AI2: Training a big data machine to defend Veeramachaneni et al. IEEE International conference on Big Data Security, 2016
Will machines take over? The lesson of today’s paper is that we’re better off together. Combining AI with HI (human intelligence, I felt like we deserved an acronym of our own ;) ) yields much better results than a system that uses only unsupervised learning. The context is information security, scanning millions of log entries per day to detect suspicious activity and prevent attacks. Examples of attacks include account takeovers, new account fraud (opening a new account using stolen credit card information), and terms of service abuse (e.g. abusing promotional codes, or manipulating cookies for advantage).
A typical attack has a behavioral signature, which comprises the series of steps involved in commiting it. The information necessary to quantify these signatures is buried deep in the raw data, and is often delivered as logs.
The usual problem with such outlier/anomaly detection systems is that they trigger lots of false positive alarms, that take substantial time and effort to investigate. After the system has ‘cried wolf’ enough times they can become distrusted and of limited use. AI2 combines the experience and intuition of analysts with machine learning techniques. An ensemble of unsupervised learning models generates a set of k events to be analysed per day (where the daily budget k of events that can be analysed is a configurable parameter). The human judgements on these k events are used to train a supervised model, the results of which are combined with the unsupervised ensemble results to refine the k events to be presented to the analyst on the next day. And so it goes on.
The end result looks a bit like this:

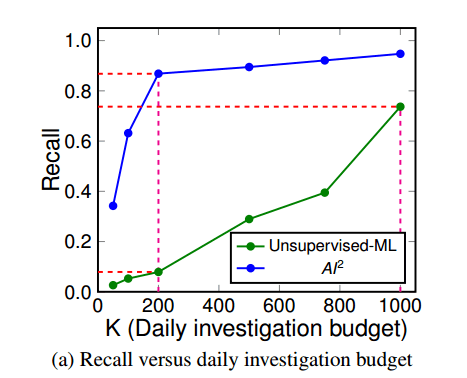
With a daily investigation budget (k) of 200 events, AI2 detects 86.8% of attacks with a false positive rate of 4.4%. Using only unsupervised learning, on 7.9% of attacks are detected. If the investigation budget is upped to 1000 events/day, unsupervised learning can detect 73.7% of attacks with a false positive rate of 22%. At this level, the unsupervised system is generating 5x the false positives of AI2, and still not detecting as many attacks.
Detecting attacks is a true ‘needle-in-a-haystack’ problem as the following table shows:
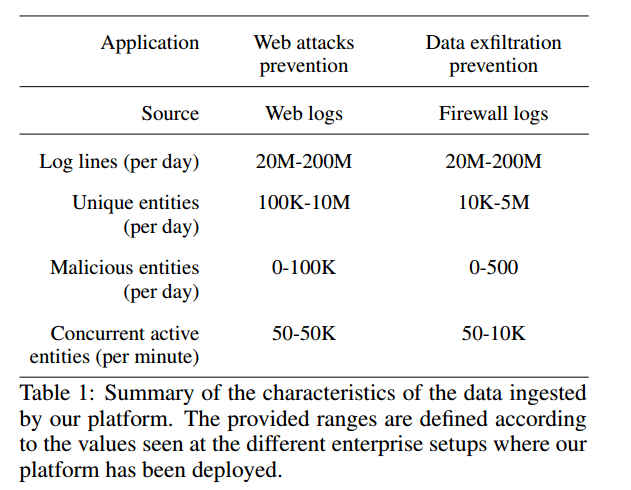
Entities in the above refers to the number of unique IP addresses, users, sessions etc. anaysed on a daily basis. The very small relative number of true attacks results in extreme class imbalance when trying to learn a supervised model.
AI2 tracks activity based on ingested log records and aggregates activities over intervals of time (for example,counters, indicators – did this happen in the window at all? – elapsed time between events, number of unique values and so on). These features are passed into an ensemble of three unsupervised outlier detection models:
- A Principle Component Analysis (PCA) based model. The basic idea is to use PCA to determine the most significant features (those that explain most of the variance in the data). Given an input take its PCA projection, and then from the projection, reconstruct the original variables. The reconstruction error will be small for the majority of examples, but will remain high for outliers.
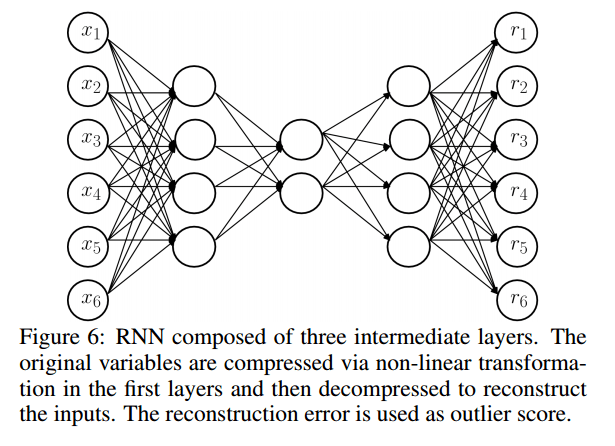
- A Replicator Neural Network (not to be confused with a Recurrent Neural Network – both get abbreviated to RNN). This works on a very similar principal. The input and output layers have the same number of nodes, and intermediate layers have fewer nodes. The goal is to train the network to recreate the input at the output layer – which means it must learn an efficient compressed representation in the lower-dimensional hidden layers. Once the RNN has been trained, the reconstruction error can be used as the outlier score.
- The third unsupervised model uses copula functions to build a joint probability function that can be used to detect rare events.
A copula framework provides a means of inference after modeling a multivariate joint probability distribution from training data. Because copula frameworks are less well known than other forms of estimation, we will now briefly review copula theory…
(If you’re interested in that review, and how copula functions are used to form a multivariate density function, see section 6.3 in the paper).
The scores from each of the models are translated into probabilities using a Weibull distribution, “which is flexible and can model a wide variety of shapes.” This translation means that we can compare like-with-like when combining the results from the three models. Here’s an example of the combination process using one-day’s worth of data:

The whole AI2 system cycles through training, deployment, and feedback collection/model updating phases on a daily basis. The system trains unsupervised and supervised models based on all the available data, applies those models to the incoming data, identifies k entities as extreme events or attacks, and brings these to the analyst’s attention. The analysts deductions are used to build a new predictive model for the next day.
This combined approach makes effective use of the limited available analyst bandwidth, can overcome some of the weaknesses of pure unsupervised learning, and actively adapts and synthesizes new models.
This setup captures the cascading effect of the human-machine interaction: the more attacks the predictive system detects, the more feeback it will receive from the analysts; this feedback, in turn, will improve the accuracy of future predictions.

Tsk Tsk. “principal” should be “principle”. :-)
“on 7.9% of attacks are detected” should be “only 7.9% of attacks are detected”.
As usual, a fascinating paper review. Are you going to follow up the ‘copula’ reference in a later paper? Does anyone else use this framework? What is it good for?
I spelt that wrong on principal ;)
Thanks for pointing these out, I’ll get them fixed later on today…