Typed Architectures: architectural support for lightweight scripting Kim et al., ASPLOS’17
JavaScript, Python, Ruby, Lua, and related dynamically typed scripting languages are increasingly popular for developing IoT applications. For example, the Raspberry Pi is associated with Python; Arduino and Intel’s Galileo and Edison are associated with JavaScript. In these constrained hardware environments though, using JITs is often not viable so scripting engines employ interpreter based VMs without JITs. Thus for production grade applications, scripting languages may be too slow.
Dynamic types are one of the major sources of inefficiency for scripting languages… each variable must carry a type tag, and a type guard must be executed before any operation that can be overloaded. This significantly increases dynamic instruction count, memory footprint, and hence energy consumption, compared to statically typed languages.
A recent study showed that around 25% of total execution time in the V8 JavaScript engine is spent on dynamic type checking. Back in the 1980s, LISP machines such as the Symbolics 3600 provided hardware support for runtime type checking. Could we do something similar for dynamically typed languages today?
It turns out that yes we can. Kim et al. introduce Typed Architectures, “a high-efficiency, low-cost execution substrate for dynamic scripting languages.”
Typed Architectures calculate and check the dynamic type of each variable implicitly in hardware, rather than explicitly in software, hence significantly reducing instruction count for dynamic type checking.
An FPGA-based evaluation showed geomean speedups of 11.2% and 9.9% (max speedups 32.6% and 43.5%) for production grade JavaScript and Lua scripting engines respectively. And all this with a 16%-19% improvement in energy-delay product.
Which all goes to prove you can optimise all you like in software, but at the end of the day it’s hard to beat hardware! What’s especially neat about Typed Architectures is that the authors seem to have found a nice sweet spot whereby the hardware support is general enough to efficiently support a wide range of dynamically typed languages.
The overhead of dynamic typing
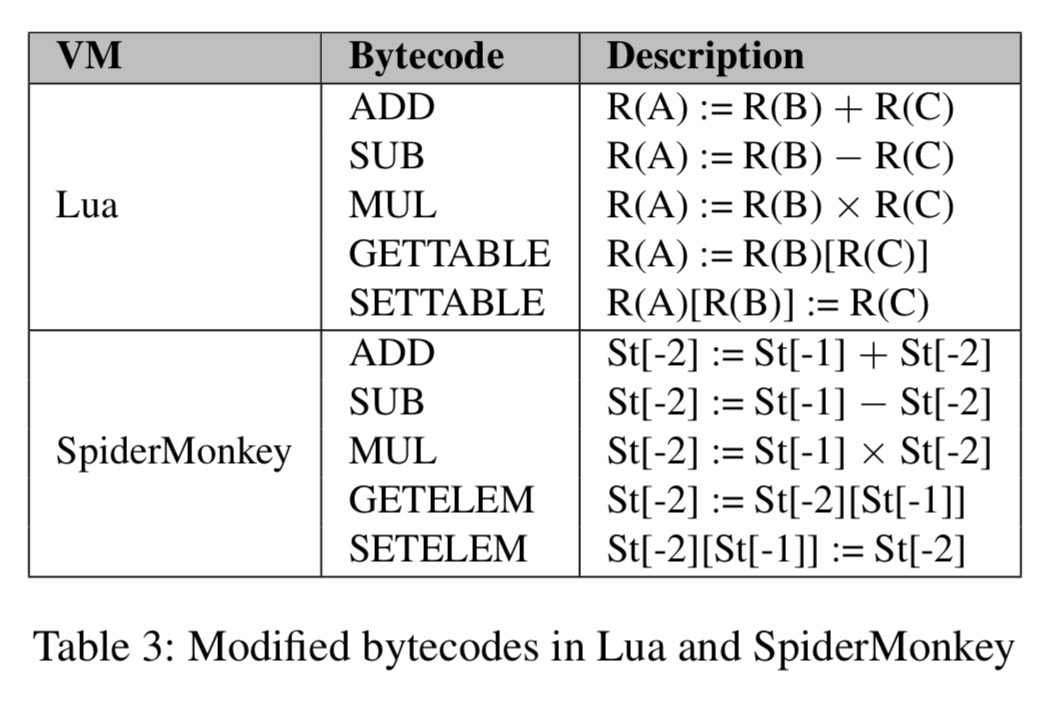
With dynamic typing, values are tagged with their type, and these type tags are checked when dispatching operations (e.g., a polymorphic ADD operation must be dispatched to type-specific implementations).
