Omid, reloaded: scalable and highly-available transaction processing Shacham et al., FAST ’17
Omid is a transaction processing service powering web-scale production systems at Yahoo that digest billions of events per day and push them into a real-time index. It’s also been open-sourced and is currently incubating at Apache as the Apache Omid project. What’s interesting about Omid is that it adds transaction processing as a layer on top of an underlying distributed key-value store. In theory the underlying store is pluggable, but in practice it looks pretty tied to Apache HBase (and that’s the implementation you’ll find in Apache Omid). The idea is similar in spirit to the ‘bolt-on’ designs for strengthening consistency guarantees that we’ve looked at in previous editions of The Morning Paper.
Omid is designed for industrial use, leading to two high-level design principles:
- Build on top of battle-tested key-value store technology (don’t reinvent this layer)
- Strive for simplicity in operations: it should be easy to deploy, support, maintain, and monitor in production. This goal led the team to a design with a single centralized transaction manager (running in a primary-backup configuration).
That second design point sounds distinctly unfashionable of course, but Omid works hard to restore scalability for throughput-oriented workloads (you won’t be using Omid for any low latency requirements at the moment), and continued availability in the face of failure. Still, it’s interesting to compare the Omid design to the HopFS design that we looked at last week.
Omid scales to hundreds of thousands of transactions per second, over multi-petabyte shared storage. It supports snapshot isolation (not the full strength serializability). This means you can still see write skew under Omid – see “A Critique of ANSI SQL Isolation Levels” for all the gory details.
It’s helpful to understand how Omid is deployed at Yahoo for the Sieve content management system to orient ourselves. Apache HBase is used to store both application data and the commit table (CT, we’ll look at this soon…). HBase, the primary and backup transaction manager nodes, and ZooKeeper are all deployed on separate dedicated machines. HBase tables are sharded into multiple regions (10 for Sieve), managed by region servers (5 for Sieve). HBase is deployed on top of HDFS with 3-fold replication, and petabytes of data under management.
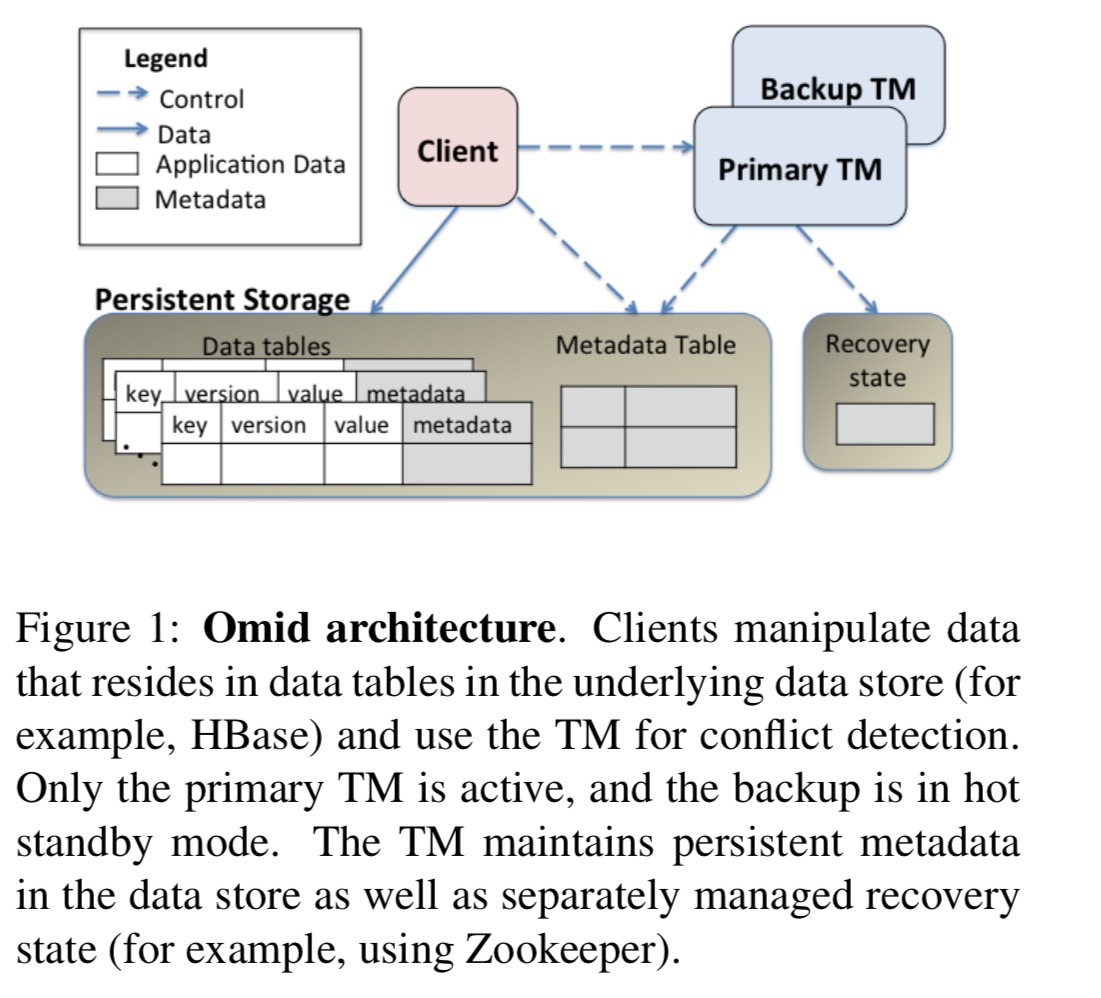
High-level architecture
Omid stores all data (and it’s own transaction management data) in an HBase data plane. This provides persistence, scalability and high availability for data out of the box. Omid itself manages the transaction control plane via a centralized transaction manager (TM). The TM performs version (timestamp) allocation, conflict detection, and persistent logging of commits. Transaction metadata is stored in HBase, but conflict management is done entirely in RAM in the TM node (scale-up, rather than scale-out).
