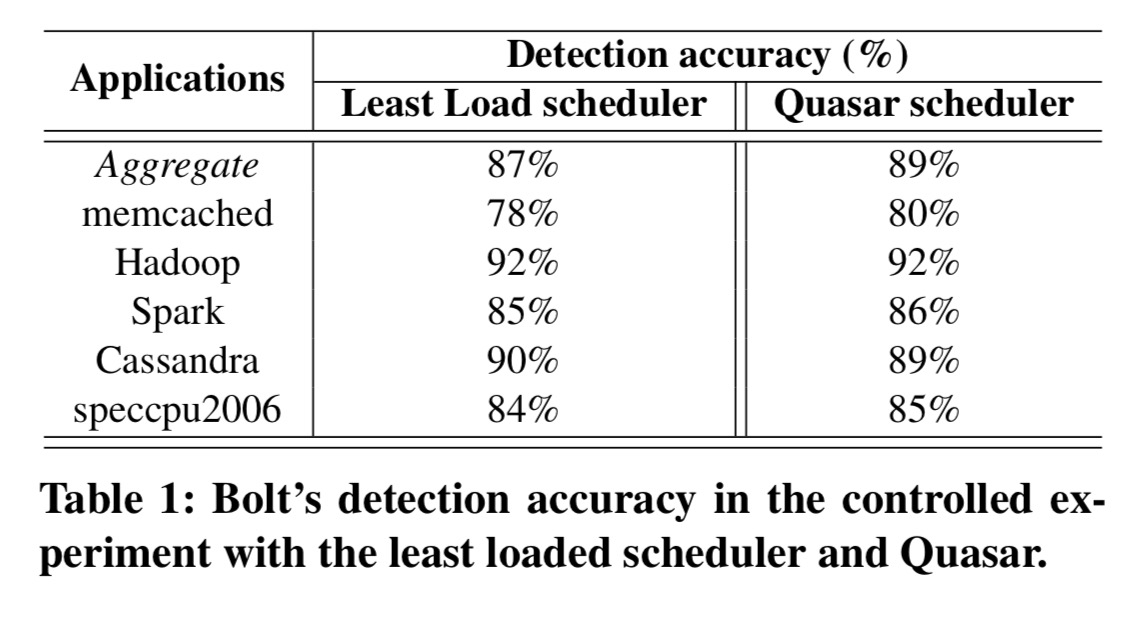
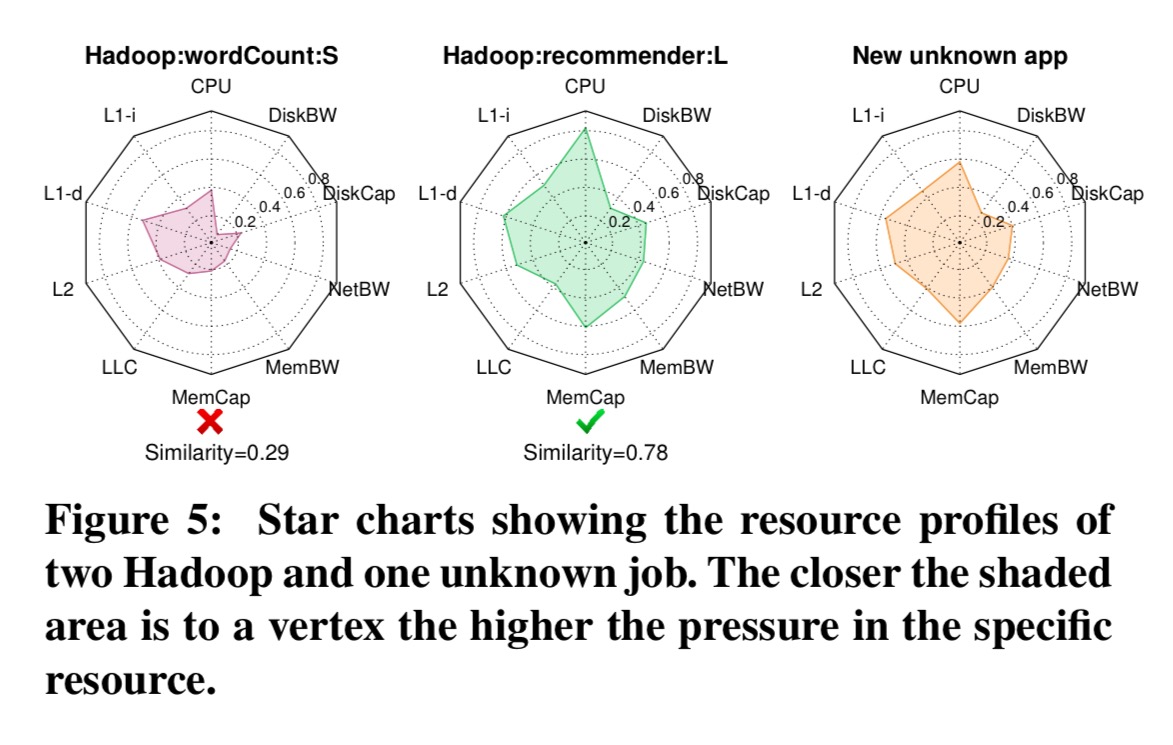
Note that, although in Table 1 we group applications by programming framework or online service, each framework does not correspond to a single resource profile. Profiles of applications within a framework can vary greatly depending on functionality, complexity, and dataset features. Bolt’s recommender system matches resource profiles to specific algorithmic classes and dataset characteristics within each framework.
Here’s an example of two known Hadoop jobs (a recommender, and word count) being compared to a just captured fingerprint of a new unknown process:
When there is only one co-resident, detection accuracy exceeds 95%. Accuracy drops with more co-residents, reaching 67% with 5 co-scheduled applications.