The overhead of dynamic type checking is known to be significant.
Here’s a breakdown of dynamic bytecodes in 11 Lua scripts. Lua has 47 distinct bytecodes, but less than 10 dominate the total count.
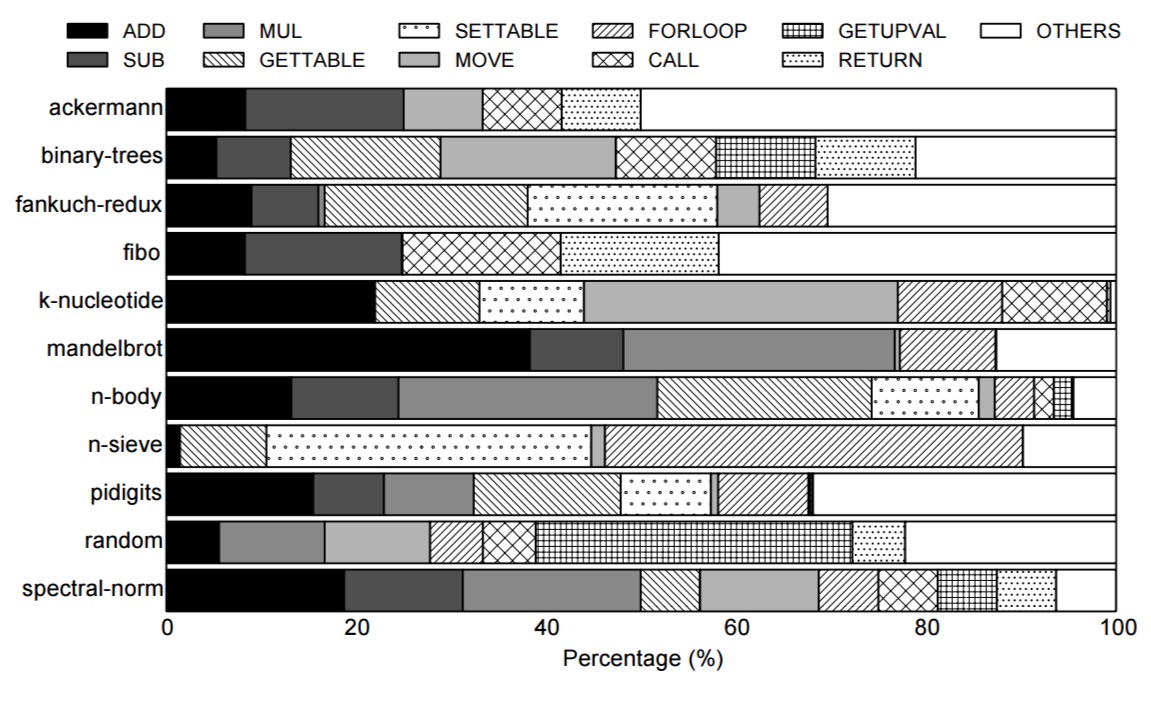
If we drill into the five most popular bytecodes, we can see the number of dynamic instructions per bytecode for each of these:
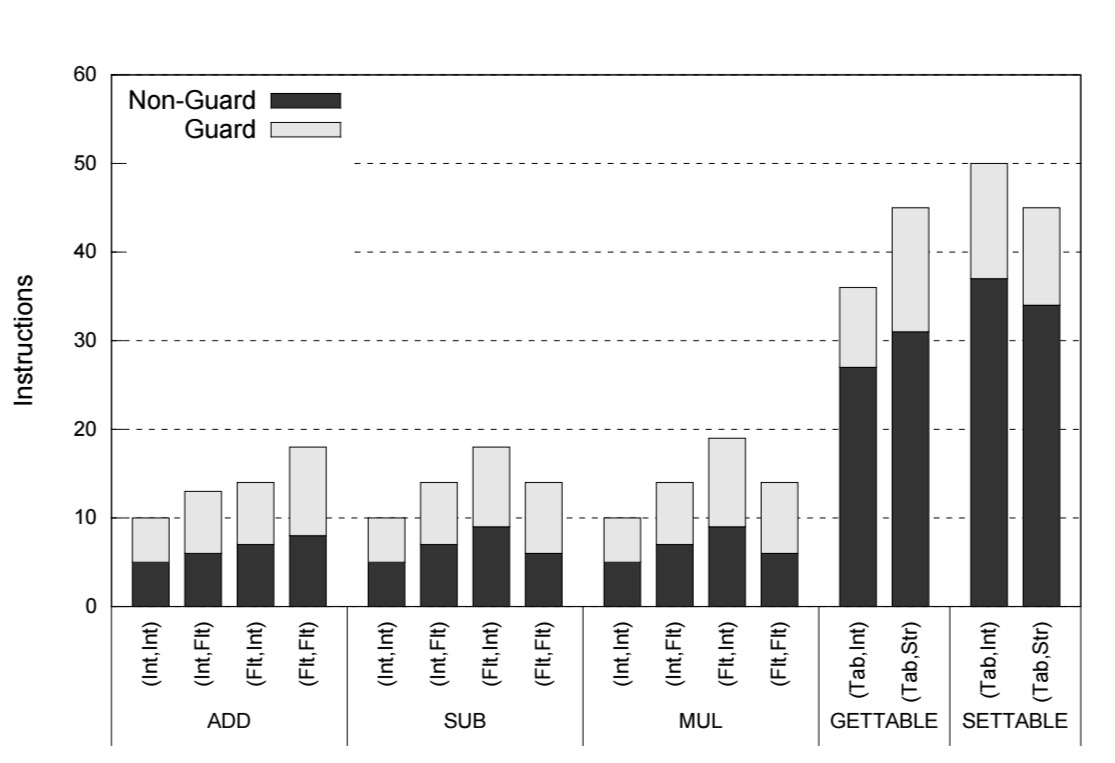
These five bytecodes are all polymorphic and require type guards to select the right function depending on the operand types.
Dynamic typing overhead can be broken down into three components: tag insertion (adding tags to values), tag extraction (getting tags for values), and tag checking. The following example of a polymorphic add function in Lua (with corresponding Lua bytecode and RISC-V assembly code) makes the point pretty well.
 (Click to enlarge)
(Click to enlarge)
Typed Architectures – ISA extensions
The three primary design objectives for Typed Architectures are:
- High performance – significant speedups by offloading type checking operations to hardware
- Flexibility – the ISA extension should be flexible enough to support multiple production grade scripting engines
- Low cost – in terms of area and power
The baseline RISC ISA is extended with a unified register file, tagged ALU instructions, and tagged memory instructions.
The register file gains two new fields (in addition to the existing register value field): an 8-bit type tag (capable therefore of representing 256 distinct types), and a 1-bit flag indicating whether the value is of an integer or floating-point subtype.
There are three new tagged ALU instructions, xadd, xsub, and xmul which perform type checking in parallel with value calculation. A Handler register is used to handle type mispredictions.
When a tagged ALU instruction is executed, Typed Architecture looks up in a Type Rule Table with the two source type tags and the instruction’s op-code as the key. If it hits, the pipeline executes normally to write back the output type tag retrieved from the Type Rule Table together with the output value to the destination register. If not, a type misprediction has happened, and the PC is redirected to the slow path pointed to by the handler register to go through the original software-based type checking.
The Type Rule Table itself is pre-loaded at program launch.
There are two new instructions for memory operations: tld (tagged load) and tsd (tagged store). These load / store a requested value together with its type tag and integer/FP flag bit in a single operation.
A type tag is extracted from an adjacent 64-bit double-word (or the same double-word as the value) by applying shift-and-mask.
Three new registers control the shift-and-mask process: an offset register indicates which double word the tag will be extracted from, a shift register encodes the starting point of the type field within the double work, and the mask register holds an 8-bit mask to extract a type tag of the same width.