The transaction metadata consists of a commit table (CT) with information on committed transactions, and an additional commit field (cf) added to every key-value pair in the data store.
Transaction processing
Transactions move through three states: initiated, committed, and completed. Transaction processing is accomplished via a curious dance between clients and the TM. Let’s walkthrough a sample transaction that reads one value, writes one value, and then commits.
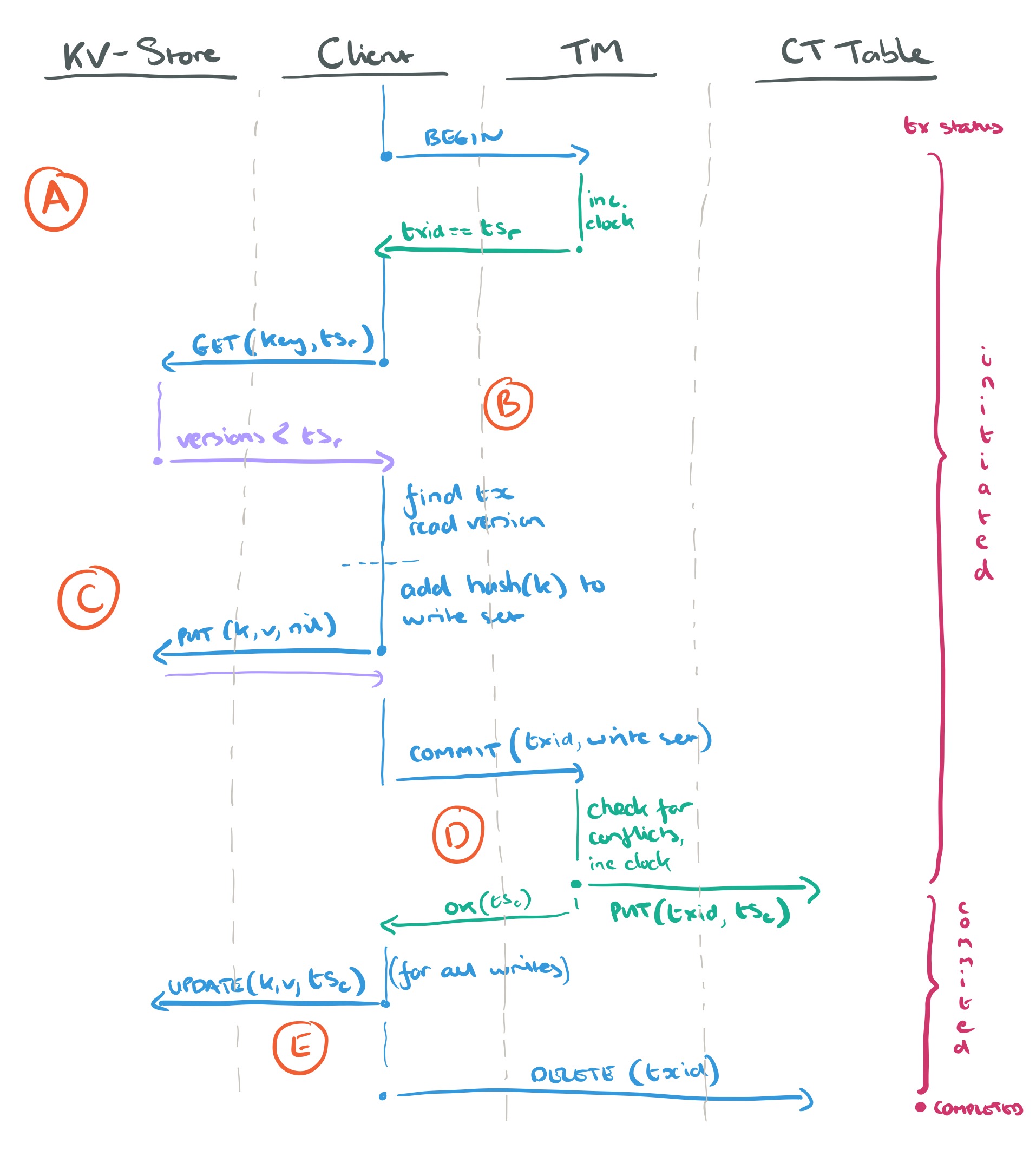
- (A) The client tells the TM it wants to begin a new transaction. The TM increments its logical clock and returns the clock timestamp which is used as both the transaction id
and the transaction read timestamp
.
