Twitter Heron: Stream Processing at Scale – Kulkarni et al. 2015
It’s hard to imagine something more damaging to Apache Storm than this. Having read it through, I’m left with the impression that the paper might as well have been titled “Why Storm Sucks”, which coming from Twitter themselves is quite a statement. There’s a good write-up of the history of Apache Storm on Nathan Marz’s blog – Nathan left Twitter in 2013. This paper marks the beginning of a new chapter in that history.
Twitter don’t use Storm anymore.
At Twitter, Storm has been decommissioned and Heron is now the de-facto streaming system. It has been in production for several months and runs hundreds of development and production topologies in multiple data centers. These topologies process several tens of terabytes of data, generating billions of output tuples…. results from an empirical evaluation of Heron demonstrate large reductions in CPU resources when using Heron, while delivering 6-14X improvements in throughput, and 5-10X reductions in tuple latencies.
Heron still supports the Storm API, but after evaluating their options Twitter decided that Storm was too badly broken for their needs to be fixed within the existing codebase.
Since the issues discussed … are fundamental to Storm, fixing them in Storm would have required extensive rewrite of the core components. […] Thus, we concluded that our best option was to rewrite the system from ground-up, reusing and building on some of the existing components within Twitter.
Guess you’d better take that Twitter logo off of the Apache Storm home page then Apache :(.
So what was up with Storm then?
…many limitations of Storm have become apparent. We need a system that scales better, has better debug-ability, has better performance, and is easier to manage – all while working in a shared cluster infrastructure.
Let us count the ways…
- Multiple levels of scheduling and their complex interaction leads to uncertainty about when tasks are being scheduled.
- Each worker runs a mix of tasks, making it difficult to reason about the behaviour and performance of a particular task, since it is not possible to isolate its resource usage.
- Logs from multiple tasks are written into a single file making it hard to identify errors and exceptions associated with a particular task, and causes tasks that log verbosely to swamp the logs of other tasks.
- An unhandled exception in a single task takes down the whole worker process killing other (perfectly fine) tasks.
- Storm assumes that every worker is homogeneous, which results in inefficient utilization of allocated resources, and often results in over-provisioning.
- Because of the large amount of memory allocated to workers, use of common profiling tools becomes very cumbersome. Dumps take so long that the heartbeats are missed and the supervisor kills the process (preventing the dump from completing).
- Re-architecting Storm to run one task per-worker would led to big inefficiencies in resource usage and limit the degree of parallelism achieved.
- Each tuple has to pass through four (count ’em) threads in the worker process from the point of entry to the point of exit. This design leads to significant overhead and contention issues.
- Nimbus is functionally overloaded and becomes an operational bottleneck.
- Storm workers belonging to different topologies but running on the same machine can interfere with each other, which leads to untraceable performance issues. Thus Twitter had to run production Storm topologies in isolation on dedicated machines. Which of course leads to wasted resources.
- Nimbus is a single point of failure. When it fails, you can’t submit any new topologies or kill existing ones. Nor can any topology that undergoes failures be detected and recovered.
- There is no backpressure mechanism. This can result in unbounded tuple drops with little visibility into the situation when acknowledgements are disabled. Work done by upstream components can be lost, and in extreme scenarios the topology can fail to make any progress while consuming all resources.
- A tuple failure anywhere in the tuple tree leads to failure of the whole tuple tree.
- Topologies using a large amount of RAM for a worker encounter gc cycles greater than a minute.
- There can be a lot of contention at the transfer queues, especially when a worker runs several executors.
- To mitigate some of these performance risks, Twitter often had to over provision the allocated resources. And they really do mean over provision – one of their topologies used 600 cores at an average 20-30% utilization. From the analysis, one would have expected the topology to require only 150 cores.
For our needs at Twitter, we needed a stream processing platform that was open-source, high-performance, scalable, and was compatible with the current Storm API. We also needed the platform to work on a shared infrastructure.
Enter the Heron
Heron is a container-based implementation. Heron topologies are deployed to an Aurora scheduler (which runs on top of Mesos), but they could equally be deployed on YARN or Amazon ECS (Elastic Container Service).
This design is a departure from Storm, where Nimbus (which is an integral component of Storm) was used for scheduling. Since Twitter’s homegrown Aurora scheduler and other open-source schedulers (e.g. YARN) have become sophisticated, we made the conscious choice of working with these schedulers rather than implementing another one.
