Interaction networks for learning about objects, relations and physics Google DeepMind, NIPS 2016
Welcome back! There were so many great papers from OSDI ’16 to cover at the end of last year that I didn’t have a chance to get to NIPS. I’m kicking off this year therefore with a few of the Google DeepMind papers from NIPS ’16 in December.
Last year we looked at ‘Building machines that learn and think like people’ which talked about some of the important differences between how computers learn and how humans learn. In particular, machine learning is anchored in statistical pattern recognition whereas we conjecture that humans learn by building models of the world that we reason over. An intuitive understanding of basic physics begins to develop in humans from about 2 months old: solidity, continuity, paths of motion, and so on. In ’Towards deep symbolic reinforcement learning’, Garnelo et al. argue for a combination of deep learning and symbolic reasoning to accommodate this kind of knowledge. In today’s paper, the Google DeepMind team demonstrate a pure deep learning approach to learning a physics engine…
Reasoning about objects, relations, and physics is central to human intelligence, and a key goal of artificial intelligence…
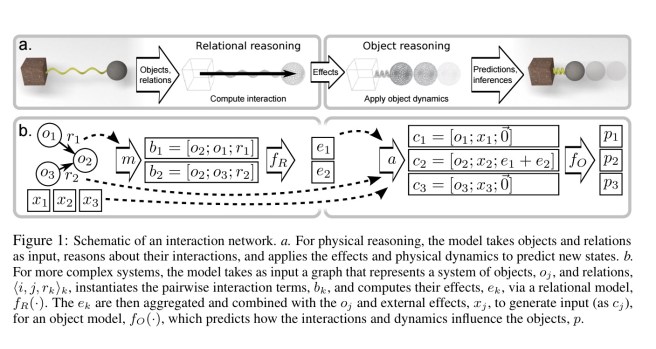
Interaction networks deal with objects and the relations between them. An object-centric model learns the behaviour of individual objects and the aggregated effects of the interactions they participate in. A relation-centric model learns the behaviours of two or more interacting objects. The input to an interaction network is a graph of objects and the relations between them (learning that graph from visual representations of a scene is a separate challenge!).
Decomposing complex systems into objects and relations, and reasoning about them explicitly, provides for combinatorial generalisation to novel contexts, one of the most important future challenges for AI, and a crucial step toward closing the gap between how humans and machines think.
In the sections that follow we’ll look at : (a) the abstract structure of an interaction network (IN) – i.e., how it models the real world; (b) an embodiment of INs using deep neural network building blocks; and (c) examples of the kind of things that INs were able to learn during evaluation.
The Interaction Network (IN) model
Let 


Now consider a directed relationship 





Let 



A system with many objects and relations between them can be represented by a graph 
The final input to the system is 
A basic interaction network function is then defined as:

That might look complicated at first glance, but all it really says is first apply the relation function 

This is represented visually in the figure at the start of this section.
A learnable implementation of an IN
The general definition of the IN in the previous section is agnostic to the choice of functions and algorithms, but we now outline a learnable implementation capable of reasoning about complex systems with nonlinear relations and dynamics. We use standard deep neural network building blocks, multilayer perceptrons (MLP), matrix operations, etc., which can be trained efficiently from data using gradient-based optimisation, such as stochastic gradient descent.
If each object has a state vector of length 


Relationships are represented by three matrices: 



The functions
Training an IN requires optimizing an objective function over the learnable parameters of
and
. Note,
and
involve matrix operations that do not contain learnable parameters.
For the evaluation, the best model architecture for the MLPs was selected by a grid search over layer sizes and depths. The
How well does it learn?
The experiments involved predicting future states of systems and estimating their abstract properties (potential energy).
We evaluated the IN’s ability to learn to make these judgments in three complex physical domains: n-body systmems; balls bouncing in a box; and strings composed of springs that collide with rigid objects.
In the figure below we see 1000 rollout steps for n-body, bouncing ball, and string problems. On the left in each case are the trajectories from a physics engine simulation, and on the right the predictions of the IN model.

