Something a little different for today, instead of a new paper I wanted to pause and reflect on the design advice we’ve been reading from Tony Hoare, Barbara Liskov, and David Parnas among others. In particular, how it can be applied in a situation I’ve recently been through with a codebase of my own, and that I’ve encountered with many early stage startups:
Your MVP looks like it’s heading towards product-market fit, now what?
You built your MVP rapidly. The point was to learn and iterate quickly. It may look polished (for what it does) on the surface, but underneath it’s more like a sketch of what the system ultimately might be. I’ll use the example of a webapp (for example, supporting a SaaS product) but it could be any kind of codebase really. In such a codebase I would typically expect to see ‘fat’ controllers with methods that look like transaction scripts, and a very skinny domain model underneath if any. It’s probably not very dry (small bits of logic repeated across controller methods). In terms of levels it’s pretty flat, you might see things like bare outbound HTTP requests directly from controller methods. You have minimal if any tests, testing up to this point has mostly consisted of loading the site in your browser, clicking around and verifying that things seem to be working.
That’s the reality of many rapidly thrown-together prototypes. And the state of affairs is not necessarily bad, so long as you recognise it for what it is. If it turned out you had to throw it all away, it might have been over-engineering to do much more.
Update: I should point out that I’m describing here a situation often encountered – if you can avoid getting to this point in the first place then even better. For example, CI and CD from day one, and some testing around initial transaction scripts (if that’s the initial implementation approach) and then refactoring as you go would all be very good things to do from the get-go!
But now you’re starting to get some real users, and it looks like you have the kernel of a product offering you can build on. You’re starting to feel uncomfortable about the state of the code base – it’s messy, and you notice you feel a little bit uneasy when you have to make changes in some areas. It’s difficult to be sure you haven’t broken anything when all you have is manual testing.
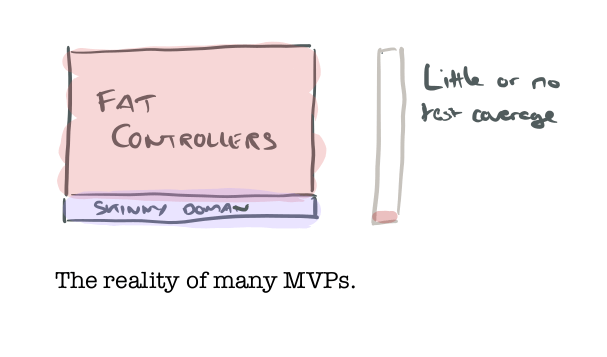
What you do next can have a big impact on the long-term success of the project. You have some real users, you want to keep momentum, and it doesn’t make sense to stall all external progress for weeks or more while you build a second system from scratch. So it’s tempting to keep hacking on the existing codebase as-is, and everyone knows it’s really hard to retrofit tests to an existing codebase too. This is the path that leads to implosion down the line if your product is successful, and that implosion is going to happen when you have way more users and traction (and code!) than you do now.
Here’s an alternative plan that can take you to a better place and a happier future:
The basics.
- If you haven’t already done it (ideally when you first created the project), now is the time that you must put CI in place. Even if you don’t have any tests at all right now, set things up to run your empty test suite.
- Configure your CI to continuously deploy to a staging area whenever the test suite passes. That staging area is your first safety zone so that you can test things work in a production-like environment (and not just on your own machine), before they go live for your users. (We won’t concern ourselves with multiple branches, per-developer on-demand staging sites and so on at this stage, this is just your bare-bones rescue plan).
- Enable promotion from staging to production. (See for example how to set this up on Heroku).
Incremental improvement
Now you’re ready to start work on the codebase (if you skipped any of the basics, go back and attend to them before you go any further). Using the insights you gained from writing the initial MVP, the good news is that you’re now in a much better position to do some of the hard thinking that Parnas referred to and sketch out what a domain model, collection of modules (based on information hiding), and the uses hierarchy might look like.
