Designing software for ease of extension and contraction Parnas, IEEE Transactions on Software Engineering, 1979
A couple of weeks ago we looked at ‘A design methodology for reliable software systems’. David Parnas posted a comment (thank you!) giving some more insight into the history of Dijkstra’s “levels of abstraction” concept:
This paper followed Dijkstra in confusing two concepts, a hierarchical “uses” relation, which restricts how programs can use each other, and the abstractions. Dijkstra’s lowest level implemented processes. The layer above that introduced a primitive form of virtual memory. In a later paper (never published) Dijkstra admitted that he had doubts about this. It would have been useful to have virtual memory to use when implementing processes.
It was useful to have processes when implementing virtual memory. In later discussions, he admitted that the virtual memory should have been split with part of it being below the process implementation, and the rest above. Had he done this, there would have been no “levels of abstraction” because the module implementing the virtual memory would have been both above and below the process implementation in the “uses” hierarchy. This is what happens in modern systems. The lowest of those 3 levels is now in the hardware. It translates virtual addresses to real ones. The higher level does the allocation and paging and is able to be organized in processes.
The design of hierarchical structures in software is much more complex than this simple paper would suggest. See Parnas D.L., “Designing Software for Ease of Extension and Contraction”, IEEE Transactions on Software Engineering, March 1979, pp. 128-138. – David L Parnas, 2016
Today’s choice is of course “Designing Software of Ease of Extension and Contraction,” and unsurprisingly it is packed with advice providing great food for thought for anyone designing systems today.
No one can tell a designer how much flexibility and generality should be built into a product, but the decision should be a conscious one. Often, it just happens.
When you’re designing a software system, you’re really designing a family of programs supporting subsets, extensions, and changes. If any of the following challenges sound familiar, then Parnas has some advice that may help:
- We were behind schedule and wanted to deliver an early release (MVP?) with only a subset of the fully intended capabilities, but we found that the subset would not work until everything worked.
- We wanted to add some simple feature, but found it would have required rewriting all or most of the current code.
- We wanted to simplify the system by removing some feature, but taking advantage of the simplification would have meant rewriting large sections of the code.
- We couldn’t tailor an installation to meet the particular needs of the deployment because the system wasn’t flexible enough.
There are many ways to find yourself in these situations. For example:
- Excessive information distribution: Information that should have been hidden inside modules has spread across the system – either as explicit dependencies or assumptions, or as implicit assumptions such as the order in which results are sorted. (“The connections between modules are [all of] the assumptions modules make about each other.”).
- Structuring the system as a chain of transforming components:
Many programs are structured as a chain of components, each receiving data from the previous component, processing it (and changing the format), before sending the data to the next program in the chain. If one component in this chain is not needed, that code is often hard to remove because the output of its predecessor is not compatible with the input requirements of its successor.
- Components that perform more than one function: “another common error is to combine two simple functions into one component because the functions seem too simple to separate.” And yet we very often find we need just one of them later on. ’The irony of these situations is that the “more powerful” mechanism could have been build separately from, but using, simpler mechanisms. Separation would result in a system in which the simpler mechanism was available for use where it sufficed.
- Loops in the “Uses” relation (cycles in your program dependency graph):
In many software design projects, the decisions about what other component programs to use are left to individual systems programmers… Unless some restraint is exercised, one may end up with a system in which nothing works until everything works.
Four steps to a better structure
- Identify the subsets first. There’s no shortcut for some proper thinking. In particular, search first for a minimal subset. Parnas’ advice here is reminiscent of MVPs, but he’s discussing more the idea of a Minimum Viable Program than a Minimum Viable Product:
In my experience, identification of the potentially desirable subsets is a demanding intellectual exercise in which one first searches for the minimal subset that might conceivably perform a useful service and then searches for a set of minimal increments to the system. The emphasis on minimalist stems from our desire to avoid components that perform more than one function… If we are going to build the software family, the minimal subset is useful; it is not usually worth building by itself.
- Use information hiding criteria to design modules, and provide interfaces to those modules that are insensitive to changes in the secrets they hide. (See “On the criteria…”). As far as possible, even the presence or absence of a component should be hidden from other components.
- Design ‘software machine extensions’ (‘virtual machines’ using the terminology of the time) that provide higher level data types and services and operations that act upon them.
To avoid the problems that we have described as a “chain of data transforming components,” it is necessary to stop thinking of systems in terms of components that correspond to steps in the processing. This way of thinking dies hard….
You can bridge the gap between the programming language and the problem domain in several steps using this approach, each building upon the previous one.
- Carefully design the ‘uses’ structure of the system.
