Hotspot Patterns: The formal definition and automatic detection of architecture smells – Mo et al. International Conference on Software Architecture, 2015
Yesterday we looked at Design Rule Spaces (DRSpaces) and how some design rule spaces seem to account for large numbers of the error-prone files within a project. Today’s paper brings us up to date with what the authors learned after examining hundreds of error-prone DRSpaces…
After examining hundreds of error-prone DRSpaces over dozens open source and commercial projects, we have observed that there are just a few distinct types of architecture issues, and these occur over and over again. We saw these issues in almost every error-prone DRSpace, in both open source and commercial projects. Most of these issues, although they are associated with extremely high error-proneness and/or change-proneness, cannot be characterized by existing notions such as code smells, or anti-patterns, and thus are not automatically detectable using existing tools.
There are five architectural hotspot patterns that are frequently the root causes of high-maintenance costs:
- Unstable interface
- Implicit cross-module dependency
- Unhealthy interface inheritance hierarchy
- Cross-module cycle
- Cross-package cycle
Where ‘modules’ are mutually independent file groups as revealed by a design rule hierarchy. Files involved in the above patterns have significantly higher bug and change rates than the average file in the same projects. Moreover, some files are involved in multiple of these patterns, in which case their bug rate and change rate increases dramatically.
The authors studied nine open source projects (Avro, Camel, Cassandra, CXF, Hadoop, HBase, Ivy, OpenJPA, and PDFBox) and one commercial project to undertake both a quantitative and qualitative assessment of the patterns predictive qualities. For these projects, information about the number of instances of each pattern, and the number of files involved in them can be found in the table below (click for larger view):

Architecture hotspots are indeed ubiquitous. Every project had at least one instance of every type of hotspot, and in some cases there were thousands of instances and thousands of files implicated. Architecture hotspots are real, and they are not rare.
By mining the project history (source code control and issue tracker) the authors obtained bug frequency (BF), bug churn (BC, the number of lines of code commited to fix a bug), change frequency (CF) and change churn (CC, the number of lines of code committed to make a change) metrics. Table III below shows how much these metrics increase compared to the average file in the project, for files involved in a hotspot pattern.
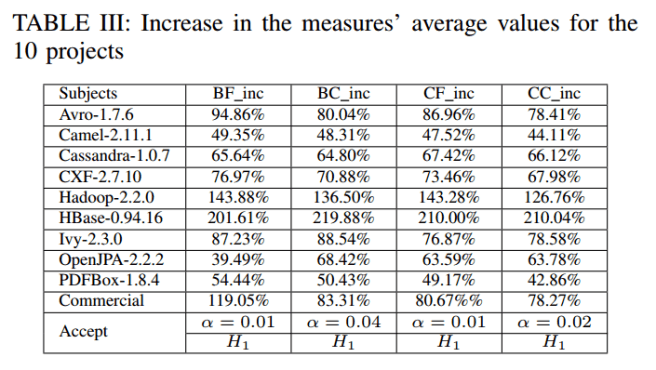
The four measures are consistently and significantly greater for the files that exhibit architecture issues. Therefore, we have strong evidence to believe that files exhibiting architecture issues will cause more project maintenance effort.
Of all the different hotspot patters, the greatest impact is attributable to the Unstable Interface and Cross-Module cycle patterns:
That is to say, while all of the hotspots contribute to bug frequency, change frequency, bug churn, and change churn, Unstable Interface and Cross-Module Cycle contribute the most by far.
For the commercial project (800 files, 56K Sloc, 4 years of development) the team identified 3 groups of files with Unhealthy Inheritance Hierarchies, 1 group with Implicit Cross-Module dependency (involving 27 files), and 2 groups of files with Unstable Interfaces (with 26 and 52 files respectively).
We communicated these issues, in the form of 6 DRSpaces, back to the chief architect…
- All of the hotspots bar one of the Unhealthy Inheritance Hierarchy groups were confirmed by the architect to be significant high-maintenance architecture issues.
- The architect confirmed they now intended to refactor the five high maintenance architecture issues.
When one of the Unstable Interface instances was reported, our collaborator realized that the interface was poorly designed; it was overly complex, and had become a God interface. Divide-and-conquer would be the proper strategy to redesign the interface. Based on the analysis results we provided, CompanyS is currently prosecuting a detailed refactoring plan to address these issues one by one.
I suppose I’d better give you the details of the architectural hotspot patterns so you can look out for them!
Unstable interface
Based on design rule theory, the most influential files in the system—usually the design rules—should remain stable. In a DRSpace DSM, the files in the first layer are always the most influential files in the system, that is, they are the leading files of the DRSpace. In most error-prone DRSpaces, we observe that these files frequently change with other files, and thus have large co-change numbers recorded in the DSM. Moreover, such leading files are often among the most error-prone files in the system, and most other files in their DRSpace are also highly error-prone. We formalize this phenomenon into an Unstable Interface pattern… If a highly influential file is changed frequently with other files in the revision history, then we call it an Unstable Interface.
Implicit cross-module dependency
Truly independent modules should be able to change independently from each other. If two structurally independent modules in the DRSpace are shown to change together frequently in the revision history, it means that they are not truly independent from each other. We observe that in many of these cases, the modules have harmful implicit dependencies that should be removed.
