Goods: organizing Google’s datasets Havely et al. SIGMOD 2016
You can (try and) build a data cathedral. Or you can build a data bazaar. By data cathedral I’m referring to a centralised Enterprise Data Management solution that everyone in the company buys into and pays homage to, making a pilgrimage to the EDM every time they want to publish or retrieve a dataset. A data bazaar on the other hand abandons premeditated centralised control:
An alternative approach is to enable complete freedom within the enterprise to access and generate datasets and to solve the problem of finding the right data in a post-hoc manner… In this paper, we describe Google Dataset Search (Goods), such a post-hoc system that we built in order to organize the datasets that are generated and used within Google.
Everyone within the company just carries on creating and consuming datasets using whatever means they prefer, and Goods works in the background to figure out what datasets exist and to gather metadata about them. In other words, (surprise!) Google built a crawling engine… It turns out this is far from an easy problem (to start with, the current catalog indexes over 26 billion datasets – and this is just those whose access permissions make them readable by all Google engineers). As an approach to the problem of understanding what data exists, where it is, and its provenance, I find Goods hugely appealing vs the reality of the ever-losing battle for strict central control within an enterprise.
Let’s first examine the benefits of building a data bazaar, and then dive into some of the details of how you go about it.
Why build a data bazaar?
Here’s the big picture of the Goods system:
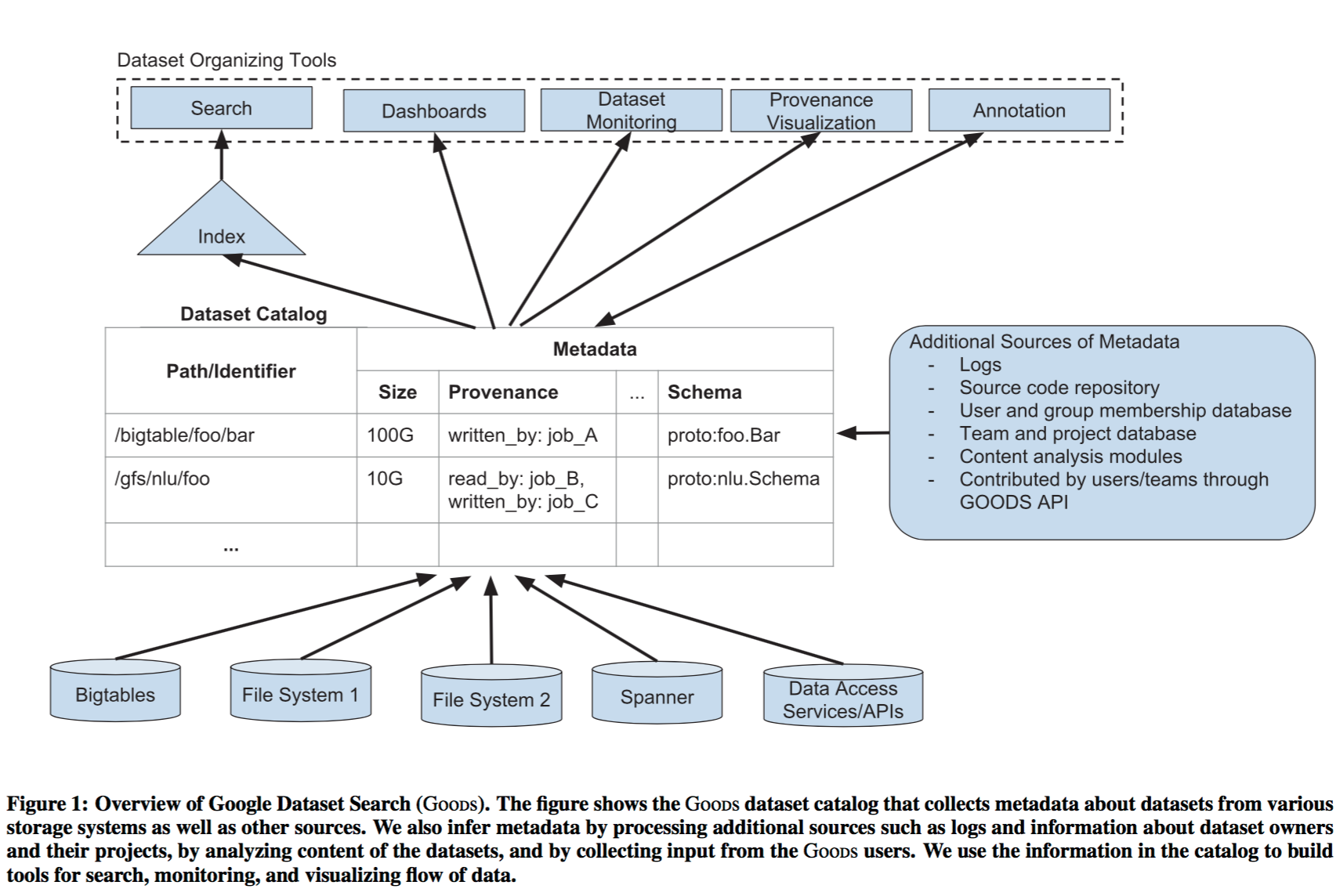
Goods crawls datasets from all over Google, extracts as much metadata as possible from them, joins this with metadata inferred from other sources (e.g. logs, source code and so on) and makes this catalog available to all of Google’s engineers. Goods quickly became indispensable. As a nice segue to the material we were looking at last week, an example is given of a team working on NLU:
Goods uses this catalog to provide Google engineers with services for dataset management. To illustrate the types of services powered by Goods, imagine a team that is responsible for developing natural language understanding (NLU) of text corpora (say, news articles). The engineers on the team may be distributed across the globe and they maintain several pipelines that add annotations to different text corpora. Each pipeline can have multiple stages that add annotations based on various techniques including phrase chunking, part-of-speech tagging, and co-reference resolution. Other teams can consume the datasets that the NLU team generates, and the NLU team’s pipelines may consume datasets from other teams. Based on the information in its catalog, Goods provides a dashboard for the NLU team (in this case, dataset producers), which displays all their datasets and enables browsing them by facets (e.g., owner, data center, schema). Even if the team’s datasets are in diverse storage systems, the engineers get a unified view of all their datasets and dependencies among them. Goods can monitor features of the dataset, such as its size, distribution of values in its contents, or its availability, and then alert the owners if the features change unexpectedly.