We say of two programs A and B that A uses B if correct execution of B may be necessary for A to complete the task described in its specification. That is, A uses B if there exist situations in which the correct functioning of A depends upon the availability of a correct implementation of B.
(This is very close to an ‘invokes’ relationship, but allows for cases where making the call is enough, and what happens beyond that does not matter, as well as for cases when there is an implicit dependency between two modules, such as relying on a scheduler. ‘Uses’ is another way of saying ‘requires the presence of a correct version of .’
Systems that have achieved a certain ‘elegance’… have done so by having parts of the system “use” other parts in such a way that the “user” programs were simplified.
One counter-intuitive way to end up with large and complex systems is to build them out of lots of “independent” parts, leading to duplication of code to perform common tasks across them.
In designing software, I regard the need to code similar functions in two separate programs as an indication of a fundamental error in my thinking.
If you allow unconstrained uses relations, then parts of the system become highly interdependent. “Often there are no subsets of the system that can be used before the whole system is complete.”
Source: Adrian Cockcroft
The uses relation should therefore be restricted so that it is loop (cycle) free. Based on the uses relation, we can identify a hierarchy of levels within the system:
- Level 0 is the set of all programs that use no other program
- Level i, (i ≥ 1) is the set of all programs that use at least one program on level i – 1, and no program at a higher level than i – 1.
If such a hierarchical ordering exists, then each level offers a testable and usable subset of the system… The design of the “uses” hierarchy should be one of the major milestones in a design effort.
Here are the rules Parnas proposes for when one program should be allowed to use another:
A is allowed to use B when all of the following conditions hold:
- A is essentially simpler because it uses B
- B is not substantially more complex because it is not allowed to use A
- There is a useful subset containing B and not A
- There is no conceivably useful subset containing A but not B
And now we reach the point that ties this back to the opening comment I quoted from Parnas: the ‘sandwich manoeuvre’…
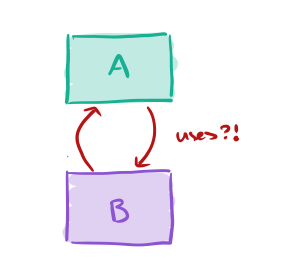
During the process of designing the “uses” relation, we often find ourselves in a situation where two programs could obviously benefit from using each other, and the conditions above cannot be satisfied. In such situations, we resolve the apparent conflicts by a technique that we call “sandwiching.” One of the programs is “sliced” into two parts in a way that allows the programs to “use” each other and still satisfy the above conditions.
For example, A wants to use B, and B wants to use A.
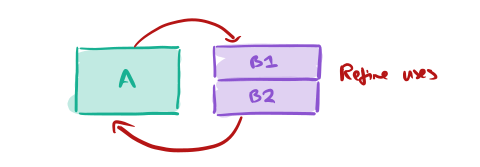
We might split B into two parts:

And then have A use B1, and B2 use A:
The result would appear to be a sandwich with B as the bread and A as the filling. Often, we then go on to split A. We start with a few levels and end up with many.
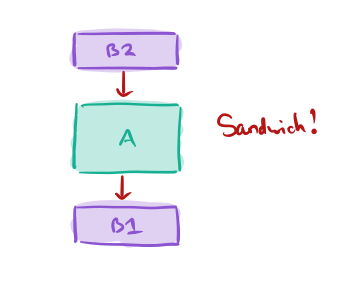
Note therefore that there is not necessarily a one-to-one correspondence between a level and a module.
Several systems, and at least one dissertation have, in my opinion, blurred the distinction between modules, subprograms, and levels… In several systems modules and levels have coincided. This has led to the phrase “level of abstraction.” … In our approach there is no correspondence between modules and levels.
You could have one module which internally is structured in multiple levels, and you could have one level which is subdivided across many modules.
Concluding remarks
The essential difference between this paper and other discussions of hierarchically structured designs is the emphasis on subsets and extensions. My search for a criterion to be used in designing the uses hierarchy has convinced me that if one does not care about the existence of subsets, it does not really matter what hierarchy one uses. Any design can be bent until it works. It is only in the ease of change that they differ.

A related paper, which provides a broader perspective on this topic is:
Parnas, D.L., “On a ‘Buzzword’: Hierarchical Structure”, IFIP Congress ’74, North Holland Publishing Company, 1974, pp. 336-339.
This was reprinted and is easier to find in a valuable book:
Software Pioneers: Contributions to Software Engineering, Manfred Broy and Ernst Denert (Eds.), Springer Verlag, Berlin – Heidelberg, 2002, pp. 501 – 513, ISBN 3-540-43081-4.