- (B)The client wants to read the value of a key k. It issues a GET request to the k-v store, which must support multi-versioning. The
nilthough then this is a tentative write from some other transaction. It may be though that that transaction has actually committed and just not updated the commit-field value yet, to catch this scenario, the client checks the commit table following a get tentative value procedure. This procedure will make more sense once we’ve seen how commit works, so I’ll come back to it then. - (C) The client wants to PUT a value for some key. It adds the hash of the key to its write set and then PUTs the key-value pair with a
nilcommit-field value to indicate that this write is still tentative pending transaction commit. - (D)The client now decides to commit the transaction. It sends the transaction id and the write set to the transaction manager. The transaction manager updates its clock and assigns a commit timestamp,
. The transaction manager checks for conflicts to be sure that none of the keys in the write set have versions larger than
- (E) When the clients gets the OK back from the TM, it updates the conflict-field value to

A background cleanup process helps old (crashed or otherwise slow) transactions complete. Old versions of data items are also periodically tidied up by a background cleaner using a low water mark. If a transaction with an id smaller than the low water mark attempts to commit it will be aborted.
Let’s now return to the get tentative value procedure to be followed when the client reads a version with a nil commit field value. We need to take care with the window between the transaction being committed and completed. The client checks in the commit table for a row with the corresponding GetTentativeValue procedure in the pseudo-code below:

HA
HA is based on a primary-backup scheme with timeouts. The timeout is set relatively low for fast recovery. The tricky part is when the backup performs failover while the primary is still operational – we have two primaries at this point.
To this end, the primary TM actively checks if a backup has replaced it, and if so, “commits suicide”, i.e., halts. However, it is still possible to have a (short) window between the failover and the primary’s discovery of the existence of a new primary when two primary TMs are active.
Three properties are enforced to ensure that this cannot cause difficulties:
- All timestamps assigned by TM-2 exceed all those assigned by TM-1 (timestamp ranges are allocated in large chunks, called epochs, and managed as shared objects in ZooKeeper).
- After a transaction t begins, no other transaction that will end up with a commit timestamp earlier than t‘s read timestamp is allowed to update any additional data items.
- When a transaction reads a tentative update, it is able to determine whether this update will be committed with a timestamp smaller than its read timestamp or not.
To handle the third scenario, an invalidation mechanism is used.
… when a read encounters a tentative update whose txid is not present in the CT, it forces the transaction that wrote it to abort. We call this invalidation and extend the CT’s schema to include an invalid field to this end. Invalidation is performed via an atomic put-if-absent (support by HBase’s checkAndMutate API) to the CT, which adds a record marking that the transaction has “invalid” status. The use of an atomic put-if-absent achieves consensus regarding the state of the transaction.
A lease mechanism is used to ensure that a TM only needs to additionally check for invalidation if a lease expires while a commit record is in flight. See section 6 in the paper for full details of the scheme.
Recovery after failure takes around 4 seconds.
Futures
Since becoming an Apache Incubator project, Omid is witnessing increased interest, in a variety of use cases. Together with Tephra, it is being consider for use by Apache Phoenix – an emerging OLTP SQL engine over HBase storage. In that context, latency has increased importance. We are therefore developing a low-latency version of Omid that has clients update the CT instead of the TM, which eliminates the need for batching and allows throughput scaling without sacrificing latency.
Why does Apache have both Omid and Tephra incubating? From the Omid proposal document: “Very recently, a new incubator proposal for a similar project called Tephra, has been submitted to the ASF. We think this is good for the Apache community, and we believe that there’s room for both proposals as the design of each of them is based on different principles (e.g. Omid does not require to maintain the state of ongoing transactions on the server-side component) and due to the fact that both -Tephra and Omid- have also gained certain traction in the open-source community.” Let all the flowers bloom :).