There are four additional instructions we’ve not yet mentioned:
thdlsets the value of the misprediction handler registertchkperforms type checking without value calculationtgetreads the type of a registertsetwrites the type of a register
Using our new super powers, here’s how the original ADD bytecode from above is transformed:

Here’s the full summary of the extended ISA:
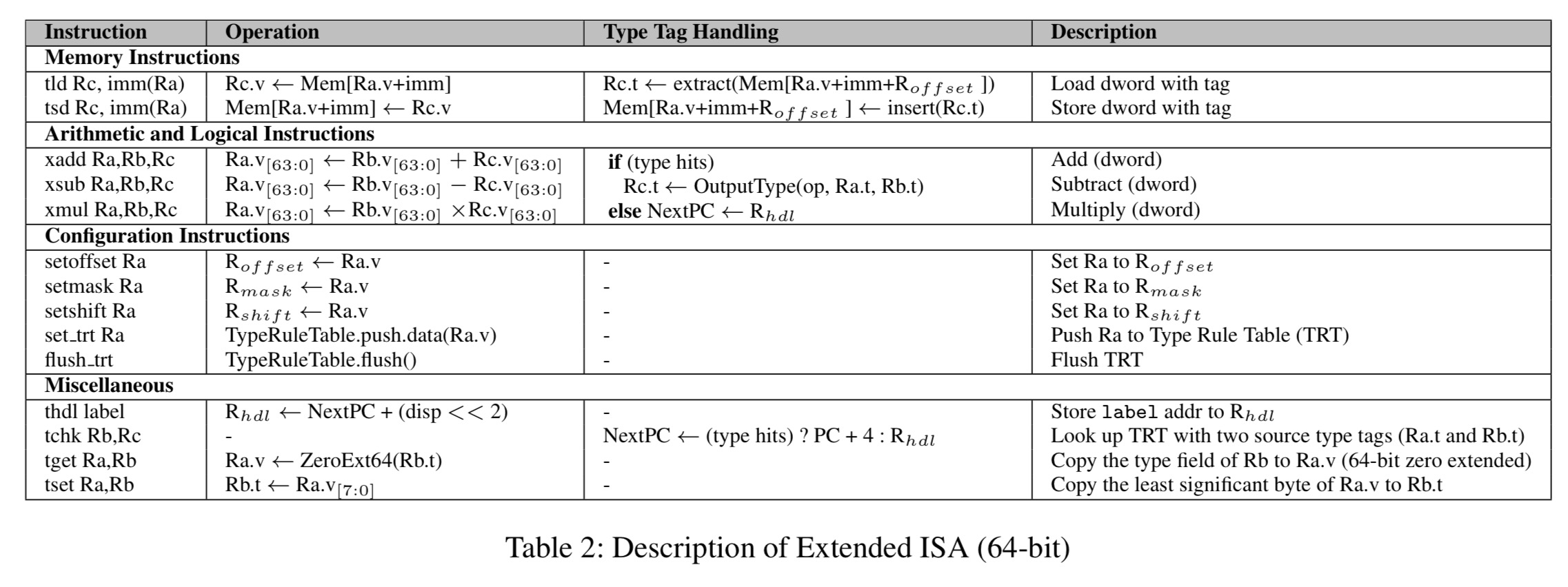 (Click for larger view).
(Click for larger view).
