Slacker: Fast Distribution with Lazy Docker Containers – Harter et al. 2016
On you marks, get set, docker run -it ubuntu bash. How long did it take before you saw the bash prompt? In this wonderful FAST’16 paper, Harter et al. analyse what happens behind the scenes when you docker run a container image, and provide a fascinating look at the makeup of container images along the way. Containers are much lighter-weight and faster starting than virtual machines, but in many scenarios where an image must be pulled before the container can be run, startup can still take a surprisingly long time (median about 25s as reported in Large-scale cluster management at Google with Borg). Based on their analysis of where all that time goes, the authors built ‘Slacker’ – a Docker storage driver that is optimised for fast container startup (and equivalent performance once the container is started).
Among other findings, our analysis shows that (1) copying package data accounts for 76% of container startup time, (2) only 6.4% of the copied data is actually needed for containers to begin useful work, and (3) simple block de-duplication across images achieves better compression rates than gzip compression of individual images… Slacker speeds up the median container development cycle by 20x and deployment cycle by 5x.
Background
The docker run command will pull images from a repository if they are not already available locally…
New containers and new images may be created on a specific worker by sending commands to its local daemon. Image sharing is accomplished via centralized registries that typically run on machines in the same cluster as the Docker workers. Images may be published with a push from a daemon to a registry, and images may be deployed by executing pulls on a number of daemons in the cluster. Only the layers not already available on the receiving end are transferred. Layers are represented as gzip-compressed tar files over the network and on the registry machines. Representation on daemon machines is determined by a pluggable storage driver.
A Docker storage driver manages container storage and mounting. The AUFS storage driver is a common default. As a union file system it does not store data directly on disk, but instead uses another file system (e.g. ext4) as underlying storage. A union mount point provides a view of multiple directories in the underlying file system.
The AUFS driver takes advantage of the AUFS file system’s layering and copy-on-write (COW) capabilities while also accessing the file system underlying AUFS directly. The driver creates a new directory in the underlying file system for each layer it stores.
Using a HelloBench tool that they wrote, the authors analyse 57 different container images pulled from the Docker Hub. Across these images there are 550 nodes and and 19 roots.
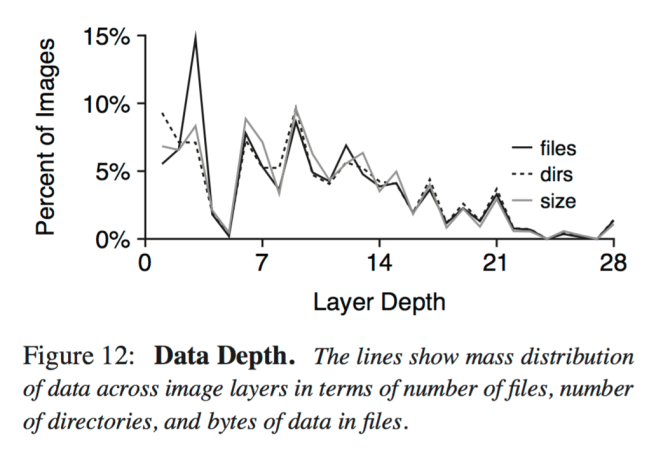
The number of files, directories, and bytes were analyzed by layer for these images. Some data is as deep as the 28th level, but mass is more concentrated to the left. Over half the bytes are at depth of at least nine.
Where does all the time go?
HelloBench measures the time taken for these images to start. What ‘start’ means varies by image type: compiling and running or interpreting a simple ‘hello world’ program in the applicable language; executing a simple shell command; producing the first ‘up and ready’ message to standard out; or first response on an exposed port.
For each image, we take three measurements: its compressed size, uncompressed size, and the number of bytes read from the image when HelloBench executes. Figure 5 (below) shows a CDF of these three numbers. We observe that only 20MB of data is read on median, but the median image is 117MB compressed, and 329 MB uncompressed.
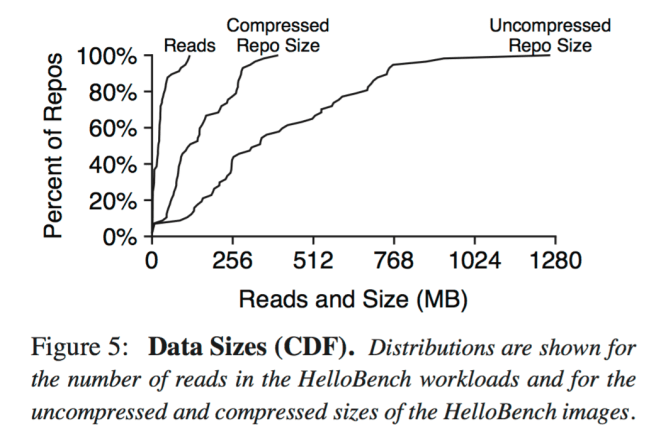
The average uncompressed image is 15 x larger that the amount of image data needed for container startup. Since the compressed format is not suitable for running containers that need to modify data, workers typically store data uncompressed.