- Take one of your candidate level 0 modules and code it along with a robust set of tests that give you assurance it does what you expect.
- Refactor the rest of the code base to sit on top of this new module as appropriate. If you’ve got fat transaction-script controllers, this probably means some small parts of the logic in some of them moves out and becomes calls to your new module.
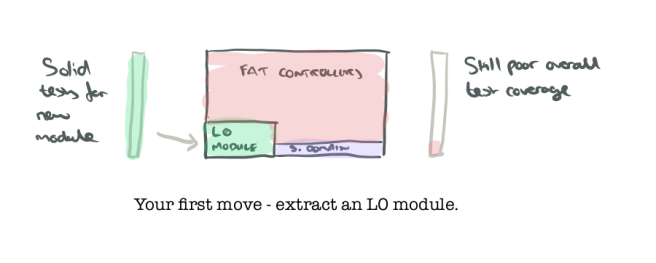
Congratulations. You just found a tiny bit of solid ground that you can build upon!
Where do you go next? You have a number of moves you can make:
- You can work on the next L0 module, following the same process as you did for the first one.
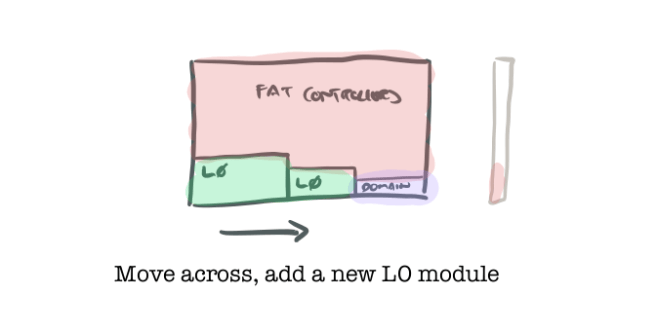
- If you’ve built and tested all of the L-1 modules that a given level L module needs to use, then you can move up and build a higher level (1+) module. Again, refactor the rest of the code base to use it as appropriate (those transaction scripts should be starting to look a teeny bit better as this process goes on). (Note therefore that you don’t need to build all of the level 0 modules before you start to move up, just the ones necessary for that part of the system).
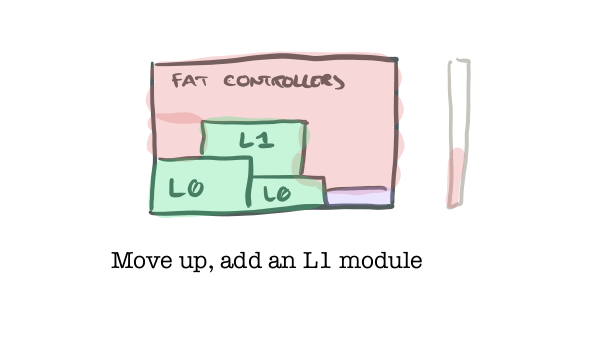
One of the reasons I like working from solid ground upwards concerns writing the test cases for modules at higher levels. Say you have a level 0 module that makes some outbound HTTP requests. The tests for that module might make use of a stub HTTP transport returning json fixtures. Now you’re building and testing a level 1 module that uses it. You don’t want to have to stub the HTTP requests and responses for the L0 module in your L1 tests. That’s information leakage within your test cases, and it’s going to lead to fragile test cases that need a lot of maintenance. Because we’ve got solid test coverage for that L0 module though, we can assume that if we call it correctly it will do what it’s supposed to do. So we can use stubs and mocks as appropriate to make sure that the higher level module correctly uses the lower level one(s), and correctly interprets any returned results, without needing any details of the internals of those modules to leak into the test cases.
- Another move you can make might best be described as a ‘feature tower.’ As I said up-front, you’ll be lucky if all externally visible progress on your app/service can grind to a halt while you rework the system internals. One way to address this is to work on slim vertical slices of new functionality, top-to-bottom (or really I should say bottom-to-top). Here you build just enough robust, properly tested, functionality at each level in the stack, working from the bottom-up, to support a new feature area, adding it alongside the existing functionality.
