From Aristotle to Ringelmann: A large-scale analysis of team productivity and coordination in open-source software projects – Scholtes et al. ICSE 2016
A slightly different flavour of papers this week as we dip into the ICSE 2016 conference proceedings. We kick things off with a study looking at the effect of development team size on productivity. This paper specifically studies open source projects (580,000 commits from 58 of the 100 most frequently forked projects on GitHub), but the related work section includes good background on results for software projects in general.
Since Ringelmann in 1913 we’ve known that individual performance tends to decrease with increasing group size. (Ringelmann’s original study involved a tug-of-war between two teams). Ringelmann attributed the effect mainly to the increasingly challenging coordination in larger groups (see the beta coherence term in the USL). There are also social factors at work: the tendency of group members to spend less effort in larger groups is generally attributed to situations characterized by a lack of individual accountability and shared responsibility.
In 1975 Fred Brooks applied this to software development and gave us ‘The Mythical Man Month’ and Brook’s law – the size of a development team negatively affects its productivity. A number of subsequent studies have backed up these results.
- Paiva et al. (2010) argue that developers assess the size of a development team as one of those factors that have the strongest negative impact on productivity.
- Blackburn et al. (1996) found a negative correlation between the productivity of software development teams and their size, referring to the phenomenon as the “productivity paradox.”
- Maxwell et al. (1996) found that productivity significantly decreases with increasing team size and argue that this “is probably due to the coordination and communication problems that occur as more people work on a project.”
- Mockus et al. (2000,2002) found that a small core of developers in Apache Httpd and Mozilla Firefox were responsible for the vast majority of code changes. They argue that the size of effective teams is limited to 10-15 people. (The finding that the majority of code is developed by a small core group of developers has been validated in a number of empirical studies looking at the distribution of code distributions).
- Adams et al. (2009) identify three basic types of projects when it comes to team size and productivity: (i) those below 10 developers, with broadly comparable coordination effort; (ii) those that are able to introduce sufficient modular structure such that the growing number of developers does not lead to a corresponding increase in coordination efforts; and (iii) projects where beyond a critical team size, coordination efforts quickly increase in a super-linear fashion.
Advocates of microservices of course (consciously or otherwise) are banking on Adams’ case (ii) to keep coordination costs down (and hence deliver software faster). I note that this is primarily a property of a sufficiently modular structure and that of the many ways it is possible to decompose a system into modules, some will be better at achieving this objective than others.
Management science and organizational theory turn out to have a nice turn of phrase to describe what happens when productivity goes down as resources are added: “diseconomies of scale.”
After all of this research, Sornette et al. published the surprising result in 2014 that the productivity of OSS communities increases with team size in a super-linear fashion. (This explains the Aristotle reference in the paper title – it comes from his quote “the whole is greater than the sum of the parts.”) Can it really be true? I’m afraid it looks like the answer is no. Sornette et al. studied the number of commits as an indicator of productivity. While this may seem reasonable on the surface, in today’s paper Scholtes et al. take a deeper look and show that all commits are not made equal. When you look at actual contributions (they analyse commits and settle on the Levenshtein edit distance between before and after files as a measure of contribution) it turns out that open source projects follow the same laws as everywhere else, and adding developers reduces the average productivity.
Using a large and open data set, our study validates the common assumption in software engineering that the size of a team negatively affects the average productivity of its members. This highlights the fact that, possibly due to the duplication of efforts, increasing coordination overhead, as well as decreasing accountability, software development projects represent diseconomies of scale.
Along the way, we get some nice intermediate results, for example “we observe that 90% of all consecutive commits occur within time periods of less than 295 days. In other words, the chance of a developer committing again after having been inactive for more than 295 days is less than 10%.” A number of prior studies have also shown that the size of commits follows a highly skewed distribution as well. It is typically a small number of large commits which are fundamentally important in the evolution of a piece of software, while the majority of commits are minor contributions.
Looking at the distribution of how often developers commit, we find the following:
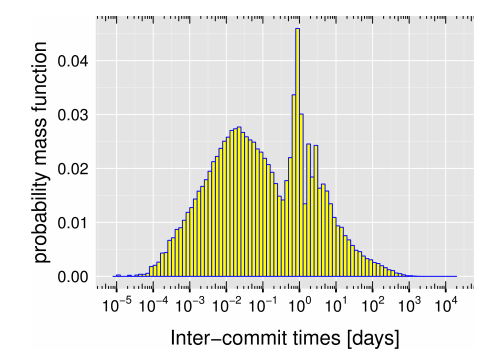
There are peaks at approximately once every 30 minutes, and once a day. (My guess – these correspond to ‘commit early, commit often’ working practices, and ‘end of working day’ commits).