Deuplication is a simple alternative to compression that is suitable for updates. We scan HelloBench images for redundancy between blocks of files to compute the effectiveness of deduplication. Figure 7 (below) compares gzip compression rates to deduplication, at both file and block (4 KB) granularity. Bars represent rates over single images.
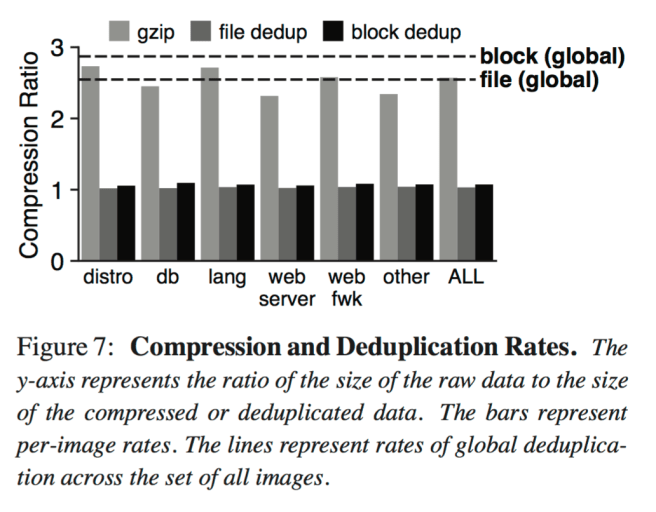
Whereas gzip achieves rates between 2.3 and 2.7, deduplication does poorly on a per-image basis. Deduplication across all images, however, yields rates of 2.6 (file granularity) and 2.8 (block granularity).
Once a containerized application has been built, a developer can push the image to a central repository. A number of workers pull the image from there and each then runs the application.
We measure the latency of these operations with HelloBench, reporting CDFs in Figure 8. Median times for push, pull, and run and 61, 16, and 0.97 seconds respectively… The pattern holds in general: runs are fast while pushes and pulls are slow. The average times for push, pull, and run are 72, 20, and 6.1 seconds respectively. Thus, 76% of startup time will be spent on pull when starting a new image hosted on a remote repository.
These pushes and pulls are not only high latency, they also consume network and disk resources, limiting scalability.
Publishing images with push will be painfully slow for programmers who are iteratively developing their application, though this is likely a less frequent case than multi-deployment of an already published image.
The number of layers in an image is also an issue. The authors look at two performance problems which layered file systems are prone to: lookups to deep layers, and small writes to non-top layers.
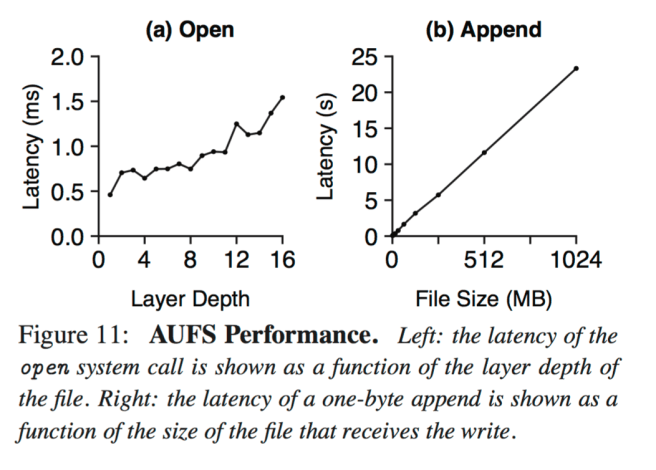
As show by Figure 11b (above), the latency of small writes corresponds to the file size (not the write size), as AUFS does COW at file granularity. Before a file is modified, it is copied to the topmost layer, so writing one byte can take over 20 seconds. Fortunately small writes to lower layers induce a one-time cost per container; subsequent writes will be faster because the large file will have been copied to the top layer.
As we saw previously, over half the data in the images examined is at least 9 layers deep. Flattening layers is one potential solution, but this could require additional copying and void the other COW benefits that layered file systems provide.
When a worker runs the same image more than once, some reads during the second run could potentially benefit from cache state populated by reads during the first run. Figure 14 (below) shows that the potential benefits are significant. Across all workloads, the read/write ratio is 88/12, and 99% of reads could potentially be serviced by cached data from previous runs.