Typed Architectures – Pipeline
The extended ISA is implemented with a pipeline structure that looks like as follows:
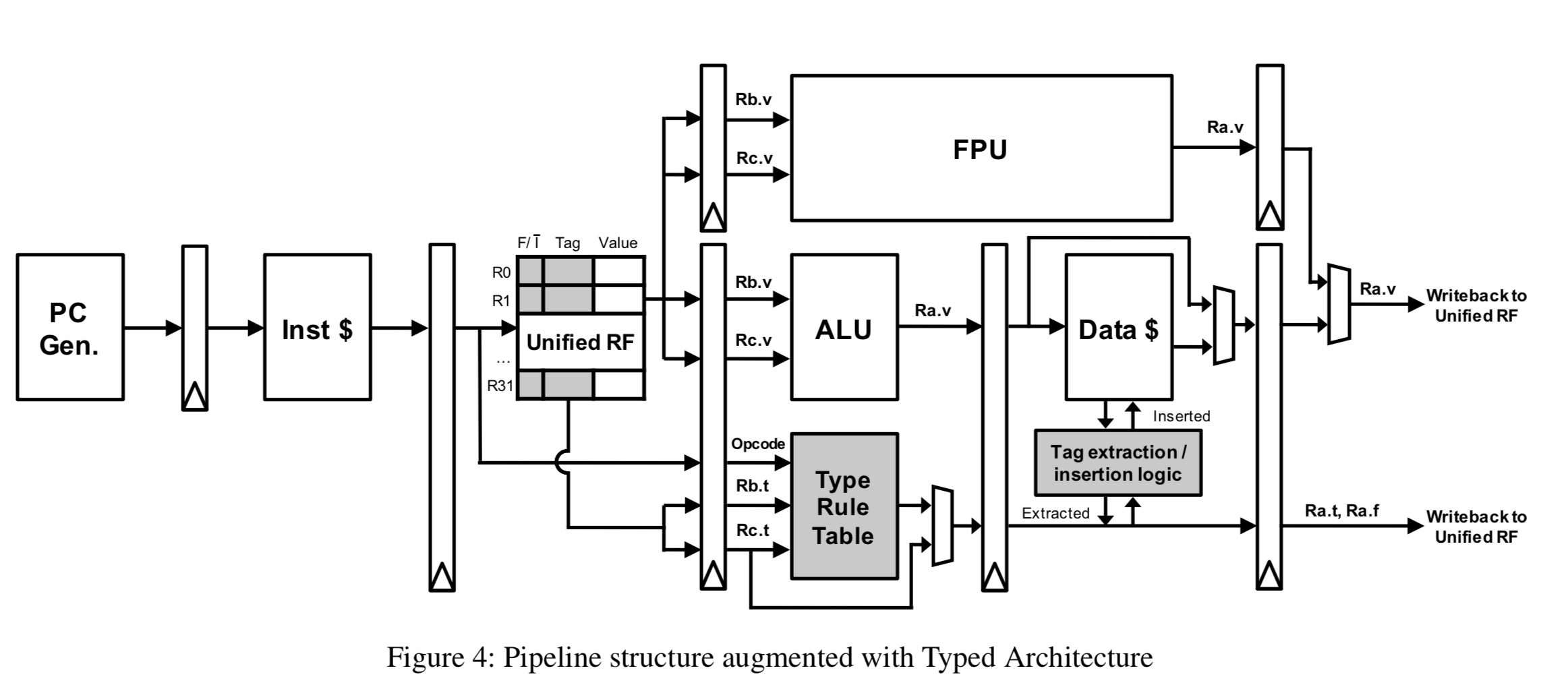
We add a unified register file, a Type Rule Table, and a tag extract/insert logic to the baseline (shaded in gray).
The execution of, say xadd, differs from a static add instruction in three ways:
- It selects the calculation path (integer ALU or FP ALU) at the decode stage
- It accesses the Type Rule Table for type checking in hardware. If it hits, the output tag is propagated to the writeback stage and finally to the type tag of the destination register. If not, it goes through the type misprediction path.
- There are type mispredictions with tagged ALU instructions. The handler is simply the original code with software-based type checking.
Typed Architectures – Memory access
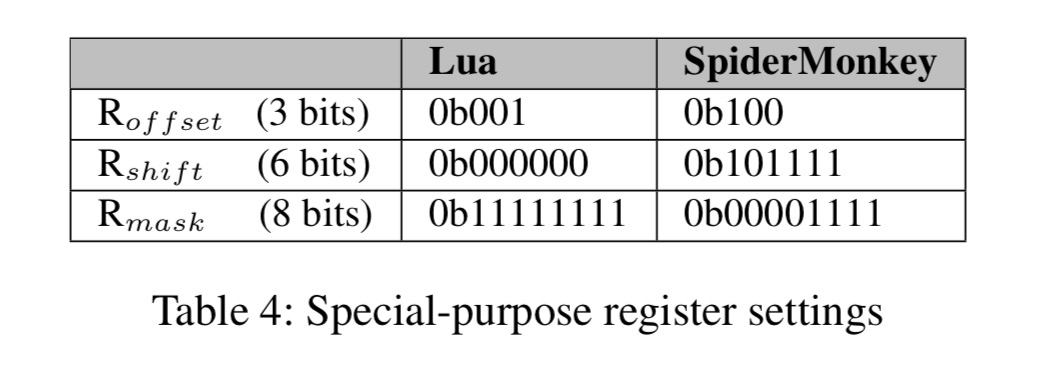
The data layouts for storing tag-value pairs differs across languages and implementations. The three special purpose registers controlling the shift-and-mask operation can be customised per language to obtain the desired behaviour. As an example, here are the register settings for Lua and SpiderMonkey (FireFox JavaScript engine).