For small numbers of active developers, the mean number of commits per developer exhibits a large variance over more than two orders of magnitude. As the number of active developers increases, one observes a decrease in the mean number of commits per developer. In particular, for projects with more than 50 developers committing in a given week, we observe a mean number of about two commits per week, while the mean number of commits for projects with a single active developer is about ten times as large. Even if one were to consider the mean number of commits as a proxy for developer productivity, this finding is inconsistent with an economy of scale in collaborative software development, recently found by a similar analysis on a different data set (Sornette et al, 2014).
A similar pattern emerges when looking at contribution as measured by Levenshtein edit distance: “we observe that for projects with more than 50 active developers, the mean developer contribution is about 1000 characters while it is -on average – at least one order of magnitude larger for projects with a small number of active developers.”
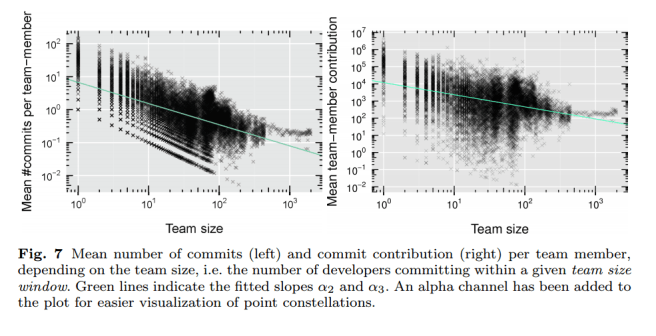
Since the authors are measuring mean productivity, these numbers are not in the least surprising to me. We know that a small number of core developers are responsible for most of the development, so as we add increasing numbers of casual committers making less frequent and substantive contributions of course the average productivity will go down! What would be fascinating to see, but we don’t get any insight to in the results, is what happens to the productivity of that core group as the total number of developers goes up? Open source projects definitely differ from typical closed source commercial projects in this regard – the latter tend to add only full-time team members, whereas open source projects can easily add casual contributors.
Section 5 of the paper gives us an interesting analysis that helps us get closer to the question of what happens to core team productivity. The authors create a Task Assignment matrix capturing the association between developers and the source code regions that they have edited.
We particularly consider the time-stamps of commit actions, as well as the detailed code changes within all of the committed files in order to build directed and weighted networks which capture the time-ordered co-editing of source code regions by different developers. We call the resulting network topologies time-ordered co-editing networks and throughout this article we will use them as a first-order approximation for the emerging coordination overhead.
Here’s a small-scale example of the networks that are built up:
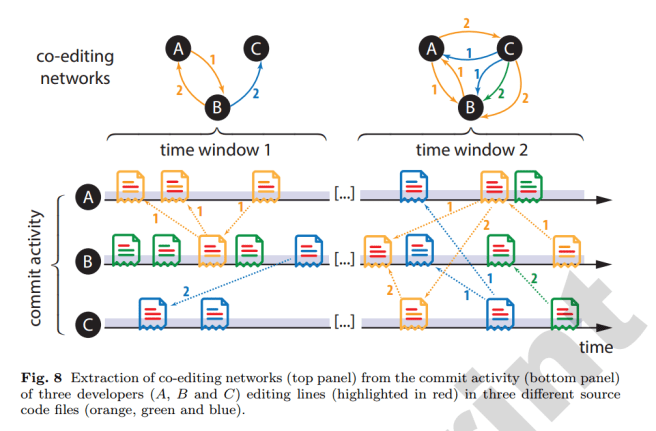
Looking across the data from the 58 open source projects in the study, the authors selected ZF2 as the project with the worst productivity drop as team size increased, and SPECS as the project with the least productivity drop as team size increased.
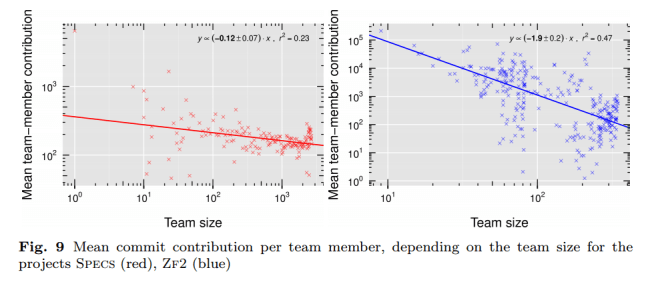
Looking at the networks for these two projects, you can clearly see that SPECS (red) has very little shared editing (coordination), whereas ZF2 (blue) has a much more strongly connected graph. This fits the hypothesis that coordination costs are responsible for much of the productivity drop.

