Design Rule Spaces: A new form of architectural insight – Xiao et al. ICSE ’14
Continuing the theme of looking at ICSE 2016 papers, I want to share with you some interesting work by Xiao et al. on “Identifying and quantifying architectural debt.” That paper however draws heavily on two previous works that it makes sense to look at first. So today we’re going back to ICSE 2014 to look at “Design Rule Spaces.” In doing so, we’re taking a step up from thinking about finding problems “in the small” with individual lines of code, to thinking about design and architectural ‘bugs’.
The authors get off to a good start by stating that ‘our work is rooted in Baldwin and Clark’s concept of design rules – architectural interfaces that decouple the system into independent modules.’ That’s a book (Design Rules: The Power of Modularity that I happen to own and previously studied carefully shortly after it first came out (16 years ago, wow!).

Around that time I was leading the AspectJ project and studying anything I could get my hands on that related to software modularity (AOP is all about modular expression of cross-cutting concerns, but that’s a story for another day…). It’s over a decade since I went back to that book, and it’s a good reminder for me to go and mine its contents once more. Here’s an extract from the blurb:
[Baldwin and Clark] argue that the (computer) industry has experienced previously unimaginable levels of growth because it embraced the concepts of modularity, building complex products from smaller subsystems that can be designed independently yet function together as a whole. Modularity freed designers to experiment with different approaches, as long as they obeyed the established design rules. Drawing upon the literatures of industrial organization, real options, and computer architecture, the authors provide insight into the forces of change that drive today’s economy.
Does that sound like it might be relevant to any architectural trends you can think of at the moment ? ;)
Xiao et al. consider design rules, and modules framed by design rules, as the basic elements of software architecture. This enables them to divide a software system into a set of (overlapping) design rule spaces. Given a set of design rule spaces, they finally ask if there is any corellation between design spaces and error prone files – and find some very interesting connections:
- If the ‘lead file’ of a design space is error-prone, then a significant portion of the files within the design space also tend to be error prone.
- Although a project may have hundreds of error-prone files, they tend to concentrate in only a few error-prone design rule spaces (DRSpaces). In a study of JBoss AS, Hadoop Common, and Eclipse JDT, more than 50% of error-prone files are captured by just 5 error-prone DRSpaces in each project.
- All error-prone DRSpaces exhibit multiple structural and evolution issues, either violating commonly accepted design principles, or revealing exceptionally unstable architectural interfaces.
Thus understanding error-prone DRSpaces within your code base can point you to areas that will give a very high payoff if they are refactored to remove design flaws.
Design rule spaces and how to find them
Xiao et al. study object-oriented systems (specifically, Java code bases in this work), and explore design rules expressed through interfaces and abstract classes.
For example, if a software system employs an observer pattern, the pattern should be led by an observer interface, which decouples subjects from concrete observers. If the interface is stable, changes to concrete observers and subjects should not influence each other. In this case, we consider the observer interface as a design rule, and the subjects and concrete observers form two independent modules.
The types of relations explored in the paper are inheritance/realization, aggregation, and dependency. The authors also study one evolutionary relation, evolutionary coupling, which is derived from change history. This captures files that commonly change together.
A design structure matrix (DSM) can be constructed using one (or more) of these relations to reveal structure in the program. A DSM is a square matrix with each type (or file) represented in the same order in both the rows and the columns. A cell on the diagonal therefore represents a self-dependency, and shaded cells off the diagonal capture a relationship between the element on the row and the element on the column. As an easy example, here’s a DSM that simply considers two types to be related if they are in the same package:

To expose structure in a DSM, we can order the rows (and hence the columns since they follow the same ordering) in a special way which is called a design rule hierarchy (DRH). In a design rule hierarchy elements within lower layers of the hierarchy only depend on elements within higher layers (i.e. design rules), and elements within the same layers are separated into mutually independent groups (independent modules).
