Transactional Data Structure Libraries Spiegelman et al. PLDI 2016
Today’s choice won a distinguished paper award at the recent PLDI 2016 conference. Spiegelman et al. show how to add transactional support to in-memory concurrent data structure libraries in a way that doesn’t sacrifice performance.
Since the advent of the multi-core revolution, many efforts have been dedicated to building concurrent data structure libraries (CDSLs), which are so-called “thread-safe.” … Unfortunately simply using atomic operations is not always “safe”. Many concurrent programs require a number of data structure operations to jointly execute atomically…
Software (and even hardware supported) transactional memory has been developed to address this requirement, yet “STM incurs too high a overhead, and hardware transactions are only best effort – and in both cases abort rates can be an issue.” In contrast, concurrent data structures are widely adopted. Can we provide transaction semantics without sacrificing performance? This is what Spiegelman et al.’s transactional data structure library (TDSL) model seeks to accomplish. One key insight is that by lifting transactional considerations to the level of the data structure (as opposed to trying to implement a fully general solution) we can take advantage of the operation semantics for a particular data structure to optimise. This is reminiscent of the work by Bailis et al. on Coordination avoidance in database systems.
Restricting the transactional alphabet to a well-defined set of operations (e.g. enqueue, dequeue, insert, remove, and contains) is the key to avoiding the notorious overhead associated with STM…
I’m also reminded of Redis, which supports transactions for in-memory data structures, but out-of-process. CRDTs are another interesting basis for transactional data structures since their conflict-free nature reduces, well, … conflicts! See for example SwiftCloud. TDSL is for in-process, traditional data structures.
In TDSL, transactions are demarcated by calls to Tx-begin and Tx-commit. Transactions execute atomically and in isolation. Data structure operations can also be called outside of a transaction context, in which case they are treated as singleton transactions. A singleton transaction cannot abort, so client code can be run unaltered. Transaction histories (including singletons) are linearizable. The particular implementation of transactions (e.g. pessimistic vs optimistic locking) can vary per data structure in the library. For example, optimistic concurrency control works well for maps, but a pessimistic solution is more efficient for contended queues. TDSL provides a mechanism to join operations across multiple different data structures within the same transaction.
A skiplist example
We’re treated to a fully-worked example for skiplists. This begins with a simple linked-list using the TL2 STM algorithm, and proceeds to show how it can be made more efficient by considering the semantics of lists (exploiting the fact that operations in independent parts of the list commute). At the next stage support for a non-transactional index is introduced (for skipping), followed by the ability for multiple objects from the same TDSL library to participate in the same transaction.
A linked-list with TL2 STM support
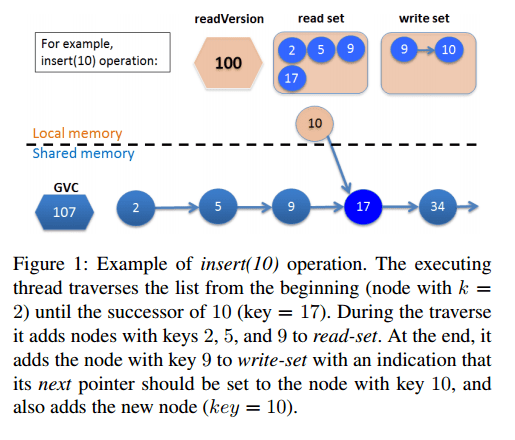
The TL2 algorithm uses a global version clock (GVC) supporting a read operation (to return the current version), and an add-and-fetch operation which atomically increases the version and returns its new value. Every node in the (ordered) linked list is tagged with a version, and before a transaction commits it validates its reads by checking that their versions have not increased since the transaction began. Nodes also have locks enabling a transaction to change all the nodes it affects atomically.
When a transaction begins, the current value of the global clock is saved as the transaction’s read version. The transaction also maintains a read set and a write set. For an operation on some key k, we scan the list from the root traversing every node until we reach the node with a key ≥ k. Every node we traverse on the way is checked to ensure it is either (a) in our write set, or (b) unlocked and at a version ≤ the read version. If these checks pass it is added to the read set (and if not, the transaction aborts). Updates are tracked in the write set (the list itself is not altered until a commit). When commiting the thread first tries to lock all the nodes in the write set, and then validates the read set. If everything looks good the GVC is incremented, the version of all nodes in the write set is updated to the new GVC value and the write set changes are incorporated in the list.
Exploiting list semantics
The procedure outlined above ends up adding a lot of objects to the transaction read set due to list traversal (especially for objects near the end of the list).
We observe that operations of concurrent transactions that change the list in different places need not cause an abort since their operations commute.