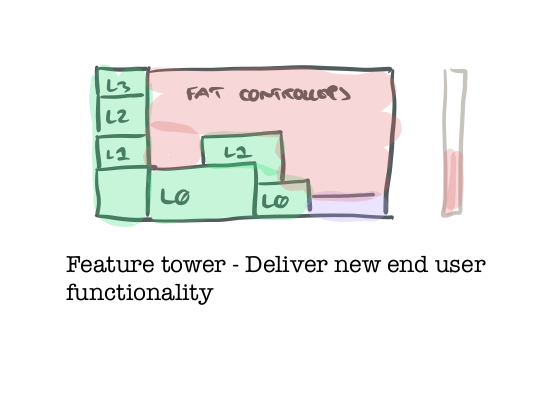
The golden rule is that whenever you add some functionality, you’re improving the overall health of the codebase, not extending the volume of untested transaction scripts.
Keep repeating these moves until you breakthrough into daylight at the topmost levels of the system. In the webapp example we’ve been using, you should now have nice simple tested controller methods on the order of 5-10 lines each. You’ll be feeling much better about the codebase, and have much more confidence in working with it.
It always sounds so easy in a blog post :). But it’s probably not the straight linear process I just painted. The reason I said “sketch out” the domain model, collection of modules, and the uses hierarchy earlier is that I expect you to continue to learn and adapt as you go. Maybe that initial cut is now 80% right, but there’s 20% you find you still need to tweak as you work through the details and adapt to new changes and requirements.
My outline above was set in the context of refactoring a monolith to improve its internal structure, but the same basic approach could also be used for pulling out microservices if you wanted to – so long as you also pay attention to all the additional design complications that can add. I guess I should also mention the strangler pattern for refactoring existing (typically larger) systems. It can be useful to allow teams to work above and below the strangler interface in parallel, but my personal preference (especially for reworking MVP-style projects) remains bottoms-up.
Let’s bring things to a close. You built your MVP rapidly. The codebase was fit for that purpose, but it’s starting to feel messy and hard to change with confidence. What you choose to do next has big implications. Since you need to maintain velocity, it’s tempting to just keep extending your transaction scripts. You may gain some short-term advantage that way, but this road ultimately leads to progress grinding to a halt, buggy software that you’re scared to change, and new bugs introduced every time you try to fix an old one. Because your transaction scripts are essentially just organised using the ‘ordered sequence of steps’ approach that Parnas warned against, then as well as being fragile in the face of change, you gain little advantage in building out new functionality either. Soon the board will be questioning why the pace of development is so slow and whether the company is starting to outgrow its original engineering leadership. If instead you take the path I’ve recommended (or some other approach that achieves similar goals) then the health of the code base will increase. You’ll be able to make changes with confidence, and it will be easier to bring new people on board and scale your team. Furthermore, by structuring the system around a series of ever more powerful ‘virtual machines’ (as those papers from the 70s liked to call them), or ever more powerful abstractions as we might say today, then your pace of development for new functionality will increase as you take advantage of those building blocks. You’ll be moving much faster than a team that stayed with transaction scripts and weak module structure.
Your move.

Hi Simbo, you *can* post comments, there’s just a delay before they get approved (regrettably, manual approval is necessary these days). My starting assumption was that you’re already in a mess (I see that a lot!), I agree with you that if you can avoid getting there in the first place that’s even better :). Although I don’t think it’s necessarily bad to start out with some (tested) transaction scripts very early in a project…. Regards, Adrian.
I completely agree with the push for CI and some kind of structured release mechanism. It’s really a bacon-saver.
The main constraint in a small organisation is the number of developers available. Developers could be rebuilding the second system from scratch, or they could incrementally build/replace components. Which would be faster? Which gives better benefits?
Because while devs are fixing technical debt, they’re not working on new features.