Chimera: Large-Scale Classification Using Machine Learning, Rules, and Crowdsourcing – Sun et al. 2014 (WalmartLabs)
Large-scale classification, where we need to classify hundreds of thousands or millions of items into thousands of classes, is becoming increasingly common in this age of Big Data… So far, however, very little has been published on how large-scale classification has been carried out in practice, even though there are many interesting questions about such cases.
Today’s paper is a case study on large-scale classification of products at Walmart. The requirement is to classify 10M+ products into 5000+ categories based on fairly minimal product descriptions. Oh, and new products turn up all the time, and the set of categories is continuously evolving.
Many learning solutions assume that we can take a random sample from the universe of items, manually label the sample to create training data, then train a classifier. At this scale, however, we do not even know the universe of items, as product descriptions keep “trickling in”, a few tens of thousands or hundreds of thousands at a time… concept drift becomes common (e.g., the notion “computer cables” keeps drifting because new types of computer cables keep appearing).
Walmart vendors submit product descriptions for their new products continuously. The way in which they fill-in the product detail information varies wildly from vendor to vendor, and asking them to be more thorough or detailed doesn’t really work. So the only field that classification really can rely on is ‘Title’. Creating training data manually is time-consuming – a good analyst can classify about 100 items a day. (Matches to the correct category can take some research – where do you put a ‘Dynomax Exhaust 17656 Thrush Welded Muffler’ when you have 150 automotive categories and none of them are ‘Mufflers’?).
Given the rate of 100 product items per day per analyst, it would take 200 days for a team of 5 analysts to manually classify 100,000 items. Thus, asking analysts to manually classify incoming product items is clearly not a practical solution.
To label just 200 items per product category as training data would require labeling 1M product items. Outsourcing (in-place of using in-house analysts) is prohibitively expensive – at $10/hour it would cost Walmart $770K to get 1 million items classified, “an unacceptable cost to us.” Crowdsourcing (E.g. Mechanical Turk) doesn’t work very well because the classification task is too complex compared to the preferred micro tasks on those platforms that take a few tens of seconds to answer yes or no.
If you can’t get enough training data, perhaps a rules-based approach will work instead? “But writing rules to cover all 5000+ product types is a very slow and daunting process. In fact, we did not find it to be scalable.”
Since none of the approaches (manual classification, machine learning, and rules) can solve the problem in isolation, Walmarts Chimera system uses all three in combination:
Chimera uses a combination of machine learning, hand-crafted rules, developers, analysts, and crowd workers to form a solution that continuously improves over time, and that keeps precision high while trying to improve recall.
Chimera is initialised using a basic set of training data and hand-crafted rules supplied by analysts. The learning-based classifiers are trained using this initial data, and the system then proceeds to iterate as follows:
- Given a set of incoming product items, classify them, then use crowdsourcing to continuously evaluate the results and flag cases judged incorrect by the crowd.
- The analysts examine the flagged cases, and fix them by writing new rules, relabeling certain items, and alerting the developers.
- The newly created rules and the relabeled items are incorporated into the system, and the developers may fine tune the underlying automatic algorithm.
- For those items that the system refuses to classify (due to a lack of confidence), the analysts examine them, then create hand-crafted rules as well as training data (i.e., labeled items) to target those cases. The newly created rules and training data are incorporated into the system, and it is run again over the product items.
Through this loop, the system continuously improves its performance. The big picture looks like this:
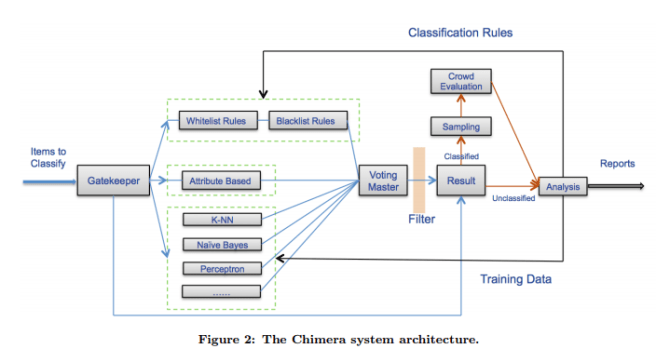
A new product item is first examined by the GateKeeper. If the GateKeeper can trivially classify it with high confidence (for example, it’s an exact match to training data) then the result is immediately sent to the results processing phase (for sampling & possible evaluation). Otherwise the item is passed to three different classification systems in parallel:
- A rules-based system that uses white-list and black-list regexs on product title text. (Yes, the thought of thousands of regexs sounds a handful, but each regex is quite simple based on the examples shown. For example: ‘wedding bands? -> rings).
- An attribute and value-based classifier that examines attributes and uses a rules-based approach to classify based on them. For example, if the product has an ISBN, classify it as a book.
- A machine learning ensemble using naive-Bayes, K-Nearest Neighbours, and Perceptron classifiers.
Given an item, all classifiers will make predictions (each prediction is a set of product types optionally with weights). The Voting Master and the Filter combine these predictions into a final prediction. The pair (product item, final predicted product type) is then added to the result set.
Why is there a need for a filter step after the voting master?
Once the voting master has produced a combined ranked list of product types, the filter applies a set of rules (created by the analysts) to exert a final control over the output types. Note that analysts can already control the rule-based classifiers. But without the filter, they do not have a way to control the output of the learning-based classifier as well as the voting master, and this can produce undesired cases. For example, learning-based classifiers may keep misclassifying “necklace pendant” as of type “necklace” (because we have many items of type “necklace” in the training data that do contain the word “necklace”). As a result, the voting master may produce “necklace” as the output type for “necklace pendant”. The analysts can easily address this case by adding a rule such as “pendant → NOT necklace” to the filter.
Items that could not be classified with sufficient confidence are passed to the in-house analysts. Items that have been classified with sufficient confidence are randomly sampled to be sent to crowdsourced workers for category verification. If the crowd indicates an item was wrongly classified it is sent to the analysts who then create rules to correctly classify it in the future.
As of March 2014, the system had been stable for about 6 months and classified about 2.5M items from marketplace vendors.
Overall we managed to classify more than 90% of them with 92% precision. Chimera has also been applied to 14M items from walmart.com. Overall it classified 93% of them with 93% precision.
The authors summarise six main lessons learned while building Chimera:
- Things break down at large scale
- Both learning and hand-crafted rules are critical
- Crowdsourcing is critical, but must be closely monitored
- Crowdsourcing must be coupled with in-house analysts and developers
- Outsourcing does not work at a very large scale
- Hybrid human-machine systems are here to stay…
While academia has only recently started exploring such systems, largely in the context of crowdsourcing, they have been used for years in industry, as evidenced by Chimera and other systems that we know. Such systems use not just crowd workers, but also analysts, and developers, and treat them as “first-class citizens”. They have been quite successful, and deserve much more attention and closer studies.

2 thoughts on “Chimera: Large-Scale Classification Using Machine Learning, Rules, and Crowdsourcing”
Comments are closed.