Goods also tracks dataset provenance, figuring out which datasets were used in the creation of a given dataset, and which datasets consume it downstream. The provenance visualisation is very useful when figuring out what upstream changes may be responsible for a problem, or for working out the potential consequences of a change being considered. This reminds me very much of the infrastructure Google also put in place for tracking ‘input signals’ (streams and datasets) in their automated feature management system for machine learning.
The full set of metadata that Goods tracks is illustrated below:

For dataset consumers, Goods provides a search mechanism for finding important and/or relevant datasets. Every dataset has its own profile page which helps users understand its schema, users, provenance, and find other datasets that contain similar content. The Goods system allows user to provide their own data annotations which are also indexed. This mechanism has facilitated further applications built on top of Goods.
The profile page of a dataset cross-links some of the metadata with other, more specialized, tools. For example, the profile page links the provenance metadata, such as jobs that generated the dataset, to the pages with details for those jobs in job-centric tools. Similarly, we link schema metadata to code-management tools, which provide the definition of this schema. Correspondingly, these tools link back to Goods to help users get more information about datasets. The profile page also provides access snippets in different languages (e.g., C++, Java, SQL) to access the contents of the dataset. We custom-tailor the generated snippets for the specific dataset: For example, the snippets use the path and schema of the dataset (when known), and users can copy-paste the snippets in their respective programming environment.
The Goods profile page for a dataset has become a natural handle for bookmarking and sharing dataset information. The Google File System browser provides direct links to Goods pages for datasets within a directory for example.
How Google built Goods
The challenge of creating a central data repository in a post-hoc manner without relying on any collaboration from engineers is that you need to piece together the overall puzzle from multiple sources of information – and even then, you may never be certain. At Google scale, the sheer number of datasets in question (26B+) means that you need to be a little bit savvy about how often you crawl and process datasets too. “Even if we spend one second per dataset (and many of the datasets are too large to process in one second per dataset), going through a catolog with 26 billion datasets using a thousand parallel machines still requires around 300 days…” Moreover, datasets are created and deleted all the time – about 5% (1B) datasets in the catalog are deleted every day. Two tactics are used to help deal with the volume of datasets: a twin-track approach to crawling and processing, and dataset clustering.