Implementation and evaluation
For both Lua and SpiderMonkey, bytecode profiling is used to identify the top five hot bytecodes which execute type guards. These are then retargeted to Typed Architecture.
Our model is based on open-source 64-bit RISC-V v2 Rocket core with the default RISC-V/Newlib target. We have integrated custom performance counters for performance analysis, such as I-cache miss rate, branch misprediction rate, and so on. It is a fully synthesizable RTL model written in Chisel language. This model is compiled into Verilog RTL, and then synthesized for FPGA emulation and area/power estimation. We use Xilinx ZC706 FPGAs for instruction and cycle counts. Table 6 (below) summarizes the parameters used for evaluation.
Here we see the overall speedups obtained for Lua and JavaScript across a range of benchmarks:
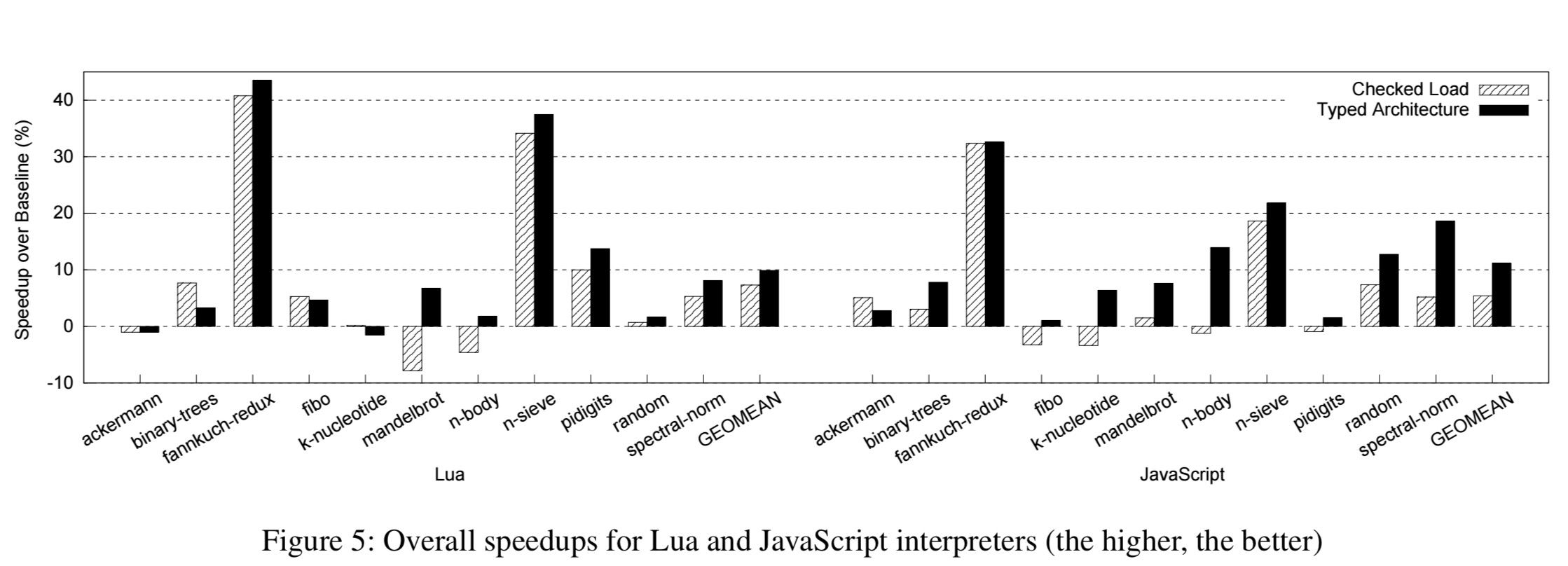
Typed Architecture achieves geomean speedups of 9.9% and 11.2% for Lua and SpiderMonkey, respectively, with maximum speedups of 43.5% and 32.6%.