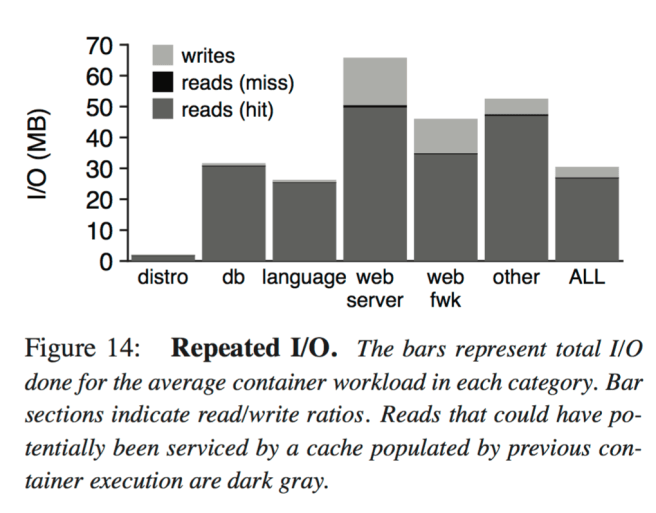
The same data is often read during different runs of the same image, suggesting cache sharing will be useful when the same image is executed on the same machine many times. In large clusters with many containerized applications, repeated executions will be unlikely unless container placement is highly restricted. Also, other goals (e.g., load balancing and fault isolation) may make colocation uncommon. However, repeated executions are likely common for containerized utility programs (e.g., python or gcc) and for applications running in small clusters. Our results suggest these latter scenarios would benefit from cache sharing.
The design of Slacker
Slacker has five goals:
- Make pulls very fast
- Introduce no slowdowns for long-running containers
- Reuse existing storage systems whenever possible
- Utilize the powerful primitives provided by a modern storage server, and
- Make no changes to the Docker registry or daemon, except in the storage driver plugin.
The Slacker architecture looks like this:
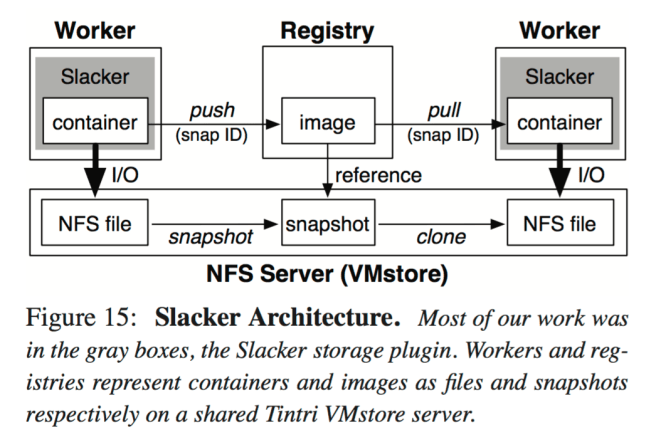
The design is based on centralized NFS storage, shared between all Docker daemons and registries. Most of the data in a container is not needed to execute the container, so Docker workers only fetch data lazily from shared storage as needed. For NFS storage, we use a Tintri VMstore server. Docker images are represented by VMstore’s read-only snapshots. Registries are no longer used as hosts for layer data, and are instead used only as name servers that associate image metadata with corresponding snapshots. Pushes and pulls no longer involve large network transfers; instead, these operations simply share snapshot IDs. Slacker uses VMstore snapshot to convert a container into a shareable image and clone to provision container storage based on a snapshot ID pulled from the registry. Internally, VMstore uses block-level COW to implement snapshot and clone efficiently.
Storage for each container is represented as a single NFS file, formated as an ext4 file system. Since it is backed by a network disk, Slacker can lazily fetch data over the network. Slacker layers are effectively flattened at the file level, but Slacker still benefits from COW by using block-level COW within VMstore. Block-level deduplication happens within VMstore providing space savings between containers running on different Docker workers. Slackers choice to back each container with a single ext4 instance is in contrast to the AUFS policy of a single ext4 instance with different directories within it for different containers. This has both journalling and isolation implications:
With AUFS, all containers will share the same journal, providing greater efficiency. However, journal sharing is known to cause priority inversion that undermines QoS guarantees, an importand feature of multi-tenant platforms such as Docker. Internal fragmentation is another potential problem when NFS storage is divided into many small non-full ext4 instances. Fortunately, VMstore files are sparse, so Slacker does not suffer from this issue.
Slacker uses VMstore snapshot and clone operations to implement the Docker storage driver Diff and ApplyDiff operations. These are called by Docker push and pull operations respectively. On push, Slacker asks VMstore to create a snapshot of the NFS file representing the layer. The returned snapshot ID (about 50 bytes) is embedded in a compressed tar file (because this is what Docker expects to see!) and sent to the registry. On a pull, Slacker will receive a snapshot ID from the registry, from which it can clone NFS files for container storage.
Slacker’s implementation is fast because (a) layer data is never compressed or uncompressed, and (b) layer data never leaves the VMstore, so only metadata is sent over the network.