The twin-track approach designates certain datasets as ‘important’ – those that have a high provenance centrality, and those where users have taken the effort to provide their own additional metadata annotations. One instance of the Schema Analyzer(the most heavyweight job in the pipeline) runs daily over these important datasets, and can get through them quickly. A second instance processes all datasets, but may only get through a fraction of them within any given day.
In practice, as with Web crawling, ensuring good coverage and freshness for the “head” of the importance distribution is enough for most user scenarios.
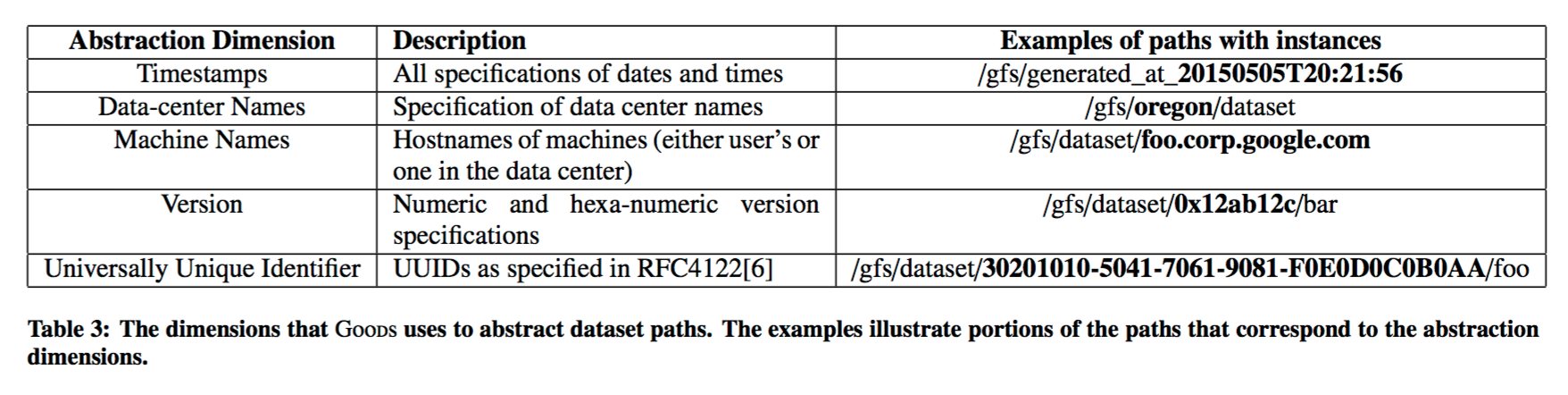
Clustering datasets helps to make both the cognitive overload for users lighter, as well as reducing processing costs. Consider a dataset that is produced every day, and saved to eg. /dataset/2015-10-10/daily_scan. By abstracting out the date portion, it is possible to get a generic representation of the ‘daily scan’ file. This can be shown as a single top-level entity in the Goods, and also saves processing time on the assumption for example that all files in the series share the same schema.
By composing hierarchies along different dimensions, we can construct a granularity semi-lattice structure where each node corresponds to a different granularity of viewing the datasets… Table 3 (below) lists the abstract dimensions that we currently use.