Here’s an example with two layers, indicated by the outlined boxes, formed by analysing the aggregation relationship between types:
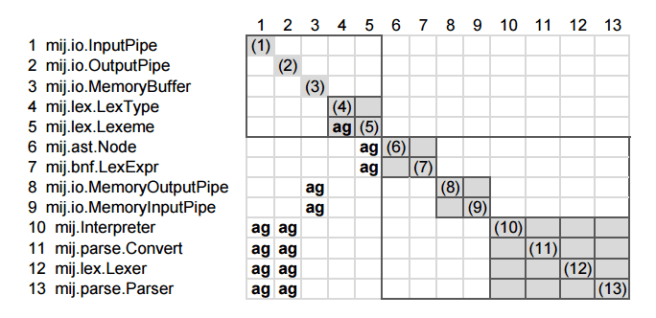
There are two layers in this DRSpace. The first layer, l1:(rc1-5), contains four modules of leading classes, and the second layer contains three meaningful modules. For example, m1:(rc8-9) is a MemoryBuffer module that contains two classes using it; m2:(rc10-13) groups major components such as parser and lexer together because they all communicate through pipes, and thus aggregate, mij.io.InputPipe and mij.io.OutputPipe.
For the same example program, here’s a DRSpace constructed around the dependency relation – it reveals how classes work together to accomplish a function:
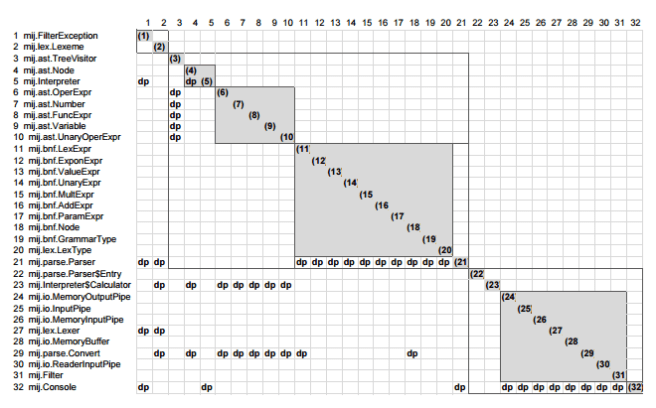
A DRSpace has one or more leading classes: the de facto design rules of the space. The classes within the first layer of a DRH are the leading classes.
The ArchDRH algorithm supports architecture recovery from source code (details of which are described in a separate paper). It also includes support for control programs such a a class with a main function, which usually depend on many other classes but is not depended on by them. ArchDRH separates such control elements into the bottom of a module and supports recursively clustering the rest of a module into a DRH structure.
The relationship between design rule spaces and bugs
The authors studied one target release each from JBoss AS, Hadoop Common, and Eclipse JDT, being careful to pick a release with at least 10 prior releases before it so that history DSMs (evolutionary coupling relationship) and error prone files could be identified (via issue trackers).
For each of the 30 most error-prone files in each project (those most often involved in bug fixes) the authors used their tool to find its DRSpace, and ranked the size of the DRSpace to find the top DRSpaces with at least 10 files in them. In JBoss, 9 of the 30 most error-prone files lead a DRSpace with at least 10 files, and for Hadoop Common and Eclipse JDT 11 of the files lead such a DRSpace.
The analysis shows that if a file is error-prone and leading a highly coupled DRSpace, then a significant portion of the DRSpace is also error-prone. “We thus call a DRSpace led by an error-prone file an error-prone DRSpace.”
A project may have hundreds of error-prone files. Can they be captured by a much smaller number of DRSpaces led by error-prone design rules?
The answer turns out to be that error-prone files are concentrated in just a few DRSpaces. For each project, the top 5 error-prone DRSpaces account for between 52% and 89% of the files within a bug space. (A bug space, bugN for some N, is the collection of files each of which has had at least N bugs in it. The authors study bug2, bug5, and bug10). In the JBoss project as an example, the first 15 DRSpaces cover 66% of Bug2, the first 9 DRSpaces cover 57% of Bug5, and the first 3 DRSpaces cover 78% of Bug10.
The results reported in the previous sections imply that large numbers of error-prone files belong to the same few DRSpaces. The question is whether these DRSpaces can provide insights into the reasons why these files are error-prone.
