MaMaDroid: Detecting Android malware by building Markov chains of behavioral models, Mariconti et al., NDSS 2017
Pick any security conference of your choosing, and you’re sure to find plenty of papers examining the security of Android. It can paint a pretty bleak picture, but at the same time the Android ecosystem also seems to have the most active research when it comes to detecting and preventing malware. Today’s choice comes from that side of the fence. I must admit, I was surprised at how well the technique works: it seems on the surface that a lot of important detailed information is abstracted away, but it turns out that doesn’t matter and actually helps to make the solution more robust. One to file away in the memory banks, as I’m sure the ‘less is more’ realisation must have applicability in other circumstances too.
MaMaDroid is a system for detecting malware on Android.
We evaluate MaMaDroid’s accuracy on a dataset of 8.5K benign and 35.5K malicious apps collected over a period of six years, showing that it not only effectively detects malware (with up to 99% F-measure), but also that the model built by the system keeps its detection capabilities for long periods of time (on average, 87% and 73% F-measure, respectively, one and two years after training).
The problem: there’s a lot of Android malware out there
There’s also a lot of Android out there! “In the first quarter of 2016, 85% of smartphone sales were devices running Android.” That ubiquity makes it a popular attack target. Detecting malware on-device is battery draining, so Android malware detection is typically performed by Google in a centralized fashion by analysing apps that are submitted to the Play store.
However, many malicious apps manage to avoid detection (see e.g., ‘Google Play has hundreds of Android apps that contain malware‘), and anyway Android’s openness enables manufacturers and users to install apps that come from third-party market places, which might not perform any malware checks at all, or anyway not as accurately.
Malware detection needs to be relatively efficient, and it also needs to be robust over time – as new APIs are added into the platform, and older ones deprecated and removed, we’d like the detection techniques to continue working well.
