What’s wrong with Git? A conceptual design analysis De Rossi & Jackson Onward! 2013
We finished up last week talking about the how to find good concepts / abstractions in a software design and what good modularization looks like. Today’s paper jumps 40+ years to look at some of those issues in a modern context and a tool that many readers of this blog will be very familiar with: Git. With many thanks to Glyn Normington for the recommendation.
The best software designers already know how important it is to discover or invent the right concepts, and that rough edges in these concepts and their relationships will lead to rough edges in the delivered product… Despite this there have been few attempts to study the design of concepts and their impact in software.
The authors chose to use Git to explore the role of concepts in design – it is widely known and used, and at the same time known to be confusing and difficult to learn. Are the usability problems of git just on the surface, in the expression of the commands, or do they run deeper?
We believe that the usability problems of Git run deeper, and can only be addressed by a more fundamental reworking that considers the underlying concepts. This is not to say that such a reworking cannot be achieved in a lightweight fashion. Indeed, our own reworking hides Git behind a veneer just as these other tool do. The difference however, is that we are willing to completely reconsider the core concepts that are presented to the user.
The results of the reworking are made available in a tool called gitless, which I’ve installed on my system to try out for a few days. (Note: if you use oh-my-zsh with the git plugin then this defines an alias for gl which you’ll need to unalias). As of this paper (2013), Gitless was only just beginning as a project, but it continues to this day and tomorrow we’ll look at the 2016 paper that brings the story up to date.
The kinds of concepts the authors are interested in are those which are essential to the design, to an understanding of the workings of the system, and hence will be apparent in the external interface of the system, as well as in the implementation.
In our view, concepts have psychological content; they correspond to how users think about the application. Conceptual design for us, therefore, is about the design of user-visible behavior, and not the design of internal software structure, and we use the term ‘conceptual model’ for a specification that focuses on concepts rather than the details of behavior.
Fred Brooks described conceptual integrity as “the most important consideration in system design” and gave three principles upon which it is based:
- orthogonality – individual functions (concepts) should be independent of one another
- propriety – a product should have only the functions (concepts) essential to its purpose and no more, and
- generality a single function (concept) should be usable in many ways.
The authors add a fourth: consistency – requiring for example that actions behave in a similar way irrespective of the arguments they are presented with or the states in which they are invoked.
The paper then proceeds as follows: first the authors build a conceptual model for git as it is today, and then they show how the conceptual model leads to a number of difficulties experienced by git users. Finally they introduce gitless, which is based on a simpler conceptual model.
The concepts behind git
Ideally, a description of a conceptual design should be implementation-independent; it should be easy to understand; it should be precise enough to support objective analysis; and it should be lightweight, presenting little inertia to the exploration of different ponits in the design space.
The authors’ tool of choice for this is a kind of concept-relationship diagram. Here’s the model they built for Git:
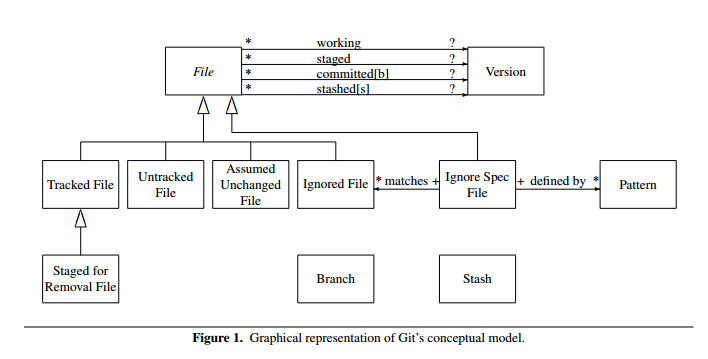
It’s kind of complicated to explain – which is really the authors’ point. Though reading through their description did remind me of some of the subtleties in Git. As I imagine many people do, I’ve evolved my own basic way of using git and try not to stray too far from that. Much of the complexity in Git’s conceptual model comes from the variety of different states and roles that files can be in/play. Files may be tracked or untracked, marked as ‘assumed unchanged’, ignored, staged, stashed and more. Distinguishing between the working version of a file and the staged version of a file is a common cause of confusion. For example, if I follow the sequence:
git add foo.rb // continue working in foo.rb git commit
Update: in the original post the last line erroneously read ‘git commit foo.rb‘ which will commit the working version of foo.rb.
