Pregelix: Big(ger) Graph Anayltics on a Dataflow Engine – Bu et al. 2015
FlashGraph shows us that it’s possible to efficiently process graphs that aren’t solely in-memory, and GraphX showed us that we can map graph abstractions on top of a dataflow engine. Put the two ideas together, and you get something that looks like Pregelix…
The database community has spent nearly three decades building efficient shared-nothing parallel query execution engines that support out-of-core data processing operators (such as join and group-by), and query optimizers that choose an “optimal” execution plan among different alternatives. In addition, deductive database systems—based on Datalog — were proposed to efficiently process recursive queries, which can be used to solve graph problems such as transitive closure.
The semi-naive evaluation strategy can be be used to implement a scalable, fault-tolerant Pregel runtime.
I’m reminded of Hellerstein’s 2010 paper on ‘The Declarative Imperative in which he says:
…a large class of recursive programs – all of basic Datalog – can be parallelized without any need for coordination. As a side note, this insight appears to have eluded the MapReduce community, where join is necessarily a blocking operator.
and
“Data folk” seem to have one of the best sources of light: we have years of success parallelizing SQL, we have the common culture of MapReduce as a bridge to colleagues, and we have the well-tended garden of declarative logic languages to transplant into practice.
Let’s do some transplanting… ;)
Pregelix takes a set-oriented iterative dataflow approach to implementing the Pregel programming model.
…from a runtime perspective, Pregelix models Pregel’s semantics as a logical query plan and implements those semantics as an iterative dataflow of relational operators that treat message exchange as a join followed by a group-by operation that embeds functions that capture the user’s Pregel program. By taking this approach, for the same logical plan, Pregelix is able to offer a set of alternative physical evaluation strategies that can fit various workloads and can be executed by Hyracks, a general-purpose shared-nothing dataflow engine.
And of course, the storage management and query evaluation techniques Pregelix builds upon support out-of-core workloads. Although the current implementation builds on Hyracks, the authors believe the same approach could be used on top of other parallel data systems (the GraphX authors make a similar claim):
The Pregel logical plan could be implemented on any parallel dataflow engine, including Stratosphere, Spark or Hyracks. … This sort of architecture and methodology could be adopted by parallel data warehouse vendors (such as Teradata, Pivotal, or Vertica) to build Big Graph processing infrastructures on top of their existing query execution engines.
Pregelix is ‘just 8,514’ lines of code (GraphX is 2,500). The Giraph-core module in comparison is 32,917. Building on top of an existing dataflow engine is not just about reduced lines of code though. The GraphX paper makes the point that this also allows other processing on the same data (as compared to a specialised graph engine), and Pregelix derives two further benefits:
- Out-of-core support
All the data processing operators as well as access methods we use have out-of-core support, which allows the physical query plans on top to be able to run disk-based workloads as well as multi-user workloads while retaining good in-memory processing performance.
- Physical Flexibility
The current physical choices spanning vertex storage (two options), message delivery (two alternatives), and message combination (four strategies) allow Pregelix to have sixteen (2 × 2 × 4) tailored executions for different kinds of datasets, graph algorithms, and clusters.
The Logical Query Plan
GraphX and TAO both map vertices to one collection, and edges to another. Pregelix is a little different. There are three relations:
- Vertex (vid, halt, value, edges)
- Msg (vid, payload)
- GS – Global State (halt, aggregate, superstep)
The input data is modeled as an instance of the Vertex relation; each row identifies a single vertex with its halt, value, and edge states. All vertices with a halt = false state are active in the current superstep. The value and edges attributes represent the vertex state and neighbor list, which can each be of a user-defined type.
Keeping all of the edges as an attribute of a vertex seems like it won’t work as well with power-law graphs (vs. a separate edge relation) – I couldn’t see any discussion of this issue in the paper though.
The messages exchanged between vertices in a superstep are modeled by an instance of the Msg relation, which associates a destination vertex identifier with a message payload.
Within a superstep, message passing is implemented as a full-outer-join.