This makes Slacker partially compatible with other daemons running non-Slacker drivers. A Slacker driver can fall back to regular decompressing instead of cloning if it receives a traditional tar file. An AUFS driver will not be able to cope with receiving a Slacker tar stream though!
To cope with large numbers of layers inside images, Slacker implemented lazy cloning for pulls:
… instead of representing every layer as an NFS file, Slacker (when possible) represents them with a piece of local metadata that records a snapshot ID.
ApplyDiffsimply sets this metadata instead of immediately cloning. If at some point Docker callsGeton that layer, Slacker will at that point perform a real clone before the mount.
To enable cache sharing on workers, Slacker modifies the loopback module to add awareness of VMstore snapshots and clones:
In particular, we use bitmaps to track differences between similar NFS files. All writes to NFS files are via the loopback module, so the loopback module can automatically update the bitmaps to record new changes. Snapshots and clones are initiated by the Slacker driver, so we extend the loopback API so that Slacker can notify the module of COW relationships between files.
Key results
Figure 19 (below) shows that Slacker makes a big difference to push and pull times. On average, the push phase is 153x faster, and the pull phase is 72x faster. The run phase itself is 17% slower (the AUFS pull phase warms the cache for the run phase).
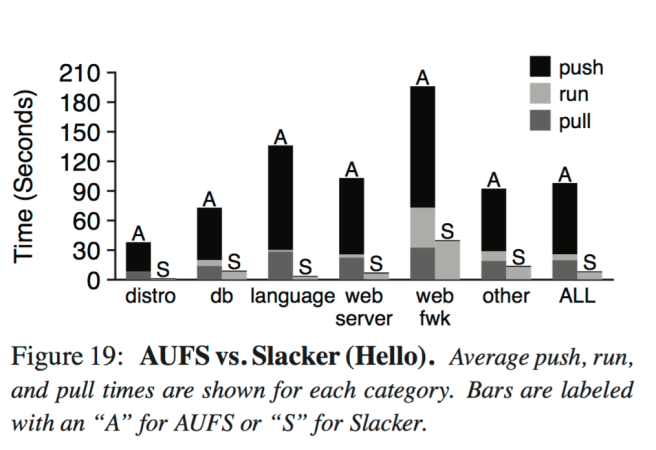
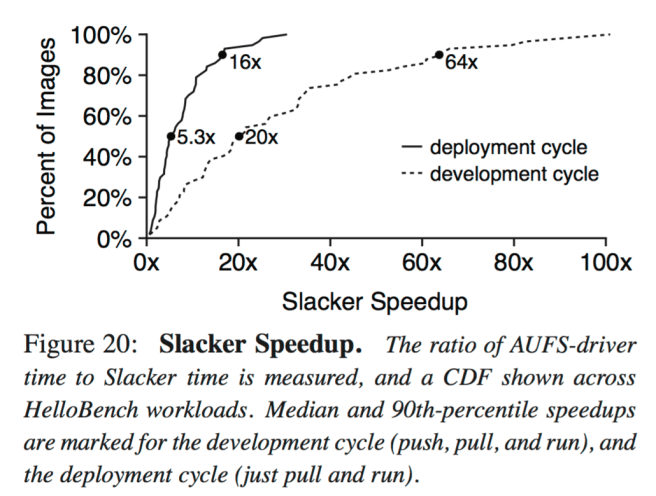
Different Docker operations are utilized in different scenarios. One use case is the development cycle: after each change to code, a developer pushes the application to a registry, pulls it to multiple worker nodes, and then runs it on the nodes. Another is the deployment cycle: an infrequently-modified application is hosted by a registry, but occasional load bursts or rebalancing require a pull and run on new workers. Figure 20 shows Slacker’s speedup relative to AUFS for these two cases. For the median workload, Slacker improves startup by 5.3× and 20× for the deployment and development cycles respectively. Speedups are highly variable: nearly all workloads see at least modest improvement, but 10% of workloads improve by at least 16× and 64× for deployment and development respectively.
The authors conclude:
Fast startup has applications for scalable web services, integration testing, and interactive development of distributed applications. Slacker fills a gap between two solutions. Containers are inherently lightweight, but current management systems such as Docker and Borg are very slow at distributing images. In contrast, virtual machines are inherently heavyweight, but multi-deployment of virtual machine images has been thoroughly studied and optimized. Slacker provides highly efficient deployment for containers, borrowing ideas from VM image-management, such as lazy propagation, as well as introducing new Docker-specific optimizations, such as lazy cloning. With these techniques, Slacker speeds up the typical deployment cycle by 5× and development cycle by 20×. HelloBench and a snapshot of the images we use for our experiments in this paper are available online: https://github.com/Tintri/hello-bench

Hi, there’s a small typo in the Quote above Fig 7 – “Deuplication is a simple alternative…”. Thanks for posting all these papers, it’s my morning train read!