Apache Hadoop YARN: Yet Another Resource Negotiator Vavilapalli et al., SoCC 2013
The opening section of Prof. Demirbas’ reading list is concerned with programming the datacenter, aka ‘the Datacenter Operating System’ – though I can’t help but think of Mesosphere when I hear that latter phrase. There are four papers: in publication order these are “Apache Hadoop YARN” (which we’ll be looking at today), “Large-scale cluster management at Google with Borg“, “Firmament: Fast, Centralized Cluster Scheduling at Scale“, and “Slicer: Auto-Sharding for DataCenter Applications.”
The Borg paper of course describes the cluster management system that Google have been using for the last decade, and that gave us Kubernetes. Borg cells are on the order of 10,000 machines, and controlled by a highly available Borgmaster. One of the primary goals is to increase utilisation. Admission control sits in front of the scheduler to avoid overload, and manage user quotas. Borg jobs consist of multiple tasks, each running the same process.
Firmament is a scheduler (with a Kubernetes plugin under development) that balances the high-quality placement decisions of a centralised scheduler with the speed of a distributed scheduler. It managed to keep pace with the scheduling requirements of a 12,500 node cluster Google workload, at 300x real speed!
Slicer is Google’s auto-sharding service that separates out the responsibility for sharding, balancing, and re-balancing from individual application frameworks.
The YARN paper was published in 2013, based on a then-beta version of YARN. In this write-up therefore, I’m going to focus on the discussion of the requirements that drove the design of YARN and the high-level approach. For an up-to-date description of the details, see the Apache Hadoop YARN documentation.
How YARN came to be – the back story
Apache Hadoop was initially based on infrastructure for web crawling, using the now well-known MapReduce approach. Yahoo! adopted it for this purpose in 2006.
…it’s execution architecture was tuned for this use case, focusing on strong fault tolerance for massive, data-intensive computations.
Hadoop increasingly came to be the central repository of data within organisations, leading to a desire to run other kinds of applications on top of that data. As use of Hadoop extended beyond the web crawling use case, developers started to stretch the MapReduce programming model beyond its intended use cases – for example, submitting ‘map only’ jobs to spawn processes and using clever workarounds to sidestep MapReduce limits…
The limitations of the original Hadoop architecture are, by now, well understood by both the academic and open-source communities.
A new approach was needed to balance the diverse needs of different cluster users and applications. Yahoo! developed a private-cloud like ‘Hadoop-on-demand’ (HoD) capability to spin up Hadoop compute clusters on demand to process data in a shared HDFS. This led to ‘middling’ (i.e., not good enough) resource utilization in the end, and was ultimately retired…
While users were fond of many features in HoD, the economics of cluster utilization forced Yahoo! to pack its users into shared clusters… Ultimately HoD had too little information to make intelligent decisions about its allocations, its resource granularity was too coarse, and its API forced users to provide misleading constraints to the resource layer.
Moving to shared clusters though quickly exposed weaknesses in the JobTracker that became a single point of failure. A JobTracker failure would result in the loss of all running jobs in a cluster and require users to manually recover their workflows.
Pressure on the MapReduce programming model (which isn’t well suited to some kinds of large scale computations such as iterative machine learning and graph processing) led to users rolling their own solutions:
Hadoop’s wide deployment inside Yahoo! and the gravity of its data pipelines made these tensions irreconcilable. Undeterred, users would write “MapReduce” programs that would spawn alternative frameworks. To the scheduler they appeared as map-only jobs with radically different resource curves, thwarting the assumptions built into the platform and causing poor utilization, potential deadlocks, and instability.
YARN’s architecture is informed by all of these experiences at Yahoo!. It separates resource management from the programming model, and delegates many scheduling-related functions to per-job components.
In this new context, MapReduce is just one of the applications running on top of YARN. This separation provides a great deal of flexibility in the choice of programming framework…
10 requirements for a resource management infrastructure
Based on their experiences at Yahoo!, and with input from the community, the designers of YARN identified 10 requirements that a resource management infrastructure for Hadoop needed to satisfy:
- Scalability – the original driver for Hadoop MapReduce, and still a key concern.
- Support for Multi-tenancy, such that multiple applications and users (with diverse use cases) can all share the same pool of resources in a cluster.
- The ability to upgrade the Hadoop platform itself without requiring all application programs to simultaneously upgrade – denoted in the paper as Serviceability.
- Efficiency through the placement of compute tasks close to the data that they need – Locality awareness.
- High cluster utilization (recall this was the dominant reason for retiring HoD).
- Reliability/Availability – “operating a large, multi-tenant Hadoop cluster is hard…” a lot of effort goes into monitoring jobs for dysfunction and avoiding the need for manual interventions.
- As larger clusters are typically multi-tenant, an authorization model offering Secure and auditable opration.
- Support for programming model diversity.
- A flexible resource model that is not tied to just ‘map’ and ‘reduce’ slots. “Fungible resources complicate scheduling, but they also empower the allocator to pack the cluster more tightly.”
- Given the massive install base, Backward compatibility.
Out of these, YARN was born, and the rest, as they say, is history.
High level design and division of responsibilities
To address [the requirements discussed above], YARN lifts some functions into a platform layer responsible for resource management, leaving coordination of logical execution plans to a host of framework implementations. Specifically, a per-cluster ResourceManager (RM) tracks resource usage and node liveness, enforces allocation invariants, and arbitrates contention among tenants.
