On the ‘naturalness’ of buggy code – Ray, Hellendoorn, et al. ICSE 2016
Last week we looked at a simpler approach to building static code checkers that by understanding less about the overall code structure and just focusing in on the things that really mattered was able to produce competitive results from very small checker implementations. Today’s paper shows an approach which is also able to highlight code likely to contain a bug, yet has no understanding at all of the meaning of the code! It’s especially effective when coupled with static code checking tools to help prioritize the findings they report.
Most natural language (NL) is both repetitive and predictable, thus enabling humans to communicate reliably & efficiently in potentially noisy and dangerous situations. This repetitive property, i.e. naturalness, of spoken and written NL has been exploited in the field of NLP: Statistical language models (from hereon: language models) have been employed to capture it, and then use to good effect in speech recognition, translation, spelling correction, etc. As it turns out, so it is with code!
You can build a language model that is trained on a code base. Such a model will flag syntactically incorrect code as improbable, but your compiler should be flagging that too! By analysing code in open source repositories the authors found that it is still possible to detect statistically improbable and yet syntactically correct lines of code.
We hypothesize that unnatural code is more likely to be wrong, thus, language models actually help zero-in on potentially defective code; in this paper, we explore this.
To answer this question, 8,296 bug fix commits across 10 different open source projects are analysed to see if (a) buggy lines do indeed appear to be more unnatural, and (b) bug fixes appear more natural than the bugs they replace. Based on this the authors also investigate (c) whether naturalness of lines is a good way to guide inspection effort (e.g. during code reviews), (d) how this compares to lines highlighted by static code checking tools, and (e) whether static code checking tools and naturalness checking can be combined in useful ways. The projects analyzed are Atmosphere, ElasticSearch, Facebook Android SDK, Netty, Presto, Derby, Lucene, OpenJPA, QPid, and Wicket.
Buggy lines do indeed on average have higher entropries (look more unusual / unnatural) than non-buggy lines:
For each project, we compare line entropies of buggy and non-buggy lines. For a given snapshot, non-buggy lines consist of all the unchanged lines and the deleted lines that are not part of a bug-fix commit. The buggy lines include all the deleted lines in all bug-fix commits. Figure 4 (below) shows the result, averaged over all the studied projects. Buggy lines are associated with higher entropies.

Furthermore, as also illustrated in the above figure, when comparing fixed lines (lines added in bug fixes) to the buggy lines they replace, we again see that their average entropy is lower. This comparison is actually done between ‘hunks’ of code since it can be hard to establish a one-to-one correspondence between a buggy line and a fixed line, as often a buggy line may be fixed by a number of new lines.
Here are some examples of unnatural looking lines that NBF (Naturalness Bug Finder) detected along with the fix and the associated drop in entropy:

The technique doesn’t always work though, consider these next two examples:

In example 4, the bug is actually a cut-and-paste error where the code referencing ‘maxChunkSize’ has been copied from somewhere else. The fix that changes it to ‘maxHeaderSize’ makes the code look more surprising since the statement it replaced was already in the code base in more than one place, whereas the new (fixed) version was not.
In example 5, it just happens that the reference to logger is newly introduced in the corpus. Nevertheless, overall the entropy of buggy lines drops after bug fixes with statistical significance.
To find out whether unnatural lines are helpful in directing attention in code reviews, the authors computed an AUCEC (Area Under the Cost-Effectiveness Curve) metric assuming that the cost is the inspection effort, and the payoff is the count of bugs found. Overall this shows that entropy is a much better way of choosing lines for inspection than random selection of lines (though of course no-one ever actually selects lines at random for a code inspection do they???). Thus it can be a good guide when indicating parts of the code that are worth looking at more closely. The chart below compares the best performing NBF approach (turquoise / dotted line) with random line selection (purple / dash-dot line).
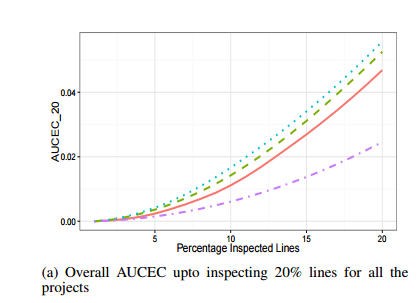
Comparing against the results from the PMD and FindBugs tools, the authors found that NBF had comparable performance in defect prediction.
Notably, NBF had both the highest mean and standard deviation of the tested models, whereas PMD’s performance was most robust. This suggests a combination of the models: We can order the warnings of the SBF using the $gram+wType (NBF) model. In particular, we found that the standard priority ordering of the SBF is already powerful, so we propose to re-order the lines within each priority category.
To this end, a combined model which used NBF to rank issues found by the static bug finding tools within each priority category gave the best overall results. “In all cases, the mix model was either significantly better or no worse than any of the other approaches when averaged over all the studied releases.
Ordering Static Bug Finding (SBF) tool warnings by priority and entropy significantly improves SBF performance.
Language modeling for code
A widely used approach for natural language modeling is n-gram modeling. Suppose you have a sequence of tokens, you can estimate the probability of the sequence as a product of the conditional probabilities of seeing each token in the sequence, given the tokens that have gone before it. Let’s say the sequence is “Hello, World.” We would have P(“Hello”) * P(“World” | “Hello”). Given the huge number of possible prefixes the probabilities become impossible to estimate, and so n-gram models use only the n-1 most recent tokens. All prefixes with the same n-1 tokens are in the same equivalence class.
The ngram language models have been shown to successfully capture the highly repetitive regularities in source code, and were applied to code suggestion tasks [18]. However, the ngram models fail to deal with a special property of software: source code is also very localized. Due to module specialization and focus, code tends to take special repetitive forms in local contexts. The ngram approach, rooted as it is in NL, focuses on capturing the global regularities over the whole corpus, and neglects local regularities, thus ignoring the localness of software. To overcome this, Tu et al. [36] introduced a cache language model to capture the localness of code.
The cached language model is denoted $gram for short. The global ngram model is combined with a cache that extracts ngrams from the local context. When assessing the probability of a given token giving the preceding n-1 tokens the model combines a probability based on the content of the cache, with the global probability. The weighting is such that when the prefix occurs only a few times in the cache then the global probability is preferred, but when the prefix occurs more frequently in the cache then the local probability is preferred.
We measure the naturalness of a code snippet using statistical language model with a widely-used metric – cross-entropy (entropy in short) [18, 2]. The key intuition is that snippets that are more like the training corpus (i.e. more natural) would be assigned higher probabilities or lower entropy from an LM trained on the same corpus. Given a snippet S = ti . . . tN , of length N, with a probability PM(S) estimated by a language model M, the entropy of the snippet is calculated as:

where P(ti|h) is calculated using the cached language model ($gram).
It turns out that some kinds of program language statements will naturally have higher entropy than others:
We manually examined entropy scores of sample lines and found strong associations with lexical and syntactic properties. In particular, lines with many and/or previously unseen identifiers, such as package, class and method declarations, had substantially higher entropy scores than average. Lines such as the first line of for-statements and catch clauses had much lower entropy scores, being often repetitive and making use of earlier declared variables.
To account for this, entropy scores are normalized according to the type of code statement (strictly, the lowest AST node that includes the full line under investigation). This means that a line is essentially being compared to see how ‘normal’ it is compared to other lines of the same type. In a final twist, bugs are more or less likely for different types of line – for example, import statements tend to be less buggy than try-catch blocks. So we can further weight scores based on relative bug-proneness of different line types, as determined by analysing previous snapshots of the codebase. This gives the final NBF model as used in the paper, which the authors name $gram + wType.