After studying all of the error-prone DRSpaces of each project, the authors observed that they often exhibit one of the following two problems:
- Aggregation/dependency cycles
- Problematic inheritance hierarchies, manifested for example as parent and children frequently changing together, a client inheriting a parent class while aggregating its child, a parent depending on one of its children, etc.
For example, FSNamesystem has 190 bug fixes and is ranked as the number 1 most error-prone file in Hadoop Common. “From its DRSpace with 17 files, we can see that FSNamesystem is involved in a dependency cycle with 11 files, and an aggregation cycle with 7 elements.”
Consider Hadoop’s JobTracker as an example of problematic inheritance hierarchies:
In its inheritance DRSpace, after choosing dependency and aggregation as secondary relations, we saw that JobTracker depends on conf.Configuration, and aggregates mapred.JobConf, which, in turn, is a child of conf.Configuration. Both of mapred.JobConf and conf.Configuration are highly buggy, ranking 21st and 26th respectively. They both lead large error-prone DRSpaces, with 76 and 54 files respectively. Since JobTracker either depends on or aggregates them, it is not surprising that it is the most error-prone file of the entire project.
(Note: FSNamesystem and JobTracker can’t both be the most error-prone file in the project, but I get the general idea…).
The analysis also revealed the presence of implied ‘shared secrets’ between files were there were large numbers of co-changes but neither structural relations between them nor obvious structural problems.

I was also a fan of Baldwin and Clark’s book when it came it. A shame that vol II has not appeared. Unfortunately it has not lived up to its promise; I suspect because hardware systems have physical limitations that restrict the number of interconnects that are practical, while software has no such physical limits.
This paper makes the classic mistake of thinking that files containing lots of faults are more error prone than the rest; if you control for frequency of execution they are just as error prone as the rest. Frequently executed files contain functionality that is used a lot and so tends to be more complicated because the common usage gets bells and whistles added to it, being executed a lot means more faults are found.
The paper is a candidate for being added to the spurious correlations website: http://www.tylervigen.com/spurious-correlations
More faults in files correlates with structural complexity because of frequency of usage.
Derek,
I find your comments on this, and our other papers, offensive. If you want to have a debate about methodology, there is no need to resort to name-calling, using terms like “hocus pocus” and “clueless”. Why don’t we have a discussion about the science–what you call “lots of numbers and no real analysis”.
Your counter-argument to our claims is nothing more than name-calling. You think that by naming a flawed methodology and ours in the same sentence, that somehow means that our methodology is flawed. You claim (without providing any evidence) that we have found “spurious correlations”. A spurious correlation occurs when there is no plausible relationship between cause and effect, such as the divorce rate in Maine correlating with the U.S. per capita consumption of margarine. However, in our analyses, we have established plausible causal links between the cause (design flaws) and the effects (bugs, changes, and churn). We have interviewed and worked with dozens of architects across many projects. And we see the effects that we have reported across a wide variety of project sizes, languages, and domains. Finally, when we show our results to developers and architects they say that our explanations make sense. And when they fix the design flaws, bug rates, effort, and lines committed go down. And you call this correlation spurious? I think not. In fact, we have recently done a causal analysis (see “Causal Inference in Statistics: A Primer” by Pearl, Glymour and Jewell for an introduction) and have obtained further statistical evidence that the links that we have found between design flaws and detect- and change-proneness are indeed causal.
Would you say that the correlation of cigarettes smoked and prevalence of lung cancer is also spurious? Hopefully not, because there is a plausible causal link between stimulus and response, strongly supported by data and experience. So too here.
We have made our methodology and our data public. Why not actually look at it and try to provide some counter-claims, or prove us wrong via a chain of reasoning and analysis, supported by evidence? That is how science makes progress, not by name-calling.
I will not bother to dispute your criticisms of our other papers here but they are similarly flawed. I am happy to debate the merits of our methodology. But, if you care to engage and are a gentleman, I first expect an apology and a retraction of your flames.
Rick Kazman