Unhealthy interface inheritance hierarchy
We have encountered a surprisingly large number of cases where basic object-oriented design principles are violated in the implementation of an inheritance hierarchy. The two most frequent problems are: (1) a parent class depends on one of its children; (2) a client class of the hierarchy depends on both the base class and all its children. The first case violates the design rule theory since a base class is usually an instance of design rules and thus shouldn’t depend on subordinating classes. Both cases violate Liskov Substitution principle since where the parent class is used won’t be replaceable by its subclasses. In these cases, both the client and the hierarchy are usually very error-prone.
Cross-module cycle
We have observed that not all cyclical dependencies among files are equally harmful, and that the cycles between modules—defined in the same way as in the Implicit Cross-module Dependency—in a DRSpace are associated with more defects… If there is a dependency cycle and not all the files belong to the same closest module, we consider this to be a Cross-Module Cycle pattern.
Cross-package cycle
Usually the package structure of a software system should form a hierarchical structure. A cycle among packages is typically considered to be harmful.
Hotspot detector tool
The Hotspot Detector automatically detects instances of the hotspot patterns, outputting a summary of all the architecture issues, the files involved in each issue, and the DSMs containing the DRSpaces with these issues. I couldn’t find any reference to a publicly available version you can download and experiment with though.

Another hocus pocus software engineering paper with bold claims, tables with lots of numbers and no real analysis (but it does have a page of fancy mathematical symbols to orgasm over).
Adrian, I hope there is a return to your normal high standard next week. I have been meaning to write a guide to finding worthwhile software engineering papers and your choice of papers in the last few posts have galvanized me into action. Here it is: http://shape-of-code.coding-guidelines.com/2016/06/10/finding-the-gold-nugget-papers-in-software-engineering-research/
Hi Derek,
One more to come in this line (on Monday). I’m guessing you won’t like that one either ;).
I’m trying to get an intuition for your argument that frequency of execution dominates any other factor in software bug discovery. It’s undeniably true that code paths which are not executed can’t lead to discoverable bugs. And depending on the nature of the bug, I can also see that code paths which are executed infrequently may reduce the chances of the bug being detected and reported. A third case where this rings true is with e.g. distributed systems with huge state spaces such that it takes repeated execution to explore enough of the space and find bugs. I followed the links through to your post about usage and fault reports on Firefox – is the crucial part II also posted somewhere? (Fault *reports* absolutely make sense to correlate with usage of course, but there can be a lot of dups in that).
Yet the projects in these studies are all pretty widely used, so the main code paths at least will get executed often. We know that some (sets of) files are changed more often in commits associated with bug reports. To explain this we can put forward a number of hypotheses:
(i) Programmers create bugs at a fairly even rate per Loc, the chances of discovering those bugs increases with the amount of execution of those lines of code, hence the most executed ‘files’ appear the most buggy. (I think this is the gist of your argument, if I understood correctly?)
(ii) Some logic structures or design patterns increase the chances that programmers will make mistakes, and hence given sufficient execution across a set of files, the subset that contain these structures or patterns will show as more error prone.
(iii) Some parts of the software address requirements that change more often over the lifetime of the software, hence they are updated more often, and those updates contribute new lines of codes which also introduce new bugs.
(iv). And probably a number of other hypotheses that could be constructed…
All of the first three above resonate with me based on the simple qualification of having written a lot of software over the years! Given sufficient (I won’t attempt to define ‘sufficient’ here ;) ) execution over a set of files in a project (such as widely used OSS projects) it makes sense to me that factor (i) would start to level out making room for the effects of (ii) and (iii) to be seen?
Back to infrastructure topics from Tues of next week! :)
Regards, Adrian.
Adrian,
Around 40% of fault reports are actually requests for enhancements: http://shape-of-code.coding-guidelines.com/2013/06/02/data-cleaning-the-next-step-in-empirical-software-engineering/ ; Mo et al do not mention any data cleaning effort to remove these. Might most enhancement requests be associated with the commonly used features, or is this just me wanting reality to fit my model of it?
Why would (i) start to level out? If the amount of code change decreased then the overall numbers would go down. I could see it not being linear, perhaps depending on the log of usage.
I once strongly believed that your point (ii) was true, now I am less certain (but few others share my point of view). There has been one experiment showing that developer knowledge about a construct is proportional to the frequency of occurrence in code: http://www.knosof.co.uk/dev-experiment/accu06.html There are papers showing a correlation between fault reports and low level constructs, but again these fail to take frequency of occurrence into account, even though this information is available: http://www.coding-guidelines.com/cbook/usefigtab.pdf
The part II of the firefox work has not been posted, but is on a long list of to be written part IIs.
Interesting paper, and results.
I’ve been doing DSM analysis for over a decade, and it’s nice to see the patterns correlated with data as shown. DSM tools are generally commercial, closed-source, and somewhat tedious to use.
I’d like to post an observation, which may be anecdotal, but anyhow…
Last year I made some DSMs on somewhat complex Go codebases and dependencies at the package level. (I say “tediously” as there are no automated DSM tools for Go, these were “hand-made”.)
I was surprised to see the resulting DSMs had no cycles in them.
After writing enough code in Go, it looks like the Go compiler and dependency system simply disallows them. If that is always the case – then the last 3 hotspot patterns described in this paper should be absent from Golang codebases:
3. Unhealthy interface inheritance hierarchy
4. Cross-module cycle
5. Cross-package cycle