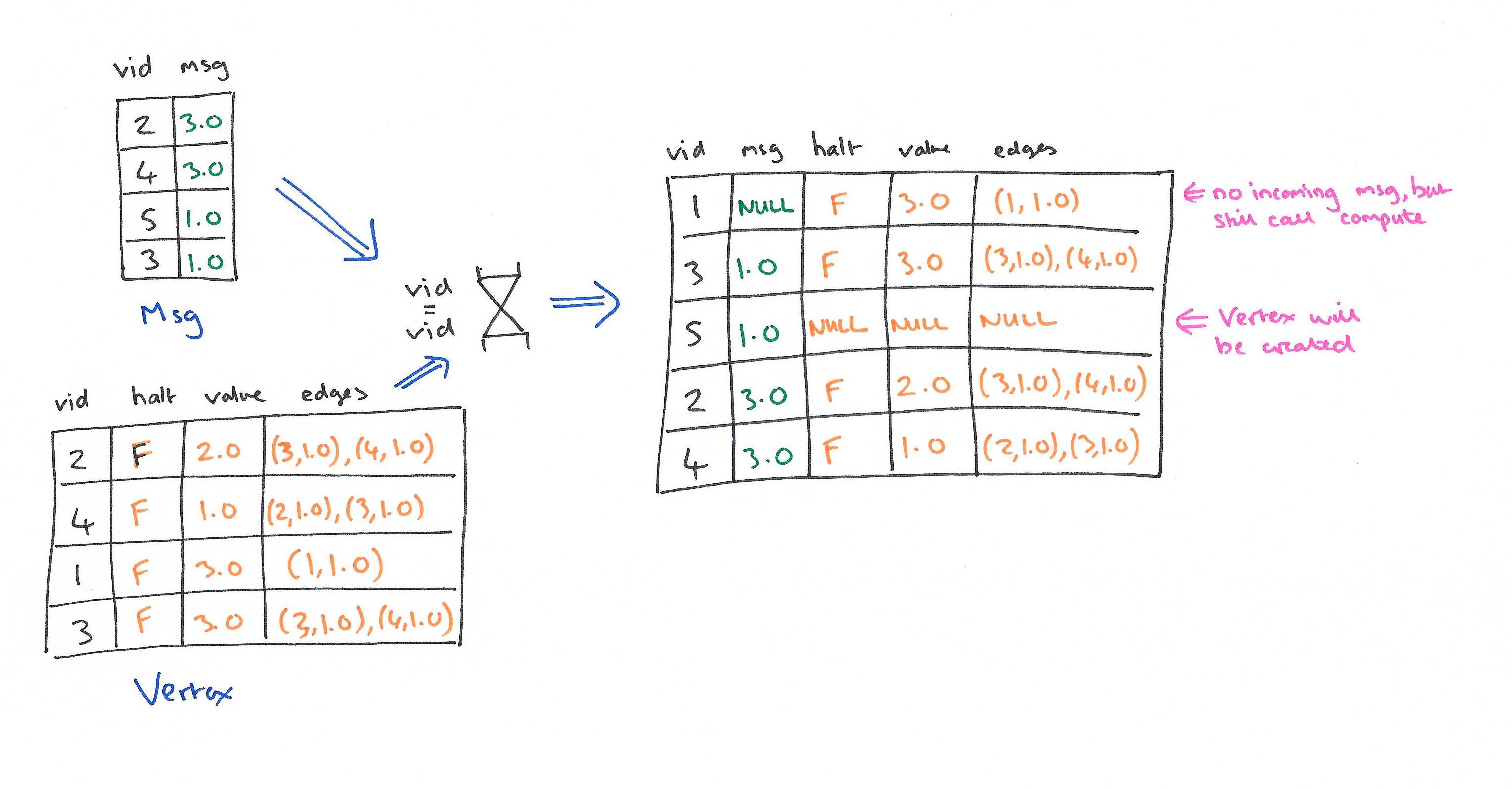
- The inner case matches incoming messages with existing destination vertices
- The left-outer case captures messages sent to vertices that may not exist (vertex will be created)
- The right-outer case captures vertices that have no messages, but ‘compute’ will still need to be called if the vertex is active
The user provides compute, combine, aggregate, and resolve functions. In each superstep, each vertex is processed through a call to compute. Compute returns a tuple that includes any updates to the vertex tuple itself, a list of messages to be delivered in the next superstep, a global halt state contribution, a global aggregate state contribution, and any graph mutations (tuples to insert/delete in the Vertex relation).