The ResourceManager is a centralized service with a global view of cluster resources. It allocates leases called containers (which can nowadays be mapped to Docker containers if so desired) to applications to run on particular nodes. Each node runs a daemon process called the NodeManager which the ResourceManager coordinates with. NodeManagers are responsible for monitoring resource availability, reporting faults, and managing container lifecycles.
Jobs are submitted to the ResourceManager, and if admitted to the cluster are passed to a scheduler to be run.
The ApplicationMaster is the “head” of a job, managing all lifecycle aspects including dynamically increasing and decreasing resources consumption, managing the flow of execution (e.g., running reducers against the output of maps), handling faults and computation skew, and performing other local optimizations. In fact, the AM can run arbitrary user code, and can be written in any programming language since all communication with the RM and NM is encoded using extensible communication protocols.
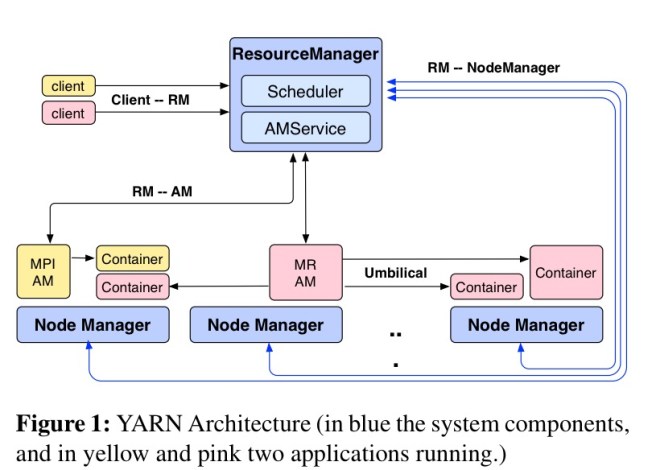
To get the resources it needs, an AM issues requests to the ResourceManager. The ResourceManager attempts to satisfy these based on availability and scheduling policies. The Application Master takes on a lot of the burden of supporting a given programming model, including planning the most efficient execution strategy based on the resources made available to it.
Since the AM is itself a container running in a cluster of unreliable hardware, it should be resilient to failure. YARN provides some support for recovery, but because fault tolerance and application semantics are so closely intertwined, much of the burden falls on the AM.
At the time the paper was written, the ResourceManager remained a single point of failure in YARN’s architecture. ResourceManager restart was subsequently introduced in Hadoop 2.4, and extended in 2.6. As of Hadoop 2.4 it is also possible to configure active/passive ResourceManager pairs for HA.
The end result of all the work on YARN was a system that provides greater scalability, higher efficiency, and the ability for a large number of different frameworks to efficiently share a cluster.
Finally, in the related work section, there’s also an interesting paragraph giving the authors’ perspective on YARN as compared to Mesos:
While Mesos and YARN both have schedulers at two levels, there are two very significant differences. First, Mesos is an offer-based resource manager, whereas YARN has a request-based approach. YARN allows the AM to ask for resources based on various criteria including locations, allows the requester to modify future requests based on what was given and on current usage. Our approach was necessary to support the location based allocation. Second, instead of a per-job intra-framework scheduler, Mesos leverages a pool of central schedulers (e.g., classic Hadoop or MPI). YARN enables late binding of containers to tasks, where each individual job can perform local optimizations, and seems more amenable to rolling upgrades (since each job can run on a different version of the framework). On the other side, per-job ApplicationMaster might result in greater overhead than the Mesos approach.

A good write up on (once again) topical topic — some thoughts, in reference to the Firmament paper https://www.usenix.org/system/files/conference/osdi16/osdi16-gog.pdf
“When scheduling workloads that consist exclusively of short, sub-second tasks, Firmament scales to over 1,000 machines, but suffers overheads for task runtimes below 5s at 10,000 machines.”
Going forward, as performance improvement depends on dividing programs into ever smaller concurrent tasks/microservices/actors, the individual task runtimes will typically be far less than 5 seconds, while ever increasing numbers of such micro-tasks will correspondingly be needed for each program instance, of which there should also be growing numbers sharing growing resource pools (clusters of growing numbers of execution units). Thus, the scenario, per quote above, where Firmament’s performance radically degrades, will increasingly be the new norm operation scenario for cloud computing.
See also e.g. Figure 8: When high performance is most needed, i.e., at times of high, often unexpected, loads of events (e.g. sensor alerts) to process, when there thus is need for all (or at least, more than 90%) of the cluster capacity, the plain scheduling algorithm runtime increases to tens of seconds. That is, with this assumed state-of-the-art (as of 2016) system, it can take minutes of waiting time before e.g. response time critical sensor messages are even placed for processing – whereas for instance the 5G standard (and actual industrial, safety and many interactive system) performance requirements call for millisecond rate response to such (e.g. industrial IoT) sensor alerts.
Where do we go from here?
Great post.. I learnt about apache yarn clearly from this article and got new information about hadoop.. thanks a lot for sharing this post to us..
hadoop training and placement in chennai | hadoop training chennai
Your project topics gave me the idea on which topic I have to submit my assignment. Thank you guys!
Statistics Assignment Help