Analysing call sequences
MaMaDroid works in four phases: first the byte code is examined to recover the call graph, then sequences of API calls are extracted from the graph. These sequences are modelled as Markov chains representing the probability that a call will be made to a certain destination when in a given state. The probabilities in the Markov model then become the feature vector for a classifier that finally pronounces the app as malware or not.
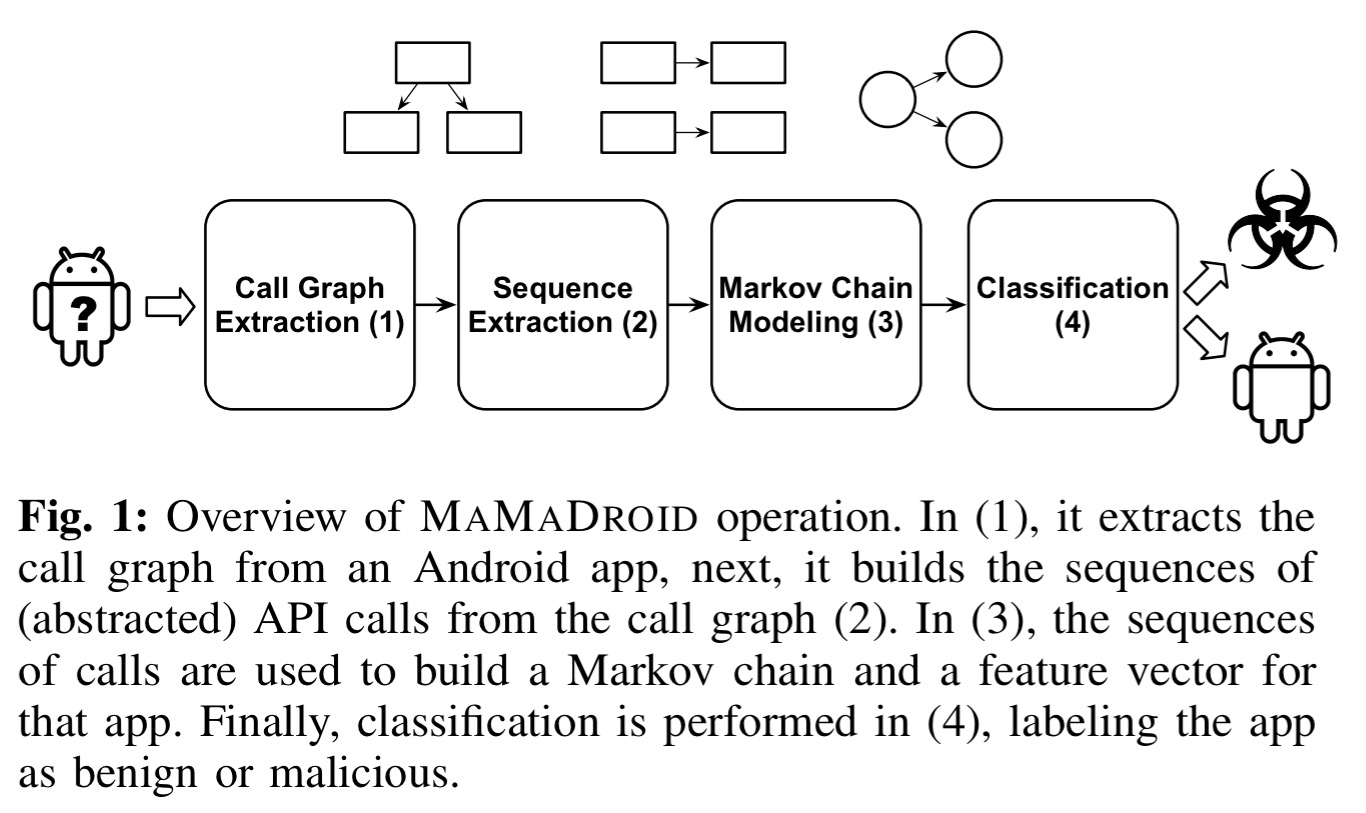
The static analysis to extract the call graph is done using the Soot framework, in conjunction with FlowDroid. Starting with the nodes in the call graph that have no incoming edges (entry nodes), the paths reachable from each entry node are traced (which may mean exploring multiple branches of conditionals etc.).
The set of all paths identified during this phase constitute the sequences of API calls which will be used to build a Markov chain behavioural model and to extract features.
Here comes the part that initially surprised me: instead of retaining the raw API call details (e.g. to class or even method), the nodes are abstracted either to package or even just to family. In package mode, a node in the graph is abstracted to just its package name (there are 243 Android packages, plus 95 from the Google API, plus the special package names ‘self-defined’ for any user-defined code, and ‘obfuscated’ for obfuscated package names. In family mode, every single call node is reduced down to just one of 11 possible values: android, google, java, javax, xml, apache, junit, json, dom, self-defined, and obfuscated. (I.e., the root of the package name). Even in family mode, the malware detection works surprisingly well!
This allows the system to be resilient to API changes and achieve scalability. In fact, our experiments, presented in section III, show that, from a dataset of 44K apps, we extract more than 10 million unique API calls, which would result in a very large number of nodes, with the corresponding graphs (and feature vectors) being quite sparse.
Now that we have these call sequences we can build a Markov chain where each package/family is a state node, and transitions represent the probability (based on simple occurrence counts) of moving from one state to another.