Output messages are grouped by the destination vertex id and aggregated by the combine UDF. The global aggregate state contributions of all vertices are passed to the aggregate function, which produces the global aggregate state value for the subsequent superstep. Finally, the resolve UDF accepts all graph mutations—expressed as insertion/deletion tuples against the Vertex relation—as input, and it resolves any conflicts before they are applied to the Vertex relation.
Implementation
Given a graph analytical job, Pregelix first loads the input graph dataset (the initial Vertex relation) from a distributed file system, i.e., HDFS, into a Hyracks cluster, partitioning it by vid using a user-defined partitioning function across the worker machines. After the eventual completion of the overall Pregel computation, the partitioned Vertex relation is scanned and dumped back to HDFS… Pregelix leverages both B-tree and LSM B-tree index structures from the Hyracks storage library to store partitions of Vertex on worker machines.
For message combination, Pregelix uses three group-by operator implementations from Hyracks: sort-based, HashSort, and a preclustered group-by. This are combined in four different parallel group-by strategies:
The lower two strategies use an m-to-n partitioning merging connector and only need a simple one-pass pre-clustered group-by at the receiver-side; however, in this case, receiver-side merging needs to coordinate the input streams, which takes more time as the cluster size grows. The upper two strategies use an m-to-n partitioning connector, which does not require such coordination; however, these strategies do not deliver sorted data streams to the receiver-side group-bys, so re-grouping is needed at the receiver-side. A fully pipelined policy is used for the m-to- n partitioning connector in the upper two strategies, while in the lower two strategies, a sender-side materializing pipelined policy is used by the m-to-n partitioning merging connector to avoid possible deadlock scenarios mentioned in the query scheduling literature. The choice of which group-by strategy to use depends on the dataset, graph algorithm, and cluster.
Index-based joins are used to join messages and vertices. Pregelix offers two physical choices: an index full outer join and an index left outer join. The former is suitable for algorithms where most vertices are active across supersteps (e.g. PageRank), the latter fits cases where messages are sparse and only a few vertices are live in every superstep (e.g. single-source shortest path).
The plan generator generates physical query plans for data loading, result writing, each single Pregel superstep, checkpointing, and recovery. The generated plan includes a physical operator DAG and a set of location constraints for each operator.
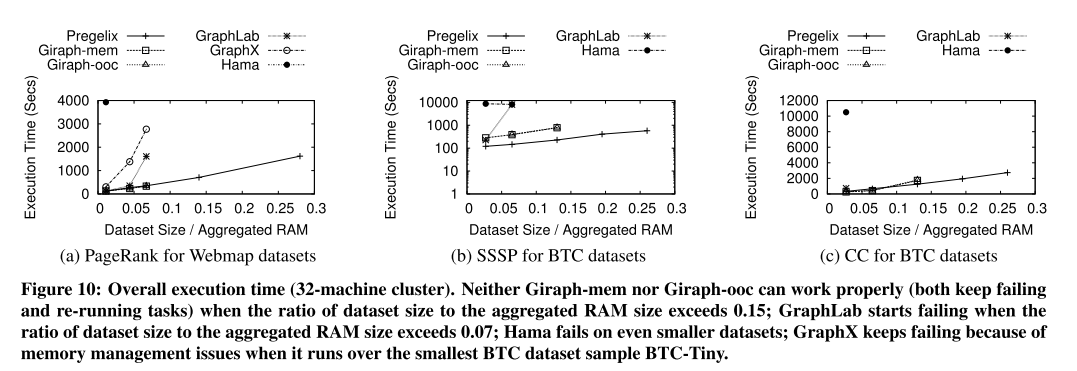
Evaluation
Experiments were run on a 32-node cluster comparing against Giraph, Hama, GraphLab, and GraphX. The benefits of the planner show most strongly with the single-source shortest path comparison where the left outer join plan enables Pregelix to be up to 15x faster than Giraph, and 35x faster than GraphLab.
For the execution time, throughput, and scalability assessments, a common theme is that the other systems start failing to run as the graph size increases, limiting the comparisons that can be performed. Giraph does have out-of-core support, but it was too immature at the time this study was done to be able to handle the workloads.