Then the version of foo.rb that gets commited is the version as of the time of the add command (because that copies foo.rb to staging, and commit works from the copies in staging). Here are a few of the key git commands and how they relate to the concepts of staging and working copies:
git add _f_causes the working version of a file f to be copied to staging, and if the file was untracked, it also becomes tracked.git commitcauses all versions of files that are staged to become committedgit resetrestores a file to a previous state. E.g.git reset HEAD ffor a file f removes its association with the staged version, makes it untracked if was previously untracked before being staged, and makes it tracked if it was previously an assumed unchanged file. (The authors don’t model the variations of reset that work on history).git checkout _f_reverts local changes to file f by replacing the working version with the staged version if there is one, or with the committed version otherwise. The same command is also used to switch branches…git stashtakes the working version of each file (with modifications) and makes it a stashed version in a new stash….
The very complexity of the conceptual model we have described suggests to us that something is amiss in the design of Git. Can a version control system really require so many, and such intricate concepts? And before we have even considered synchronizing multiple repositories?
How git’s ‘surprises’ are rooted in violations of conceptual integrity
Here’s one example from each of Brook’s categories:
Orthogonality
The staged and working versions of a file are coupled in complex ways, and Git commands that one might expect to affect only one often affect the other too. One way to get into trouble is to add a file, then continue working on it before committing. If you then decide to undo the commit with a reset command then depending on the arguments not just the staged version but also the working version wil be replaced (wiping out subsequent work since the commit).
Why this happens: the concepts of staged and working versions are not orthogonal. Many commands that are primarily intended to modify one of the two modify the other too. Worse, whether or not these ripple effects occur depends on which arguments are presented to the commands.
Propriety
Committing files is non-trivial in git, in large part because of the intrusion of the concept of staging.
The git commit command takes versions from staging, not the working version. The git commit -a variation almost gets around this (it performs an implicit add prior to commit), but it won’t pick up untracked files and can only be used to commit all tracked files with modifications. In short, it’s too blunt a tool.
Some Git enthusiasts make arguments for the value of the staging concept, but for most users it offers inessential functionality, and its presence complicates the use of Git considerably.
Generality
Switching branches… and those painful conflicts which can occur when there are uncommitted changes.
Branches are intended to support independent lines of development. A line of development comprise both the working versions of files and committed versions. And yet, in Git’s conceptual model, only the committed versions are organized by branch; while there are potentially multiple committed versions of a file (one per branch), there can only be one working version. There is thus a lack of generality, with the branching feature essentially available only in one area and not the other.
Gitless – a better Git?
Gitless is the OSS project maintained by the authors that first cleans up the conceptual model, and the puts a user interface on top.
The key differences between Git and Gitless are: (a) the elimination of the concept of Assumed Unchanged File, and the generalization of Untracked File to subsume it; (b) the elimination of staged versions; (c) the elimination of the concept of Stash, and stashed versions; (d) indexing of working versions by branch. Switching branches in Gitless is equivalent to always creating a stash (more precisely, of executing git stash –all) before switching to a different branch in Git, and then retrieving this stash when the user switches back to the original branch. Thus, it is as if there are multiple working directories (one for each branch), or in other words, one can think of it as a file potentially having several working versions accessible via a branch name b (noted as working[b] in the diagram). This means that the user can freely switch from branch to branch without having to stash or commit unfinished changes. We believe this lives up to the expectation of a branch being an independent line of development.
If not all of the above makes sense to you, then Gitless is probably a good choice! The conceptual model of Gitless looks like this:
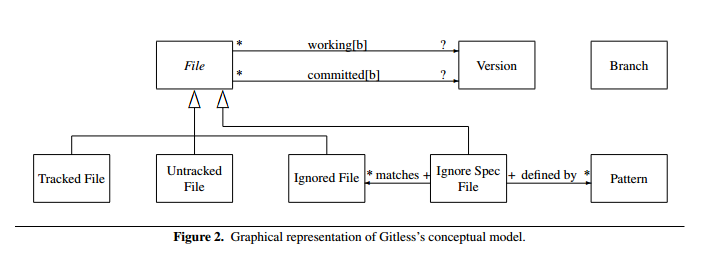
At the point this paper was released, only very early evaluation studies had been done of the Gitless model, but “the elimination of the staging area was enthusiastically received as a major reduction in complexity.”
It’s an interesting project since it relates to a tool many of us use on a daily basis. But beyond the specifics of Git, one of the takeaways for me is the reminder that good usability is deeply rooted in the conceptual design, and is far from just being about the presentation layer.
