Semi-supervised sequence learning – Dai & Le, NIPS 2015.
The sequence to sequence learning approach we looked at yesterday has been used for machine translation, text parsing, image captioning, video analysis, and conversational modeling. In Semi-supervised sequence learning, Dai & Le use a clever twist on the sequence-to-sequence approach to enable it to be used for unsupervised training. That makes a big difference because there is plenty of data in the world, but only the tiniest fraction of it is labeled (for supervised training). They use their unsupervised sequence autoencoder to pre-train an LSTM, with the weights obtained then being used to initialize a standard LSTM for a supervised training task (document classification).
So how do you use sequence to sequence with unlabeled data? Recall that the sequence to sequence architecture uses one input LSTM, generating an encoded vector, which is then used as input to an output LSTM.
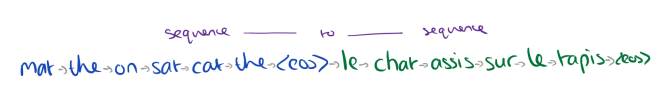
Dai and Le simply set the target sentence to be exactly the same as the input sentence! Say we input the English sentence “The cat sat on the mat.” This will get turned into a vector representation of the sentence, from which the output LSTM will be trained to produce “The cat sat on the mat.” It still requires the learned representation to capture the meaning of the sentence, but gives us much more data we can train on!
The overall system (using a sequence autoencoder to pre-train, followed by LSTM supervised learning) is abbreviated as SA-LSTM. It’s a somewhat unusual paper, because that’s it for the method description, everything else is evaluation!
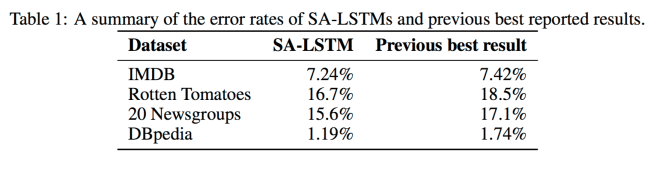
Using SA-LSTMs, we are able to match or surpass reported results for all datasets. It is important to emphasize that previous best results come from various different methods. So it is significant that one method achieves strong results for all datasets, presumably because such a method can be used as a general model for any similar task. A summary of results in the experiments are shown in Table 1.
An evaluation on the IMDB movie sentiment dataset shows the benefits of SA-LSTMs as compared LSTMs trained from scratch. The plain LSTM approach is unstable and training breaks down very quickly if the number of hidden units or number of backprop steps is increased. But when using the sequence autoencoders, the same changes have very little effect, meaning that the models become more practical to train.
On the Rotten Tomatoes sentiment dataset (10,662 documents) there is a risk of overfitting as the dataset is relatively small. To improve performance, the authors add unlabeled data from the IMDB dataset and from Amazon movie reviews to the autoencoder training stage. The SA-LSTM trained just on the Rotten Tomatoes dataset achieves a test error rate of 20.3%, with unlabeled data from IMDB used in addition in pre-training, the error rate falls to 18.6%, and with the Amazon movie reviews, to 16.7%.
This brings us to the question of how well this method of using unlabeled data fares compared to adding more labeled data. As argued by Socher et al. [29], a reason why the methods are not perfect yet is the lack of labeled training data, they proposed to use more labeled data by labeling an additional 215,154 phrases created by the Stanford Parser. The use of more labeled data allowed their method to achieve around 15% error in the test set, an improvement of approximately 5% over older methods with less labeled data.We compare our method to their reported results [29] on sentence-level classification. As our method does not have access to valuable labeled data, one might expect that our method is severely disadvantaged and should not perform on the same level. However, with unlabeled data and sequence autoencoders, we are able to obtain 16.7%, ranking second amongst many other methods that have access to a much larger corpus of labeled data. The fact that unlabeled data can compensate for the lack of labeled data is very significant as unlabeled data are much cheaper than labeled data. The results are shown in Table 5.

The authors also apply SA-LSTMs to datasets with larger documents (20 newsgroups), to character-by-character classification and even to non-textual (image) data and achieve good results in all cases.
In this paper, we showed that it is possible to use LSTM recurrent networks for NLP tasks such as document classification. Further, we demonstrated that a language model or a sequence autoencoder can help stabilize the learning in LSTM recurrent networks. On five benchmarks that we tried, LSTMs can reach or surpass the performance levels of all previous baselines.

One thought on “Semi-supervised sequence learning”
Comments are closed.