A key source of performance improvement is the reduction in dynamic instruction count.
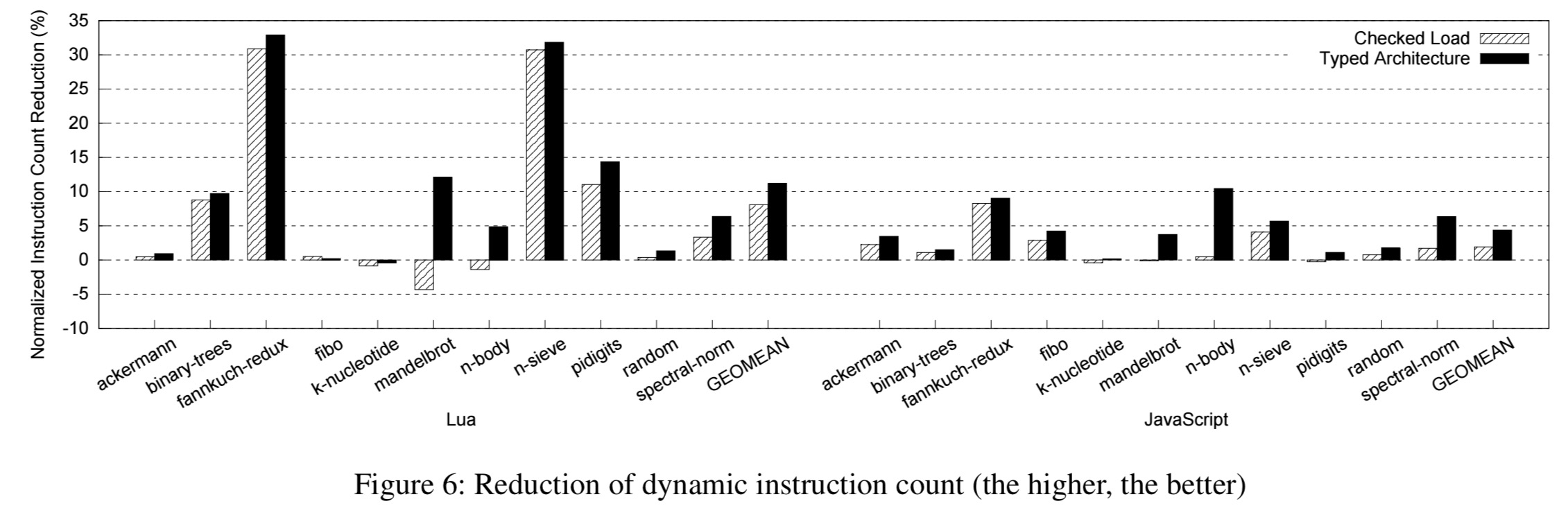
Type Architecture also reduces resource pressure on the branch predictor, instruction cache, registers, and so on. “This also brings significant benefits to some benchmarks.”
The total area and power of Rocket Core augmented with TypedArchitecture are increased by 1.6% and 3.7% respectively. Combined with the speedups, the EDP (energy-delay product)is improved by 16.5% for Lua and by 19.3% for JavaScript.

Speaking of Symbolics, Lucid Lisp on stock hardware won out. Due to enthusiasm for typed architectures at the time, Sparc had (maybe still has) a couple of typed instructions similar to this paper, but those were never much used in practice. The conclusion of that time was that reasonably intelligent compilers for conventional architectures won out because the new instructions didn’t provide that great an edge and because conventional hardware outpaced the specialists in a generation or two.
(See this for more on Lucid Lisp: http://dreamsongs.com/Files/cp.pdf )
So it might be interesting to consider what has changed since then. Or has anything changed? While a Raspberry Pi might seem underpowered, it still has perhaps 128x the memory of a Symbolics machine or the Unix workstation targets of Lucid, or more. So perhaps compilation still could work well? LuaJIT seems to work well on gaming devices. On the other hand, Python appears somewhat intractable to compilers so far.
An alternative would be type-checking JavaScript, Python, etc. at compile-time using something like algebraic subtyping :))) https://www.cl.cam.ac.uk/~sd601/thesis.pdf