Of note is that Heron runs multiple processes per container.
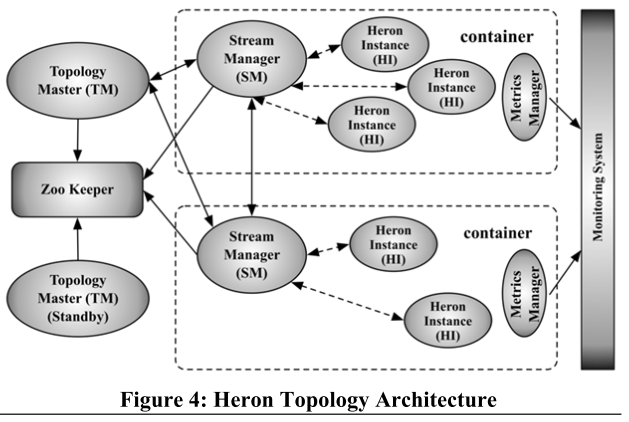
The first container runs a process called the Topology Master. The remaining containers each run a Stream Manager, a Metrics Manager, and a number of processes called Heron Instances (which are spouts/bolts that run user logic code). Multiple containers can be launched on a single physical node. These containers are allocated and scheduled by Aurora based on the resource availability across the nodes in the cluster. (At Twitter, Aurora maps these containers to Linux cgroups.) A standby Topology Master can be run for availability. The metadata for the topology (which includes information about the user who launched the job, the time of launch, and the execution details) are kept in Zookeeper.
Stream Managers are responsible for routing tuples. All the Stream Managers in a topology connect to each other to form an O(k2) connection network (with k Stream Managers). Each Heron Instance connects to its local Stream Manager. With many more Heron Instances (n), than Stream Managers (k), the O(n2) logical connections are multiplexed over the O(k2) physical ones.
Heron uses spout backpressure, in which Stream Managers clamp down on local spouts to reduce the new data that is injected into the topology.
Backpressure is triggered when the buffer size reaches the high water mark, and remains in effect until the buffer size goes below the low water mark. The rationale for this design is to prevent a topology from rapidly oscillating between going into and coming out of the backpressure mitigation mode.
Heron Instances do the main work for a bolt or spout. Each is a JVM process and runs only a single task. Heron Instances have two threads, a gateway thread and a task execution thread.
The Gateway thread is responsible for controlling all the communication and data movement in and out from the HI. It maintains TCP connections to the local SM and the metrics manager. It is also responsible for receiving incoming tuples from the local SM. These tuples are sent to the Task Execution thread for processing.
How is Heron better than Storm? Let us count the ways…
- The provisioning of resources is abstracted from the duties of the cluster manager so that Heron can play nice with the rest of the shared infrastructure.
- Each Heron Instance executes only a single task so is easy to debug.
- The design makes transparent which component of the topology is failing or slowing down as the metrics collection is granular and can easily map an issue to a specific process in the system.
- Heron allows a topology writer to specify exactly the resources for each component, avoiding over-provisioning.
- Having a Topology Manager per topology enables them to be managed independently and failure of one topology does not affect the others.
- The backpressure mechanism gives a consistent rate of delivering results and a way to reason about the system. It is also a key mechanism that supports migration of topologies from one set of containers to another.
- It does not have any single point of failure.
In the evaluation in section 7 of the paper, Heron beats Storm in every single metric.

I don’t think Storm used for evaluation is up to date since zmq is mentioned in the paper but Storm has moved to Netty for quite a while. Also, it’s hard to believe the latency of Storm is as high as 1 second for small number of tasks.
I suspect the Storm evaluation dates to the point in time that Twitter decided to start building Heron….
A lot of the improvements mentioned in the paper (and more) are already in the works for Apache Storm, many even before the paper was published.
https://storm.apache.org/2015/06/15/storm0100-beta-released.html
And yes, that was an old, pre-Apache version they tested against. A lot has since changed and continues to change.
Would you know what language Heron is implemented in? Also, I wonder to what degree Twitter dumping Storm will hurt Clojure – i.e. how much of the poor performance will be attributed to Storm being primarily written in that language.
I’ve heard from some sources that its written in C++
After Storm, next up is – the Lambda Architecture ?
Lots of articles on the Lambda Architecture, but is there a good *paper* that covers it? Certainly good subject matter for TMP if so…
I believe Heron is written in C++
I believe Heron is written in C++.