Blurred Persistence: Efficient Transactions in Persistent Memory – Lu, Shu, & Sun, 2015
We had software transactional memory (STM), then hardware support for transactional memory (HTM), and now with persistent memory in which the memory plays the role of stable storage, we can have persistent transactional memory. And with persistent transactional memory, there’s an issue that will surely make you smile with recognition: in-place of managing the relationship between volatile memory and disk, we now have to manage the relationship between the volatile CPU cache and memory! It’s all the same considerations (forcing, stealing etc.) but in a new context and with a few new twists. Chief among those twists is that you have a lot less control over how and when the hardware moves data from cache to memory than you do over how and when you move data from memory to disk.
In case you find all these various permutations of non-volatile memory / storage confusing (I do!), then this might help:
Emerging byte-addressable NVMs are further accelerating the architectural change
in transaction design. Transaction designs can be classified into three categories
when NVMs are used differently in a storage system:
- NVM used as secondary storage. Here you can further subdivided into a hyper-converged approaches (each box has its own PCIe attached storage), and network-attached storage devices. “When NVMs are used in secondary storage, the internal bandwidth inside a storage device (due to the internal parallelism) ismuch higher than the device bandwidth. MARS is a transaction protocol that is proposed to copy data for transactions inside devices to exploit the internal bandwidth.”
- NVM used as a persistent cache (at memory level) to secondary storage. NVM can be used to persistently keep transaction data and reduce the overhead in moving it to secondary storage.
- NVMs used for persistent storage at the memory level (I.e., as the stable storage system). Here, “the transaction mechanism needs to be designed when the data are written back from the CPU cache to the persistent main memory. Cache management in the CPU cache is quite different from that in the main memory. ”
We’re dealing with the third category in this paper.
In persistent memory, the volatility-persistence boundary (e.g., the boundary between the volatile and the persistent storagemedia) hasmoved to the interface between the volatile CPU cache and the persistent main memory… Storage consistency, which ensures that storage systems can recover from unexpected failures, needs to be provided at the memory level in persistent memory. To provide storage consistency, persistence operations, which write back data from volatile media (the CPU cache) to persistent media (the persistent main memory), need to be performed in [the] correct order. This write ordering leads to frequent I/O halts, thus significantly degrading system performance.
The storage consistency overhead is even higher with persistent memory – the CPU cache is hardware controlled and keeping track of all pages in software is cumbersome. An alternative is to always flush the whole cache using e.g. the clflush and mfence commands. In either case, since storage consistency requires frequent persistence operations, performance is significantly degraded.
One option is to improve hardware support. While researching this topic, I found myself looking at the 1200 page Intel Architecture Instruction Set Extensions Programming Reference manual. And lo and behold, chapter 10 covers “new instructions for future Intel processor generations that provide enhancements in application memory operation and the use of persistent memory.” There you’ll find this:
For performance reasons, accesses to persistent memory may be cached by the processor caches. While caches significantly improve memory access latencies and processor performance, caching requires software to ensure data from stores is indeed flushed from the volatile caches (written back to memory), as part of making it persistent. New optimized cache flush instructions that avoid the performance limitations of CLFLUSH are introduced. Section 10.4 provides the details of the CLFLUSHOPT and CLWB instructions. CLFLUSHOPT is defined to provide efficient cache flushing. The CLWB instruction (Cache Line Write Back) writes back modified data of a cacheline similar to CLFLUSHOPT, but avoids invalidating the line from the cache (and instead transitions the line to non-modified state). CLWB attempts to minimize the compulsory cache miss if the same data is accessed temporally after the line is flushed.
and:
A store to persistent memory is not persistent until the store data reaches the non-volatile memory device or an intermediate power-fail protected buffer. While cache flushing ensures the data is out of the volatile caches, in modern platform architectures, the cache flush operation completes as soon as the modified data write back is posted to the memory subsystem write buffers (and before the data may have become persistent memory). Since the memory subsystem ensures the proper memory ordering rules are met (such as subsequent read of the written data is serviced from the write buffers), this posted behavior of writes is not visible to accesses to volatile memory. However this implies that to ensure writes to persistent memory are indeed committed to persistence, software needs to flush any volatile write buffers or caches in the memory subsystem. A new persistent commit instruction (PCOMMIT) is defined to commit write data queued in the memory subsystem to persistent memory. Section 10.4 provides the details of the PCOMMIT instruction.
Blurred persistence does not presume the existence of this hardware support, and looks at what we can do in software with existing hardware. It is based on two observations:
- It’s OK to persist volatile (uncommitted) data if you can detect this is the case when recovering from a crash and it doesn’t affect the persisted data. (Hmm, that sounds awfully like stealing…).
- You don’t have to immediately write to-be-persisted data if you have persistent copies (or ways of creating them) in other areas. (And that sounds awfully like a no-force policy!).
Based on these observations, Blurred Persistence introduces two mechanisms described as Execution in Log (XIL) and Volatile Checkpoint with Bulk Persistence (VCBP). It’s possible to use these together or individually (and the evaluation section discusses conditions when you might want to use just one or the other).
First, Execution in Log (XIL) allows transactions to be executed in the log area and removes duplicated copies in the execution area. Volatile data are allowed to be persisted in the log area. To enable this, XIL reorganizes the log structure to make the uncommitted data detectable in the log. During recovery, the detected uncommitted data can be cleaned from the log while leaving only committed transactions. Second, Volatile Checkpoint with Bulk Persistence (VCBP) allows delayed persistence of committed transaction data in each transaction execution and avoids the tracking of to-be-persisted data. This is achieved by making the corresponding log data persistent and maintaining the commit order of checkpointed data across threads. It also aggressively flushes all data blocks from the CPU cache to memory using bulk persistence, with the reorganized memory areas and structures. By doing so, VCBP enables more cache evictions and less forced writebacks, thus improves cache efficiency.