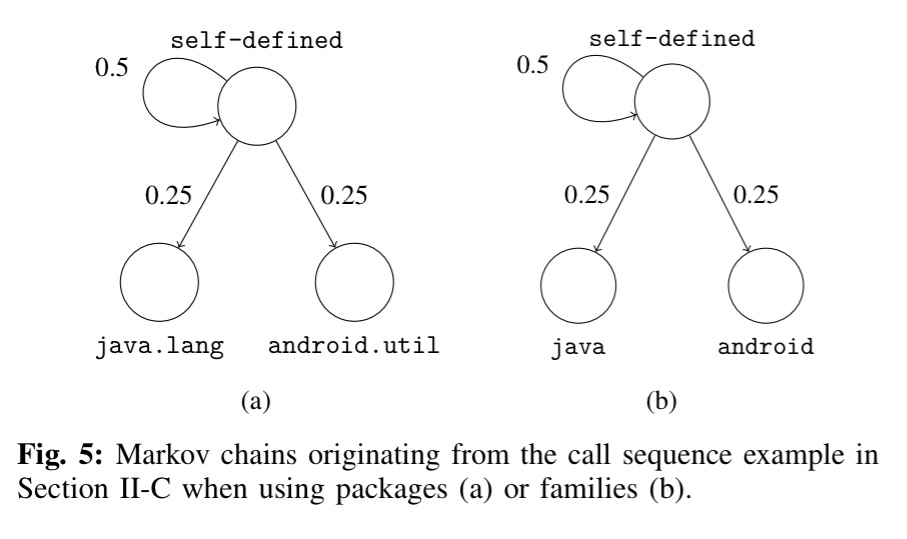
Next, we use the probabilities of transitioning from one state (abstracted call) to another in the Markov chain as the feature vector of each app. States that are not present in a chain are represented as 0 in the feature vector. Also note that the vector derived from the Markov chain depends on the operational mode of MAMADROID. With families, there are 11 possible states, thus 121 possible transitions in each chain, while, when abstracting to packages, there are 340 states and 115,600 possible transitions.
Given this feature vector, a classifier is trained: Random Forests, 1-Nearest Neighbour, 3-Nearest Neighbour, and SVMs are all experiment with. SVMs performed the worst and are not shown in the results. The authors also experiment with applying PCA (Principle Component Analysis) to reduce the feature space.
Evaluation
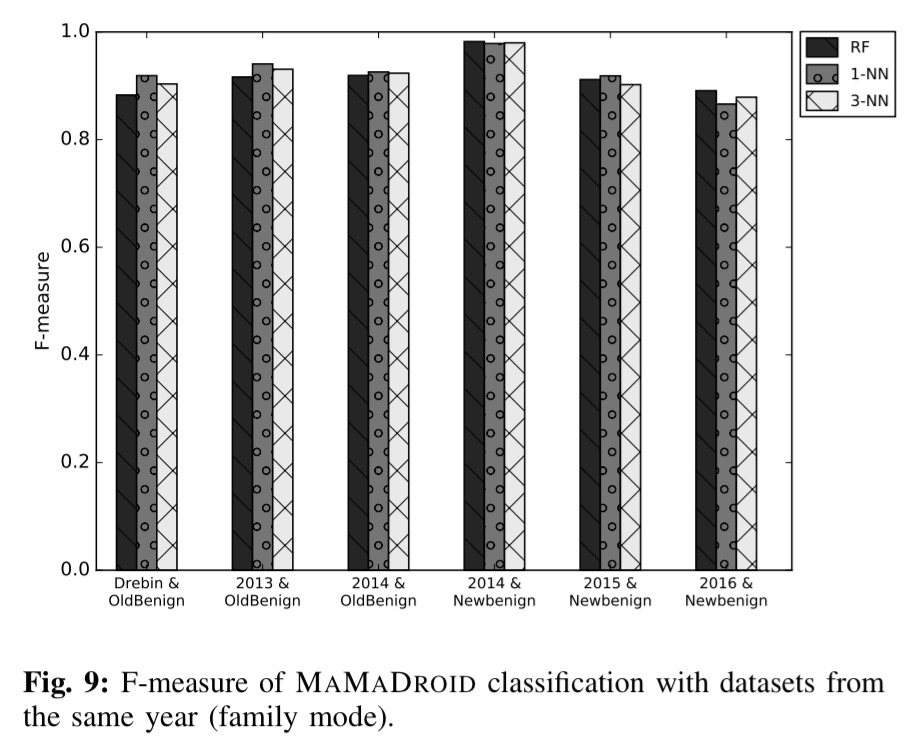
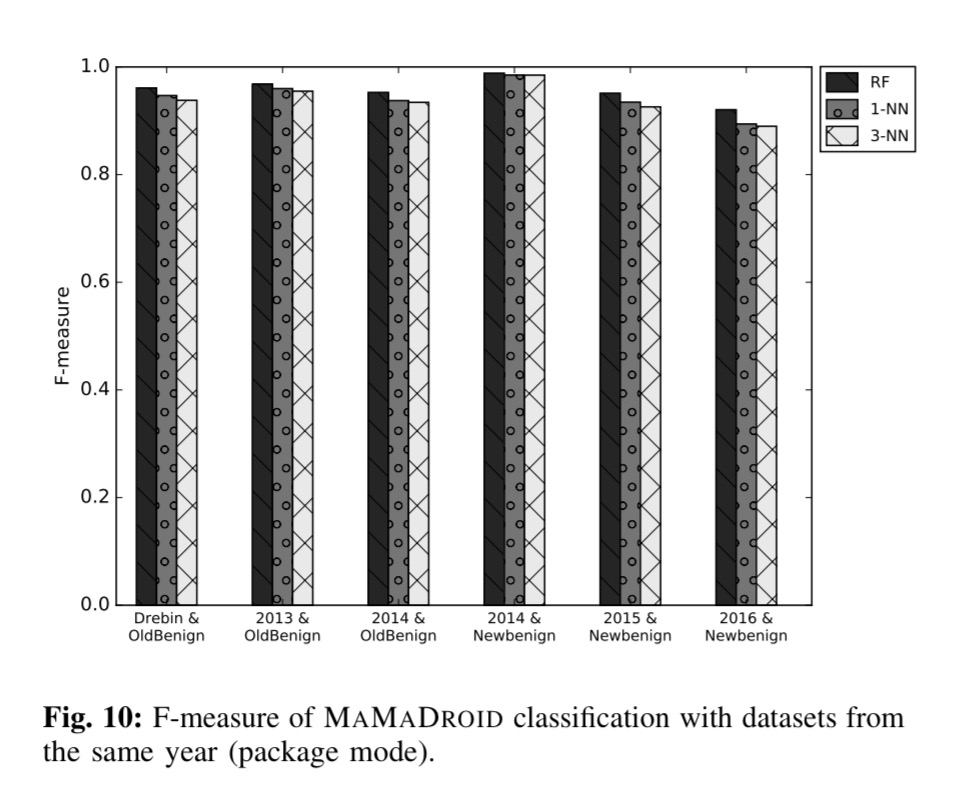
The authors gathered a collection of 43,490 Android apps, 8,447 benign and 35,493 malware apps. This included a mix of apps from October 2010 to May 2016, enabling the robustness of classification over time to be explored. All experiments used 10-fold cross-validation (do 10 times: shuffle the dataset, divide it into 10 parts, train using 9 of them, and test on the other one). Accuracy is presented using the F-score ( 2 * precision * recall / precision + recall ).
Here are the resulting scores when using ‘family’ mode:
and the more accurate ‘package’ mode:
As Android evolves over the years, so do the characteristics of both benign and malicious apps. Such evolution must be taken into account when evaluating Android malware detection systems, since their accuracy might significantly be affected as newer APIs are released and/or as malicious developers modify their strategies in order to avoid detection. Evaluating this aspect constitutes one of our research questions, and one of the reasons why our datasets span across multiple years (2010–2016).
