Scalable and private media consumption with Popcorn – Gupta et al. 2016
What price can we put on privacy? For streaming media consumption (think Netflix) in which you have complete privacy concerning the media you are watching (i.e., not even the service provider knows – how is this even possible? We’ll get to that…), it turns out that the cost to provide such a service is about 3.87x the cost of a baseline non-privacy preserving service.
Popcorn’s overheads are high when compared to a non-private baseline: for each request, Popcorn consumes 1080x more computational resources, about 14x more I/O bandwidth, and 2x longer network transfers. However, since CPU is cheap and Popcorn is engineered to conserve the more expensive resources (I/O and network), these overheads, when translated to dollars, are manageable: Popcorn’s per-request cost, in terms of dollars, is 3.87x that of the baseline.
To paraphrase the well-known advert (at least in the UK, no idea about the rest of the world!), “privacy-preserving service, about 3.87x, preserving privacy, priceless.”
If, like me, you don’t know very much about the world of Private Information Retrieval (PIR), your first question may well be “how can it be that even the service provider doesn’t know what media you are consuming?”. This paper provides a very good background to PIR and plenty of references as a jumping off point for exploring that question. If you do know something about PIR (which you will in a moment if you keep reading :) ), your next question might be, “how on earth does Popcorn manage to make this practical?” Popcorn uses a blend of PIR techniques, and relies on sufficient client request volume to support efficient batching of requests to pull this off.
A Private Information Retrieval Primer
We have a Library, L, of n media objects. Each media object is uniquely identifiable by an integer from 1..n. A consumer can therefore select a media object just by providing the corresponding integer. We also need all of the media objects to be the same size, l, – we’ll come back to this, for now just assume we can make it so. No attacker – including the content distributor and network eavesdroppers – should be able to infer what object the consumer is accessing.
A PIR protocol allows a client to use an integer between 1 and n to retrieve any object from a library L of n l-bit objects kept by a set of k servers (k ≥ 1) without leaking to the servers any information about which object was retrieved.
PIR protocols are broken down into Query, Answer, and Decode procedures. A that client wants to retrieve object b, invokes Query(b) which returns a set of k query vectors, one for each of the k servers. Each query vector q is sent to the corresponding server, which replies with Answer(q, L). The client aggregates all of the answers and computes Decode(a1,…,ak) to recover the desired object.
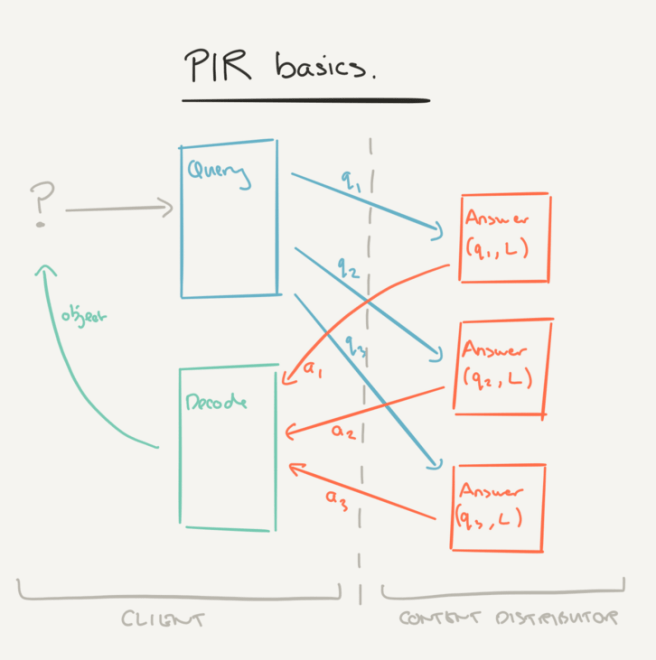
There are two families of PIR protocols discussed in the paper: Computational PIR (CPIR) protocols, and Information-theoretic PIR (ITPIR) protocols.
CPIR protocols require only a single, computationally bound server (k=1). They are commonly constructed using additively (not fully) homomorphic public key cryptosystems…Examples of cryptosystems used in CPIR are the Paillier and the lattice-based Ring-LWE.
ITPIR has a much lower computational cost than CPIR, but it requires multiple non-colluding servers, and hence multiple administrative domains. This means content creators must be happy to distributed their content beyond the original distribution channel.
Applying PIR to large-scale media consumption presents a number of challenges.
- The I/O and CPU resources required are proportional to the size of the library (not just the size of the objects in the library).
- Delivery must obey real-time constraints, including a minimal initial delay before content starts playing
- PIR assumes objects of identical size, yet object sizes vary as a function of encoding or playback time
- In ITPIR content creators must be happy to disseminate content beyond its original distribution channel, yet in CPIR computation costs are significantly higher.
- Private retrieval conflicts with billing, access control, and recommendation services.
Prior PIR works address some of these challenges:
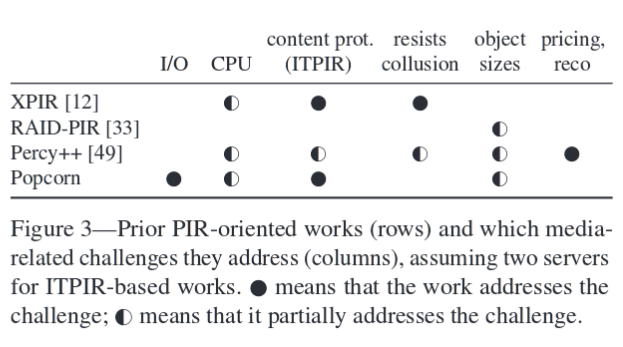
Popcorn primarily addresses the resource consumption issue.