Most usability experts seem to recognize the importance of a product’s conceptual model, and the problems that arise when the user’s mental model, and the correct conceptual model of the product diverge.
The classic work on this last point is of course Donald Norman’s “The Design of Everyday Things.”

How can the authors do a whole study of the conceptual basis of Git without any reference to its origins as a clone of Larry McVoy’s BitKeeper?
I think, Victor, for the simple reason that Git’s origins were not really relevant to the task at hand.
Of course they were. BK does not use the peculiar staging structure of Git even though Git began as a recreation of BK and shares a great deal.
Seems like Gitless conceptual model is quite similar to Subversion.
A brilliant set of articles. Thank you very much.
This is a very interesting paper which, in the last section on related work, points out deficiencies in others’ attempts at defining (or not defining) conceptual integrity. Although there are references to J.R.Abrial (B), J.M.Spivey (Z), Booch (UML), C.B.Jones (VDM), B.Meyer and Brooks, I was disappointed to find no reference to Parnas’s many papers on or near this subject.
It’s rather weird to see the model described as such, since the underlying git model, the one that makes everything make sense it’s not even mentioned. It stays only one the surface of the command line interface, on the “porcelain” never touching the plumbing which is quite straightforward. In essence git is a layered system.
An inefficient and rather hard to use version of git can be implemented with a dumb CAS (content addressed store) and modeling commits, trees and blobs and not much else (actually even commits and trees are blobs). Everything is immutable at this level.
All the rest is polish on top of it. If you look at the “porcelain” model, three main concepts show up: the index, the working tree and the repository.
There are also three simple transitions:
– you add from the working tree to the index
– you commit from the index to the repository
– you checkout from the repository into working tree
Branches, tags and reflogs are the next level, the one that supports a reasonable development workflow and also serve as reference roots for GC-ing the CAS.
And then you have the distribution model, which can normally be ignored, which essentially deals with subgraphs of blobs being sent around in packs.
Granted, many of the tools could use better explanations/names but if you understand the model it is a lot easier to reason about. Specially when under collaboration you get in complex situations that a simple file-version model cannot possibly handle.
> git add foo.rb
> // continue working in foo.rb
> git commit foo.rb
> Then the version of foo.rb that gets commited is the version as of the time of the add command (because that copies foo.rb to staging, and commit works from the copies in staging).
That’s not quite true. The working tree version of foo.rb will be committed. See the git-commit’s manpage:
The content to be added can be specified in several ways:
…
3. by listing files as arguments to the ‘commit’ command, in which case the commit will ignore changes staged in the index, and instead record the current content of the listed files (which must already be known to Git);
The quoted paragraph wasn’t substantially changed since 2008-11-18. And I never observed any behaviour that differed from it.
Or maybe you have some funny buggy version where git-commit behaves differently. Could you name the version where you have tested this example then?
I’m sorry, I’ve checked the paper once more, and it looks like a mistake of its authors, not the author of the blog.
Yes, looks like there shouldn’t be a ‘foo.rb’ on the commit line for the behaviour as described to be seen. I’ll update the post when I get back to my desktop. Tks, A.
> Switching branches… and those painful conflicts which can occur when there are uncommitted changes.
If the changes interfere with the version of files from the other branch, then there either will be a merge conflict during the switch, or the changes will be stashed automatically, or overwritten – regardless if it’s git, mercurial, or subversion. There is no other possibility.
PS This thread can be interesting https://public-inbox.org/git/20160930191413.002049b94b3908b15881b77f@domain007.com/
I have read about Gitless before and find the concept intriguing, especially since I am currently working on a side project that is a domain-specific Git client. I have to agree with one of the later comments in that the deficiencies are only addressed at the porcelain level, and the plumbing level is never even mentioned.
While I understand that removing the concept of staging makes things simpler to understand, I consider the staging area/index to be one of the most useful features of Git. I often make extensive changes to multiple files, which I do not want to save in a single, monolithic commit. I use the staging area to assemble fine-grained commits by carefully picking files and even individual lines. I can imagine that this could be solved without the index, but it seems a very useful concept still (like a safety net in some sense).
I don’t see where it requires saving a monolithic commit. You can perform as many commits as you want, but if you want to neatly organize them, you can rebase and cherrypick to restructure them. This is a far simpler approach in most workflows where you can’t forecast the commit structure until you’re done.