Thus we can keep the read set much smaller by only adding nodes whose update may lead to semantic violations. Every operation with key k simply adds to the read set the predecessor of k, and remove also adds the successor. This simple optimisation keeps the read set small and greatly reduces the number of aborts.
Skipping
Traversing the list from the beginning every time is also slow, and so we can add shortcuts as in a skiplist. This further avoids unneccessary aborts due to validation of all the nodes being passed through in a regular traverse.
We observe, however, that the traversal is not an essential part of the insert, remove, and contains operations. In other words, a transaction is semantically unaffected by an interleaved transaction that changes a node on its path (unless traversed by an iterator). It only performs the check (in the transactional traversal) in order to ensure that (1) it traverses a segment of the list that is still connected to the head of the list and (2) it does not miss its target during the traversal. But if an operation with key k could somehow guess predecessor(k), then it could forgo the traversal and start the operation from there. Or if it could guess any node n between the head of the list and predecessor(k), it could start from n.
This is supported by adding an index as in a standard skiplist algorithm. Index accesses and updates are not part of the transaction. It is possible therefore that the index lookup may return a node that is actually a predecessor of k’s true predecessor, or more problematic, a node that has been removed from the list. In the former case we simply keep traversing until we find k. The latter case is handled by a tombstone mechanism implemented with a deleted bit in every node. If an index lookup returns a deleted node d, we simply repeat the lookup to find d’s predecessor…
Multi-object transactions
Multi-object transactions are supported by having the transaction maintain an object set in addition to the read set and write sets for each object.
These sets may be structured differently in different object types. For example, the queue data structure we present below does not employ an index, and hence its index-todo is empty. And, unlike the skiplist’s write-set, the queue’s write-set includes an ordered set, because the order in which items are enqueued ought to be preserved. At the end of a transaction, TX-commit uses two phase locking, i.e., locks the appropriate items in all objects, then validates all of them, then updates all objects, and finally releases all locks. We note objects may define their own locking policies— our skiplist employs fine-grain locking while our queue relies on a single global lock for the entire queue. These per-object policies are tailored to the contention level and attainable parallelism in each object. While a skiplist can enjoy a high degree of parallelism using fine-grain locks, queues induce inherent contention on the head and tail of the queue and are thus better suited for coarse-grain locking.
Singleton performance and isolation
I said earlier that singleton operations don’t need to be wrapped in tx-begin and tx-commit, yet still behave as transactions. We know that these operations are isolated from other transactions since they hold their updates in a write-set and don’t make any changes to the main data structure until an atomic commit. But how are transactions isolated from the effects of singleton operations??? That was bugging me too as I read through the paper… you’ll find the answer in section 3.4 of the paper: each node is augmented with a single bit of metadata, singleton, which indicates whether the last update to the node (or queue) was by a singleton operation. Singleton operations can’t abort either, thus preserving the expected semantics. If an accessed node is locked, the operation simply restarts.
Since singletons do not increment the GVC, transactions cannot rely on versions alone to detect conflicts with singletons. To this end, we use the singleton bits. For atomicity, we enhance our transaction’s conflict detection mechanism as follows: the validation phase of TX-commit now not only validates that there is no node in read-set with a bigger version than readVersion, but also checks that there is no node with a version equal to read-Version and a true singleton bit (indicating that there is a conflicting singleton). For opacity, every skiplist node and queue accessed during a transaction is checked in the same way. In both cases, if a node or queue with a version equal to readVersion and singleton bit set to true is checked, the transaction increments GVC, (to avoid future false aborts), and aborts.
TDSL Composition
Section 4 of the paper describes a mechanism by which transactions may span multiple independently developed TDSL libraries. This is based on the theory of Ziv et al. in ‘Composing concurrency control,’ which gives a set of criterion under which composition is safe. It uses a three-phase commit protocol with lock, verify, and finalize phases. A treatment of this is probably best left to an independent study of Ziv et al.’s paper, so I’ll add that to my backlog…
Performance evaluation
Regular operations (i.e. singletons) perform comparably to the same operations in non-transactional implementations:

Throughput is much better than a transactional skiplist using the TL2 STM library directly:

Our TDSL caters stand-alone operations at the speed of a custom-tailored CDSLs, and at the same time, provides the programmability of transactional synchronization. Our TDSL transactions are also much faster than those offered by a state-of-the-art STM toolkit, (tenfold faster in synthetic update-only benchmarks, up to 17x faster in a non-trivial concurrent application). This is thanks to our ability to reduce overheads and abort rates via specialization to particular data structure organizations and semantics. In particular, we can use the most appropriate concurrency-control policy and for each data structure regardless of the approaches used for other data structures.