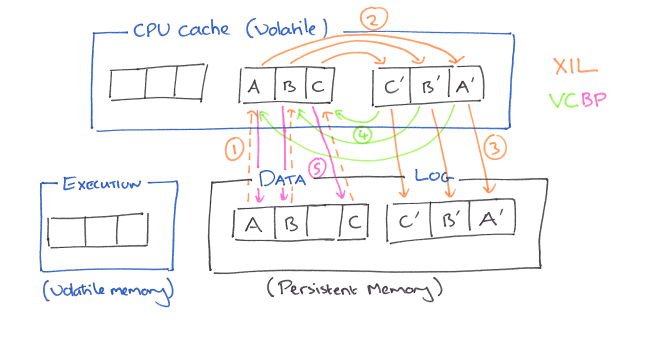
Execution in Log
‘Conventional’ approaches to transaction support in persistent memory divide the memory into distinct areas: a data area where the committed, persistent data is kept; a log area; and an execution area (this plays the role of ‘memory’ in a traditional disk-based TP architecture).
During transaction execution, data are read from the data area and copied to the execution area. When the transaction is committing the to-be-persisted data is recorded in the log area. Once the log blocks have been persisted, the committed data are checkpointed to the data area. Thus there is a lot of copying and overhead.
XIL removes the execution area in persistent memory and directly executes transactions in the log area. It allows volatile uncommitted data to be persisted before transaction commits. In conventional persistent memory, uncommitted data should be prevented from being persisted (i.e., being written back from the CPU cache to the persistent memory); Otherwise, the old-version data in the persistent main memory might be overwritten and corrupted.
XIL breaks this limitation by:
- guaranteeing that uncommitted data blocks never overwrite the persistent data version in the data area, and
- guaranteeing that uncommitted data blocks written back to the log area are detectable
Data blocks from uncommitted transactions may be written to the log area at any time by the CPU cache hardware…
To make the uncommitted data detectable in persistent main memory, XIL reorganizes the log structure: (1) Data blocks in the log area are allocated in a log-structured way. Each block has a unique address. With the determined address, an uncommitted block is written to its own location. It neither overwrites any other block nor is overwritten. (2) Uncommitted data blocks are identified using their transaction status metadata in the log, which has associated metadata to indicate the transaction status. For each transaction, there is a block to record these metadata, i.e., a commit record for a committed transaction and an abort record for an aborted transaction. During the normal execution, when a transaction is aborted, its volatile data blocks are discarded without being written back to the persistent main memory. This leads to log holes in the log area (i.e., the log blocks that have been allocated but not written to). Log holes are those blocks allocated for uncommitted transactions, but have no data written to.
During recovery XIL needs to correctly process logs with log holes. Hole-blocks are detectable using the ‘torn-bit’ technique from Mnemosyne which uses one bit in each data block to indicate the status. Uncommitted data blocks that have already been written are detectable using a back-pointer technique reminiscent of compensation log-records in ARIES, in which each abort record contains a back-pointer to the commit record of the last committed transaction. To find valid log blocks that follow a hole, XIL guarantees that one abort record is written for at least every 64 blocks of an aborted transaction. During recovery, if an unwritten block is encountered the recovery manager scans ahead by 64 blocks, and if no abort record is encountered then it knows the end of the log must have been reached.
Volatile Checkpoint with Bulk Persistence
The VCBP technique consists of two steps: volatile checkpoint and bulk persistence. The volatile checkpoint step checkpoints committed data blocks to the data area without forcing them to be written back to persistent memory. It is performed for each transaction execution. The bulk persistence aggressively delays the persistence of check-pointed data until the persistent log area runs out of space. At this time, it forces all data blocks in the CPU cache to be written back to the persistent main memory. Persistence of checkpointed data is removed during the execution of each transaction.
Since this write-up is already getting quite long, I’ll refer you to the paper for full details on this.
Comparison to traditional No-Force and Steal policies
There’s an interesting passage in the paper on the relationship of Buffered Persistence to the No-Force/Steal policies in ARIES:
The similarity between Blurred Persistence and the Steal/No-Force policies is that both improve the buffer management efficiency for transactions. However, Blurred Persistence improves buffer management of the CPU cache in persistent memory,while the Steal/No-Force policies improve buffer management of main memory in traditional database management systems. Due to the architectural difference of the two storage systems, they face different problems, thus are designed differently.
Because the details of the situations are different, the view of the authors is that XIL and VCBP are not Steal and No-Force policies:
XIL allows uncommitted data to be persisted to the log area before the transaction is committed, by redesigning the log organization. The Steal policy also allows uncommitted data to be persisted before the transaction is committed, but instead of to the log area, these uncommitted data are allowed to be persisted to the data area by introducing the undo log… VCBP in Blurred Persistence allows committed data to be lazily persisted. The No-Force policy has the same intention. But the No-Force policy can easily track the to-be-persisted committed data in the volatile main memory, while it is costly for programs to do such work in persistent memory due to the hardware-controlled CPU cache.
Personally I tend to think of Steal and No-Force as the abstract idea, and would say that all we have in ARIES and Blurred Persistence are different embodiments of the same concepts. (I.e., XIL is an implementation of a Steal policy, and VCBP is an implementation of a No-Force policy).
How well does it work?
A 56.3% to 143.7% improvement in system performance across a variety of workloads (random swaps of array entries; hash tables; red-black trees; B+ trees; key-value operations in Tokyo-Cabinet).

4 thoughts on “Blurred Persistence: Efficient Transactions in Persistent Memory”
Comments are closed.