Replex: A scalable, highly available multi-index data store Tai et al. USENIX 2016
Today’s choice won a best paper award at USENIX this year. Replex addresses the problem of key-value stores in which you also want to have an efficient query capability by values other than the primary key.
… NoSQL databases achieve scalability by supporting a much simpler query model, typically by a single primary key. This simplification made scaling NoSQL databases easy: by using the key to divide the data into partitions or “shards”, the datastore could be efficiently mapped onto multiple nodes. Unfortunately, this model is inconvenient for programmers, who often still need to query data by a value other than the primary key.
How do you do that? Typically by sending the query to all partitions and gathering the results. This has poor performance as the number of partitions grows. If we had secondary indices, we could go straight to the appropriate partitions. But maintaining secondary indices brings other problems – to maintain data integrity constraints distributed transactions are often used for update operations. Doing this for every update can cripple system performance though.
Tai et al. address this conundrum in the following way: first, they introduce the notion of a replex, which combines the functions of a replica and an index in one; and secondly they use chain replication to validate inserts across all replexes. To improve recovery times, and throughput during recovery, they also introduce a concept of hybrid replexes. We’ll get to those later.
Replex reconsiders multi-index data stores from the bottom-up, showing that implementing secondary indexes can be inexpensive if treated as a first-order concern. Central to achieving negligible overhead is a novel replication scheme which considers fault-tolerance, availability, and indexing simultaneously. We have described this scheme and its parameters and have shown through our experimental results that we outperform HyperDex and Cassandra, state-of-the-art NoSQL systems, by as much as 10×.
I ended up having to work through an example to get all the ideas straight in my head, and I’m going to introduce the main ideas in the paper through that example.
Consider a people table with columns id, name, city, weight, and height. For some reason, alongside the primary key (id), we also want to be able to do efficient lookups by city and by height.
Replex supports a particular type of predicate query, lookup(R), where R is a row of predicates, each entry being either nil (matches any value in the corresponding column), or a predicate. For example:

Is the Replex equivalent of
select * from people
where city='London' and height > 195Thus Replex as described only supports conjunctions. Furthermore, you can only query (specify predicates), on columns which are indexed. So we’ll need secondary indices on city and height. Now in Replex, every index stores a full copy of each row – thus it also serves as an independent replica of the data, just with the data sorted in a different order. This insight is what allows Replex to combine the functions of index and replica. If you elected to have say 3 replicas of your data for fault-tolerance, then with Replex you can essentially have 2 secondary indices for free!.
Suppose we have four partitions of the data. In our worked example we will have three replexes (the Id replex, the City replex, and the Height replex), each with four partitions, like so:
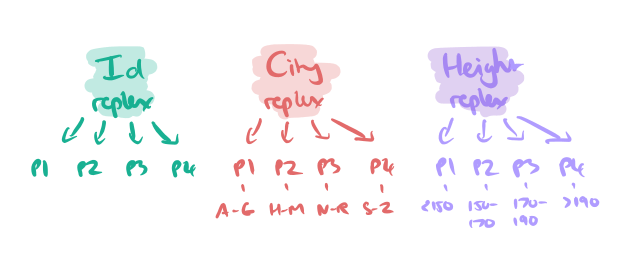
To answer a query, the predicate h(R) returns the replex partitions that should be consulted for each replex. For the example query above, this would be the H-M partition of the City replex, and the ‘> 190’ partition of the Height replex. (Yes, that’s a terrible partitioning for heights, but let’s just roll with it…).
Replacing replicas with replexes requires a modified replication protocol. The difficulty arises because individual replexes can have requirements, such as uniqueness constraints, that cause the same operation to be both valid and invalid depending on the replex. Hence before an operation can be replicated, a consensus decision must be made among the replexes to agree on the validity of an operation.
Replex reaches this consensus using chain replication:

In the consensus phase the operation is propagated along the chain of replexes, collecting valid or invalid decisions. The decision is made by the partition within the replex that will ultimately accept the insert. When the end of the chain is reached, the decisions are ANDed, and the result send back along the chain in a replication phase. As each replex discovers the decision, it commits the insert (assuming the decision is to commit) and then passes the result back up the chain.
It is guaranteed that when the client sees the result of the operation, all partitions will agree on the outcome of the operation, and if the operation is valid, all partitions will have made the decision durable.
A consequence of this approach is that writes are not allowed during failure.
So far so good, but now we need to consider what happens when things do start failing…
Failed partitions bring up two concerns: how to reconstruct the failed partition and how to respond to queries that would have been serviced by the failed partition.
Both of these problems can be solved as long as the system knows how to find data stored on the failed partition. The problem is even though two replexes contain the same data, they have different sharding functions, so replicated data is scattered differently.
Different solutions have different failure amplifications – the overhead of finding data when a partition is unavailable. Consider the straightforward scheme of keeping more than one copy of a given replex partition (replicas):
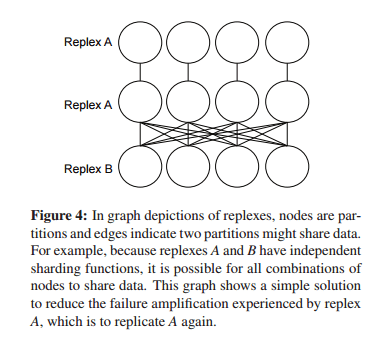
In the example above, this improves failure amplification for A (queries don’t have to route to all partitions of B under failure), but not for B. To eliminate failure amplification of a single failure on both replexes, we’d need to create exact replicas of both, doubling all storage and network overheads. And that’s just with two replexes…
The solution to this problem is hybrid replexes, which provide a degree of shared failure tolerance and amplification across multiple replexes. Let’s see how it works with our City and Height replexes. Each has four partitions, numbered 0..3. Let’s assume a crude partitioning by first letter of cities, and height windows for heights, just to make it easier to follow along:
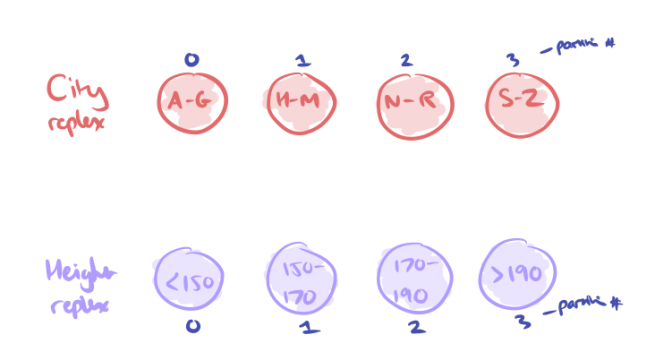
We introduce a hybrid replex which sits alongside the City and Height ones. This will have the same number of partitions (4), but we use a hybrid partitioning strategy to decide which rows will go in each partition.
We have a hash function hcity to decide which partition a row belongs to in the City replex (A-G -> 0, H-M -> 1, N-R -> 2, S-Z -> 3), and a hash function hheight to decide which partition a row belongs to in the Height replex ( < 150 -> 0, 150-170 -> 1, 170-190 -> 2, > 190 -> 3). To decide which partition to place a row in within the hybrid replex we use the formula:
hhybrid(r) = 2(hcity(r) mod 2) + (hheight(r) mod 2)
Consider all rows where the city name starts with A-G. Regardless of the height, these will end up in either partition 0 or partition 1.

Repeat the process for all combinations and you end up with the following:

The first hybrid partition for example will contain all rows where
(City in A-G || City in N-R) && (Height < 150 || Height in 170-190)
The result of such a scheme is that should we lose any one City or Height partition from a replex, we only have to look in two partitions of the hybrid replex to find a matching row, rather than in all 4 as was the case with standard replication.

You can generalize this ‘2-sharing’ scheme and parameterize a hybrid replex by n1 and n2 where n1.n2 = p and p is the number of partitions, using

This lets you tune which replex is most important from an availability / throughput under recovery perspective. The hybrid layer enables only O(&sqrt;p) amplification under failure rather than O(p). Of course there are extensions for more than 2 replexes, and even configurations with multiple layers of hybrid replexes, see the full paper for details.
Replex was implemented on top of HyperDex, and gave read latency equivalent to HyperDex, and insert latency less than half of HyperDex’s (when configured with the same number of secondary indices).
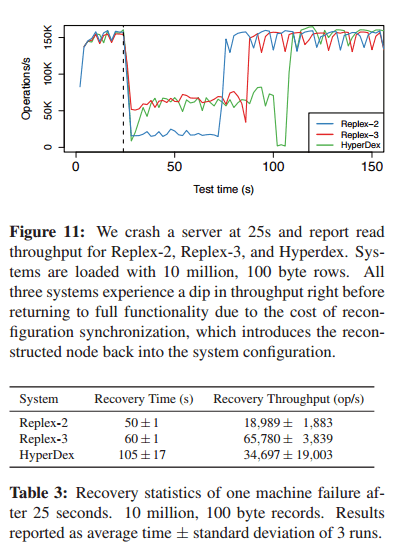
During recovery, a Replex-2 system (no hybrid replex layer) recovered the fastest, but had poor throughput during recovery. A Replex-3 systems (2 secondary indices and one hybrid layer) gives the best balance of recovery time and throughput:
There are many other experiments in the paper evaluating relative performance in which Replex performs favourably.
The authors conclude:
… we have demonstrated not only that a multi-index scalable, high-availability NoSQL datastore is possible, it is the better choice.

2 thoughts on “Replex: A scalable, highly available multi-index data store”
Comments are closed.