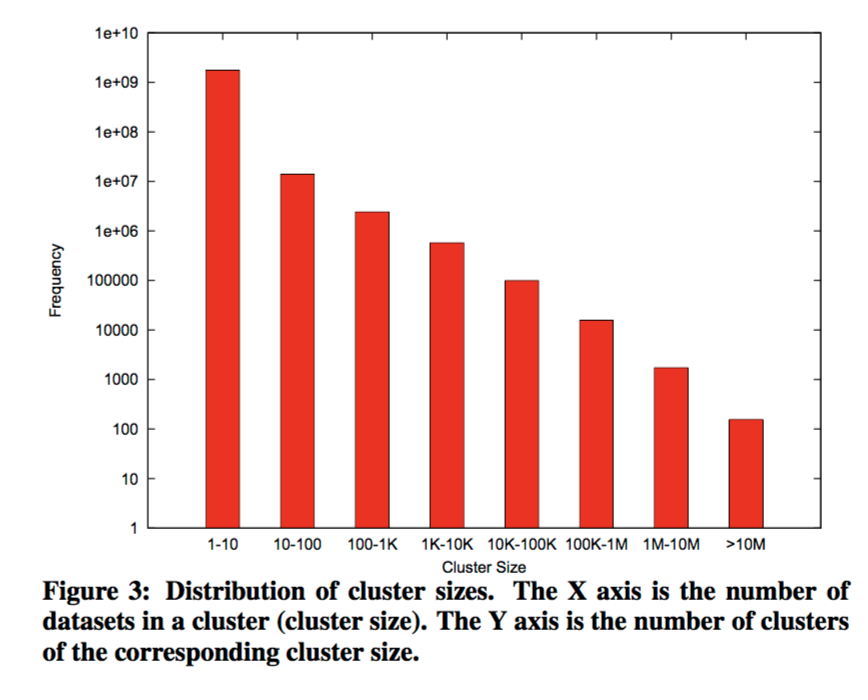
Goods contains an entry for each top-most element in the semi-lattice. This avoids there being too many clusters and helps to keep the set of clusters stable over time. Some clusters can be very large!
Goods uses a variety of techniques to try and infer the metadata for a dataset.
Because Goods explicitly identifies and analyzes datasets in a post-hoc and non-invasive manner, it is often impossible to determine all types of metadata with complete certainty. For instance, many datasets consist of records whose schema conforms to a specific protocol buffer… Goods tries to uncover this implicit association through several signars: For instance, we “match” the dataset contents agains all registered types of protocol buffers within Google, or we consult usage logs that may have recorded the actual protocol buffer.
The provenance metadata is of especial interest. It helps understand how data flows through the company and across the boundaries of internal teams and organisations. Provenance is mined from production logs, which contain information on which jobs read and write each dataset. To make this tractable, the logs are only sampled, and the downstream and upstream relationships are computed over a few hops as opposed to the full transitive closure.
To find the schema associated with a dataset Goods needs to find the protocol buffer used to read and write its records. Since these are nearly always checked into Google’s source code repository, Goods also crawls the code repository to discover protocol buffers. It is then possible to produce a short list of protocol buffers that could be a match…
We perform this matching by scanning a few records from the file, and going through each protocol message definition to determine whether it could conceivable have generated the bytes we see in those records… the matching procedure is speculative and can produce multiple candidate protocol buffers. All the candidate protocol buffers, along with heuristic scores for each candidate, become part of the metadata.
To facilitate searching for datasets, Goods also collects metadata summarizing the content of a dataset.
We record frequent tokens that we find by sampling the content. We analyze some of the fields to determine if they contain keys for the data, individually or in combination. To find potential keys, we use the HyperLogLog algorithm to estimate cardinality of values in individual fields and combinations of fields and we compare this cardinality with the number of records to find potential keys. We also collect fingerprints that have checksums for the individual fields and locality-sensitive hash (LSH) values for the content. We use these fingerprints to find datasets with content that is similar or identical to the given dataset, or columns from other datasets that are similar or identical to columns in the currentdataset. We also use the checksums to identify which fields are populated in the records of the dataset.
There are many other implementation details in the paper, I wanted to focus in this write-up just on the big idea as I find it very compelling. One of the significant challenges still open, according to the authors, is improving the criteria for ranking datasets and identifying important datasets: “we know from the users’ feedback that we must improve ranking significantly… we need to be able to distinguish between production and test or development datasets, between datasets that provide input for many other datasets, datasets that users care about, and so on.”
Finally, we hope that systems such as Goods will provide an impetus to instilling a “data culture” at data-driven companies today in general, and at Google in particular. As we develop systems that enable enterprises to treat datasets as core assets that they are, through dashboards, monitoring, and so on, it will hopefully become as natural to have as much “data discipline” as we have “code discipline.”