To see how well MaMaDroid does in this scenario, the team used older samples as training sets, and tested on newer samples. Here are the results for year gaps of up to four years (for both family mode and package mode):
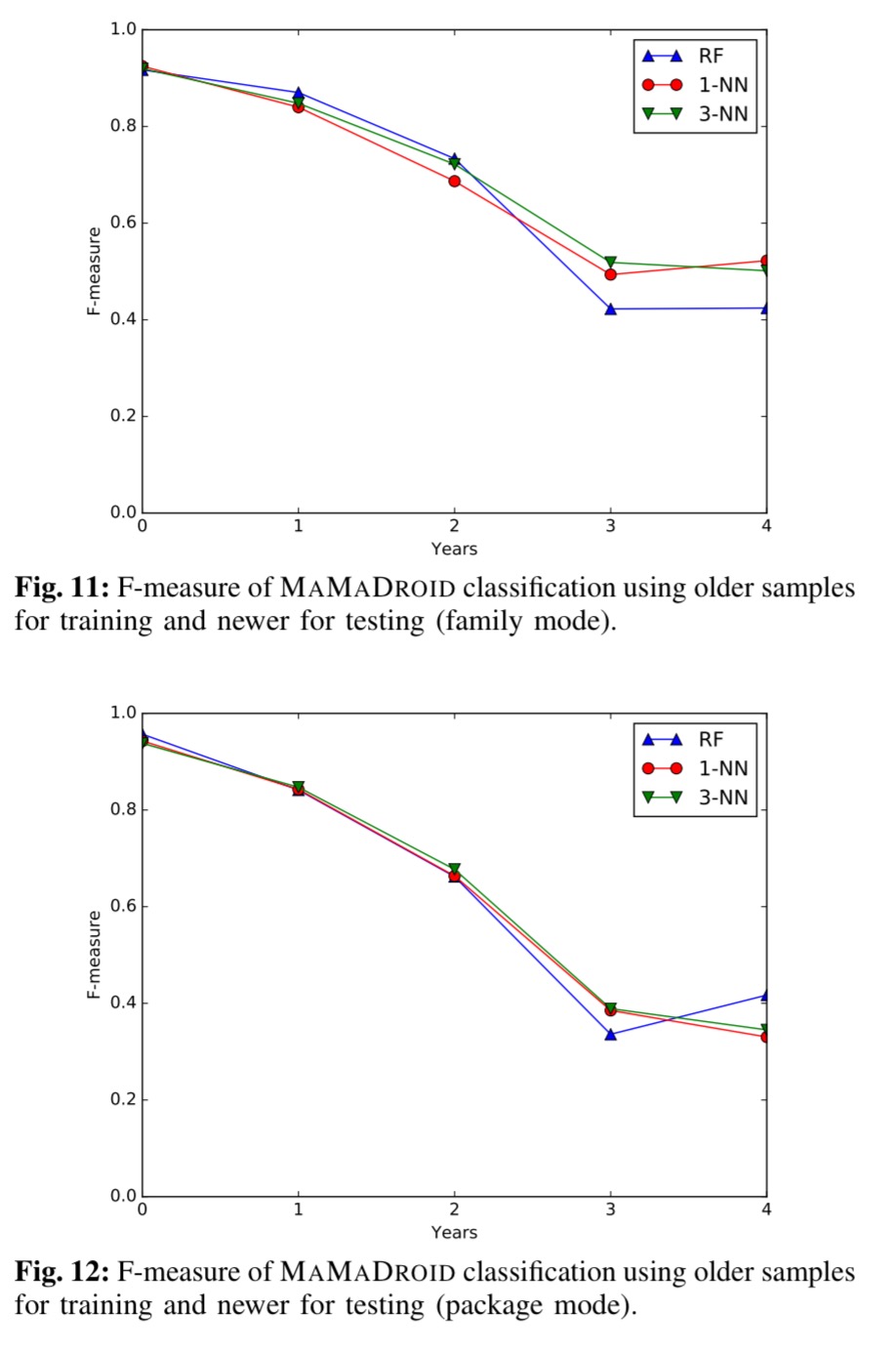
We also need to test the reverse direction – can older malware be detected by a system training using newer samples? The answer is yes, with similar F-measure scores across the years (tested up to four year gaps) ranging from 95-97% in package mode.
In family mode, it takes 11 (malware) and 23 (benign) seconds on average to classify an app from start to finish. In package mode, this goes up to 14 and 34 seconds respectively. Most of the time is spent on call graph extraction. With an estimate of up to 10,000 apps a day being submitted to Google Play, that’s a combined execution time of about one-and-a-half hours to scan them all.
Our work yields important insights around the use of API calls in malicious apps, showing that, by modeling the sequence of API calls made by an app as a Markov chain, we can successfully capture the behavioral model of that app. This allows MAMADROID to obtain high accuracy overall, as well as to retain it over the years, which is crucial due to the continuous evolution of the Android ecosystem.

One thought on “MaMaDroid: Detecting Android malware by building Markov chains of behavorial models”
Comments are closed.