The Design of Popcorn
Popcorn uses both CPIR and ITPIR in combination. The use of ITPIR reduces the computational overhead, the use of CPIR addresses content owner concerns about releasing their content to independent distribution channels.
The primary content distributor creates an encrypted version of the library, using per-object encryption keys. This encrypted library is given to two secondary content distributors, each in a separate administrative domain. Since the secondary content distributors do not have the object keys, the content creator is protected.
To retrieve an object, a client uses ITPIR to contact the object servers and retrieve an encrypted version of the target object. The client uses CPIR to retrieve the decryption key for the object from the primary distributor. Since keys are much smaller than the media content, the overheads of CPIR are much less in this scenario.
The distinction between key and object servers maps to today’s DRM implementations where clients contact two separate servers, one for encrypted video, and one for decryption keys.
Media objects are divided into segments containing for example a few seconds or minutes of video. Segments lengths vary (segment 2 may be longer than segment 1 for example), but they are the same across all objects. The library is divided into columns which are stacks of corresponding segments across all objects. Columns are further subdivided into 1MB wide slices, which are the work units assigned to physical machines.
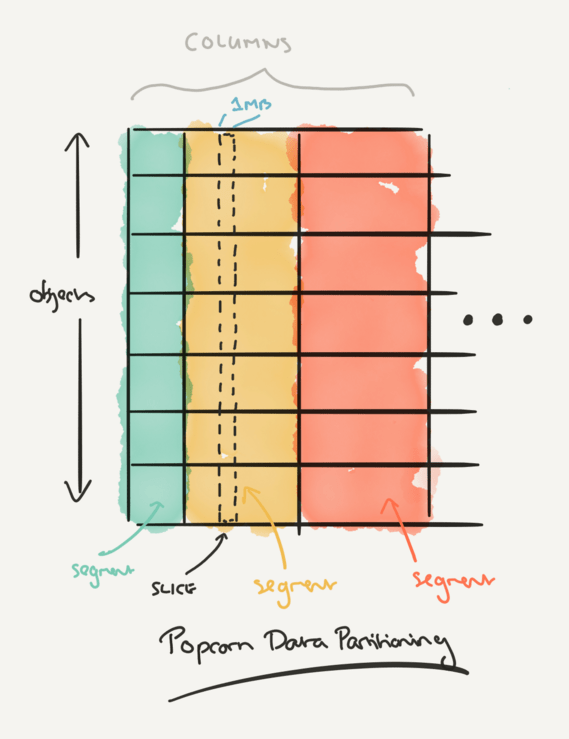
Fetching an encrypted object happens in two phases:
In the first phase, the client sends, in parallel, a query vector to all machines in both object servers. On receiving a request, a machine adds the query vector to its request queue. Each machine services its queue by looping over its slices, computing chunk-sized (1MB) ITPIR replies for every pending request, and pushing the resulting chunks to a file server (one per object server) that retains the chunks until they are requested by clients. In the second phase, the client downloads these ITPIR-encoded chunks at the appropriate playback times, and applies
Decode. This phase overlaps with the server-side generation of replies.
Popcorn uses the CKGS ITPRI scheme which is based on inexpensive XORs. Nevertheless, a query requires the machine serving a slice to read from storage and XOR, on average, n/2 chunks. “This taxes I/O bandwidth, memory bandwidth, and CPU cycles.” Popcorn mitigates this by batching, performing a single pass over a slice for multiple queries. Batching of course can introduce latency for client requests.
Since a client can begin playback only after decoding the response for the first column, Popcorn uses a ‘narrow’ first column to keep this initial delay short. Column width, however, increases quickly in Popcorn, making later columns wide. The crucial intution is that wide columns imply good batching opportunities: a batch comprises all requests that reached an ITPIR instance during its previous loop interval, and wider columns imply longer loop intervals.
To handle the fact that media objects are not all equally sized, Popcorn chooses an ‘average’ object from the Library (e.g. the object closest in size to the average) and pads smaller objects to that size. Larger objects are compressed down to the chosen size by reducing the bitrate, within the bounds of acceptability. The very longest objects are slit into several files. An analysis of the Netflix catalog showed that the smallest 8% of movies would require significant padding, 5% would require aggressive compression, and 2% would require splitting.
How well does it work?
The main evaluation results are as follows:
- Popcorn is affordable when it serves large media files to many concurrent clients. The concurrency is needed for the batching to be effective.
We find that Popcorn incurs modest costs when the library size is moderate (~8,000 media files), object sizes are large (~90 minutes), and there are many concurrent clients (≥ 10,000). Fortunately these settings are consistent with the workloads of Netflix-like systems.
- Popcorn’s per-request dollar cost is 3.87x a system without privacy for workloads with ≥ 10,000 concurrent clients
- Popcorn integrates well with existing web technology and it can play DRM-encoded media within modern web browsers.
We see three main limitations. First, because Popcorn’s overheads grow linearly with the number of objects, it has no hope of scaling to YouTube-size libraries. Second, organizations that serve objects can collude to compromise Popcorn’s privacy guarantee. Admittedly, an assumption of no collusion may be unrealistic against state-level adversaries that can compromise multiple organizations (or already have). Third, Popcorn cannot support forward seeks during playback: such user actions alter the download pattern in an content-dependent way, thus revealing information.
While Popcorn does not currently support billing, ad targeting, and recommendations, there is relevant prior work that can be incorporated into the Popcorn system.

One thought on “Scalable and private media consumption with Popcorn”
Comments are closed.