A second evaluation took place on EC2 in a 200-node cluster of c3.8xlarge instances. 20 independent users were asked to submit several applications of their choosing, and Bolt had to figure out what they were. A total of 436 jobs were submitted to the cluster, 277 of them were correctly labelled. Bolt could not of course assign labels to application types it had not seen before (such as email clients), but it still managed to gather resource profiles for these.
Security attacks
The authors discuss how Bolt can help with three classes of attacks or attack steps, internal DoS attacks, resource freeing attacks, and VM co-residency detection.
Internal DoS
Internal DoS attacks take advantage of IaaS and PaaS cloud multi-tenancy to launch adversarial programs on the same host as the victim and degrade its performance.
For these attacks, the information providing by Bolt is used to create custom contentious workloads combining the microbenchmarks in the resources the victim is most sensitive to. Using this approach against the 108 applications in the first evaluation, performance of the victim was degraded by 2.2x on average and up to 9.8x overall.
Degradation is much more pronounced for interactive workloads like key-value stores, with tail latency increasing by 8-140x, a dramatic impact for applications with strict tail latency SLAs.
Typical detection of such attacks relies on detecting resource saturation. But Bolt’s finely-tuned mechanism is able to keep the utilization low enough to evade detection while still negatively impacting the victim.
Resource Freeing Attack
The goal of a resource freeing attack (RFA) is to modify the workload of a victim such that it frees up resources for the adversary, improving its performance.
Bolt adds load in the victim’s critical resources, which causes it to stall, which in turns means it lessens its pressure on other resources. These resources are then gobbled up by the adversary.
Here are the results from Bolt-powered RFA attacks on a selection of victim apps:

(We don’t really care about the beneficiary app (mcf in this case) uplift, it’s the performance degradation column that matters).
Co-residency detection
… a malicious user is rarely interested in a random service running on a public cloud. More often, they target a specific workload, e.g., a competitive e-commerce site.
This requires an efficient means of finding the victims. Good (bad?) news! Bolt can help with that. First you launch a bunch of Bolt processes looking for co-residents of the appropriate type. Having found a candidate, apply appropriate resource contention and at the same time make an external request to the server from a collaborating ‘receiver’. If the external receiver sees a slower response than normal, there’s a good chance you’ve found your target. The paper demonstrates the attack in a 40-node cluster using 10 probes which detect 3 VMs running SQL.
It then introduces memory interference, as the receiver initiates a large number of SQL queries. While these queries have 8.16msec mean latency without interference, latency now becomes 26.14msec. Given a ∼3× latency increase, we can conclude that one of the co-residents is the victim SQL server. Detection required 6sec from instantiation to receiver detection, and 11 adversary VMs.
Better isolation to the rescue?
The authors evaluate baremetal, containerized, and virtualized environments and apply or simulate thread pinning, network isolation, DRAM bandwidth isolation, and last-level cache (LLC) isolation. One isolation mechanism at a time is added, which reveals their contribution to decreasing detection accuracy.
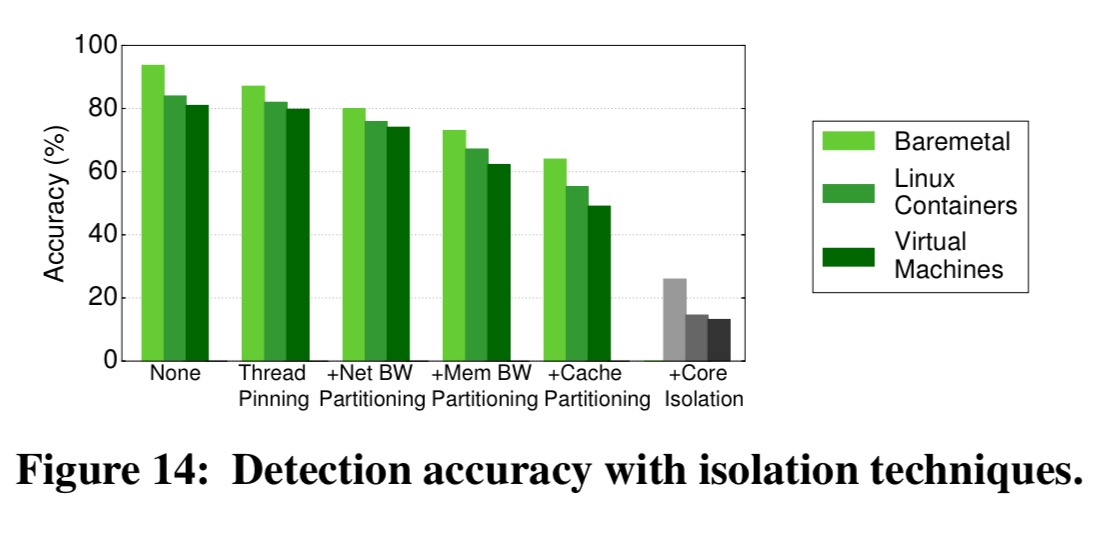
Unfortunately, even when all techniques are on, accuracy is still 50% due to two reasons: current techniques are not fine-grain enough to allow strict and scalable isolation and core resources (L1/L2 caches, CPU) are prone to interference due to contending hyperthreads.
Ensuring hyperthreads of different jobs are never scheduled on the same core does help (grey bars in the figure above), but adds approximately a 34% performance overhead. Over-provisioning to compensate leads to a 45% drop in utilisation.
The last word
We hope that this study will motivate public cloud providers to introduce stricter isolation solutions in their platforms and systems architects to develop fine-grained isolation techniques that provide strong isolation and performance predictability at high utilization.

3 thoughts on “Bolt: I know what you did last summer… in the cloud”
Comments are closed.