A closer look at the two projects in our case study allows us to further substantiate our quantitative findings with project-dependent, intuitive explanations. The specs project maintains a public repository for meta-information on Apple Cocoa modules, that can be managed via the library dependency management tool CocoaPods. In particular, the repository consists of more than 7, 000 different libraries, each containing a set of JSON files which are authored and maintained by different, small teams of developers. As such, specs can be seen as a rather extremal example for a maximally modular project, in the sense that it consists of thousands of independent modules each being developed by different developers with no or at least minimal coordination needs. The ZF2 project on the other hand, develops a component-oriented web framework named Zend. Compared to the fully independent modules in the specs project, the code base of ZF2 is likely to be much more integrated, thus not allowing for a non-overlapping mapping between developers and source code regions. As such, the commit actions of a large number of developers are likely to produce a much more densely connected co-editing network.
Doing the same analysis across all projects shows that projects with strongly negative and significant slopes for the scaling of productivity also exhibit pronouncedly positive scaling exponents for the growth of the mean (weighted) out-degree in the co-editing network.

This is one of those papers that defines a word to have one very specific meaning (productivity to be volume of code changed in this case) and then makes use of other common-usage meanings of the word to claim to have found something interesting. Don’t be taken in by the quantity of plots and the diversionary discussion of side issues.
The usual target word for this approach is “quality” (please no skin deep reviews, like this one, of papers using the term quality).
Apart from the questionable use of terminology, the paper also fails to seriously investigate how much time each developer in a ‘team’ invested in working on the particular open source project.
If you are interested in project issues, then look at one of the quality papers from the Rome period. Here is a very good one: http://www.dtic.mil/get-tr-doc/pdf?AD=ADA030798
Hi Derek,
That looks like a monster read (346 pages)! That said, I do like the style of many of the earlier papers in the field. I couldn’t see any reference to models relating developer productivity to team size though (but then again, I haven’t had a chance to read the whole paper in depth!).
In compressing the 45 pages of this paper into a short summary, I skipped over the details of the section on _activity spans_ to determine active team members. The thing I would have liked to see though (as I said in my review), is not the effect of adding team members on the average productivity, but on the productivity of the core developers (minus the long tail of less frequent committers within the activity span).
The authors are up-front that their focus is on ‘productivity as measured by output in terms of source code artifacts produced by software developers.’. I don’t recall any equating of productivity with quality on their part. Quality as it relates to code base size is another (very interesting) area altogether!
Regards, Adrian.
The authors are using ‘productivity’ as a marketing term (‘quality’ is also often used in this way in software engineering). They are hoping that readers will make the same mistake that Nat Torkington has made at Four-short-links and think the paper is about productivity and not volume of code (an easily abused metric and one that mitigates against producing simple solutions).
Sorry, I forgot that that paper was rather long. There is lots of other good stuff to be found in the Rome archives: http://shape-of-code.coding-guidelines.com/2016/05/23/the-fall-of-rome-and-the-ascendancy-of-ego-and-bluster/
Thanks for the link! Will add to my reading list :).
I’m having a bit of trouble with the last part. They compare mean out degree to some slope, not clear to me what the slope is:
is it mean out degree / team size; or: MOD / size of coordination network ?
I believe what the authors mean here is that projects where productivity tends to decline strongly as team size grows correlate with projects in which coordination costs (on the assumption that co-editors coordinate) also increase strongly as team size grows…
A similar discussion was once conducted by late Aaron Swartz regarding, who writes Wikipedia, see
http://www.aaronsw.com/weblog/whowriteswikipedia
What’s missing in the post is the relation to the project maturity. In the early phase a small team is often doing iterative commits and the foundation must be developed. This decreases over time as learning kicks in and the maturity rises. In the mid and later phases smaller changes from more contributors are committed for a better quality and potentially (smaller) new features. If a mature project refactors large portions in the mid/late phase you will see (again) large contributions from few people and the cycle starts from the beginning.
Abstract: I would distinguish between development and maintenance when breaking down code commits even if the goal is to measure mean productivity.