Our results shown that the IN can predict the next-step dynamics of our task domains very accurately after training… We also found that the IN trained on single-step predictions can be used to simulate trajectories over thousands of steps very effectively, often tracking the ground truth closely, especially in the n-body and string domains.
Where results do differ, this can be (partially?) attributed to the highly non-linear dynamics in which imperceptible prediction errors by the model can lead to large differences in system state. Such incoherent rollouts however remain consistent with our understanding of the domains.
What does it all mean?
Our results provide surprisingly strong evidence of IN’s ability to learn accurate physical simulations and generalize their training to novel systems with different numbers and configurations of objects and relations… Our interaction network implementation is the first learnable physics engine than can scale up to real-world problems, and is a promising template for new AI approaches to reasoning about other physical and mechanical systems, scene understanding, social perception, hierarchical planning, and analogical reasoning.
Now we just need to bolt-on a perceptual front-end that can infer objects and relations from raw observations!

Hi, I’ve read this paper couple weeks ago and I have a question, did you find in the paper how do the exactly compute the loss? They predict the output velocity and compare it with reference value, but this comparison can be done in many different ways. The one option which comes in mine mind is to compute the length of velocity error vector.
Regarding the great generalization of their model: it works because of the force superposition law which works in physics. The only thing that their model has to predict is given two bodies with their properties compute the force and output velocities of that bodies. The superposition of forces (i.e. effects) is done by their graph approach (no NNs), so I would not say that adding one or more bodies to the simulation proves generalization of the model, it rather proves that model learn properly how to model reaction between two bodies. What I found interesting in this approach is that we could use IN to predict future states for larger values of time step. For example in the paper they use the same time step (dt) for IN and their engine. However they could try to teach model by trying to predict velocities for time t + n * dt instead of t + dt. This is interesting because this approach could over perform existing finite difference schemes.
Hi Krzystof, I couldn’t find anything about the loss function (details in these NIPS papers are surprisingly brief, though sometimes the appendices contain a useful set of information I’d ordinarily expect to be in the main body – paper length restrictions?). In this case, all I could find is the sentence “We use standard deep neural network building blocks, multilayer perceptrons (MLP), matrix operations, etc., which can be trained efficiently from data using gradient-based optimization, such as stochastic gradient descent,” which obviously isn’t giving much away!
Regards, Adrian.
Hi Adrian, thanks for reply, I had the same impression with “paper length restrictions”. It’s a pity that many of such papers are not reproducible and full of hidden details.
Kinds regards, Krzysztof
Hey,
Thanks for the great summary of our paper!
Regarding the loss computation, we used mean-squared error (MSE) between the target and model-predicted velocities. For example, if there were three objects, we would compute the squared differences between the target and model-predicted velocities for each, then take the mean across those values as the loss term. On page 6 we wrote, “All training objectives and test measures used mean squared error (MSE) between the model’s prediction and the ground truth target”, but maybe that can be clarified and made more prominent if we revise the arXiv version.
Feel free to ping me with any other questions.
Peter Battaglia
Hi Adrian,
I don’t be able to see objects like this : https://s0.wp.com/latex.php?latex=o_t&bg=ffffff&fg=333333&s=0 which apear on post.
My Safari browser refused the certificate from FortiGate CA.
Thanks for letting me know… this is the first time I’m trying out the WordPress Latex support (https://en.support.wordpress.com/latex/). It sounds like you might be behind a corporate firewall using Fortigate perhaps? Fortigate’s SSL inspection can interfere with CA trust as described here: http://cookbook.fortinet.com/why-you-should-use-ssl-inspection/. I hope that article at least gives you some pointers as to where to look.
If anyone else is also having trouble viewing the latex expressions in the posts I’d be interested to know…
Thanks, Adrian.
Looks good to me (Mac OS, Chrome (latest)). Btw, glad you are writing up some of the NIPS papers. Looking forward to the others.