Cross-layer scheduling in cloud systems – Alkaff et al. 2015
This paper was presented last month at the 2015 International Conference on Cloud Engineering, and explores what happens when you coordinate application scheduling with network route allocation via SDN (hence: cross-layer scheduling). With clusters of 30 nodes, the authors demonstrate results that can improve the throughput of Hadoop and Storm by 26-34%. The larger your cluster, the greater the benefits. That’s a big enough boost to make me sit up and take notice…
Real-time data analytics is a quickly-growing segment of industry. This includes, for instance, processing data from advertisement pipelines at Yahoo!, Twitter’s real-time search, Facebook’s trends, real-time traffic information, etc. In all these applications, it is critical to optimize throughput as this metric is correlated with revenues (e.g., in ad pipelines), with user satisfaction and retention (e.g., for real-time searches), and with safety (e.g., for traffic).
(Being picky, at least for user satisfaction and retention, the key metric as I understand it is actually latency, not throughput – see e.g. Photon. But for sure there should be a correlation between throughput and cost-to-serve/process a given volume of information via better utilisation of your available resources).
Application schedulers today may take into account data placement, or the need for network connectivity, but usually do not coordinate with the network layer underneath. With software-defined networking we should be able not only to add network-awareness to placing decisions, but also to consider how the network itself can be optimized to support application traffic patterns that result from placement decisions. And of course we’d like to do this across a range of cloud engines and underlying networks. Computations are modelled as dataflow graphs (e.g. Storm topologies, or MapReduce jobs), and the network abstraction is provided by SDN.
The goal of our cross-layer approach is a placement of tasks and a selection of routes that together achieves high throughput for the application. Our approach involves the application-level scheduler using available end-to-end bandwidth information to schedule tasks at servers. The application scheduler calls the SDN controller which finds the best routes for those end-to-end paths. This is done iteratively. While making their decisions, each of the application scheduler and the SDN scheduler need to deal with a very large state space. There are combinatorially many ways of assigning tasks to servers, as well as routes to each end-to-end flow.
The study uses two routing topologies that lie at either end of the route diversity spectrum – Fat-Tree and Jellyfish network topologies – on the basis that any other network will like somewhere between these two.
Simulated Annealing (SA) is used to deal with the state space explosion:
Inspired by metallurgy, this approach probabilistically explores the state space and converges to an optimum that is close to the global optimum. It avoids getting stuck in local optima by utilizing a small probability of jumping away from it – for convergence, this probability decreases over time. We realize the simulated annealing approach in both the application level and in the SDN level.
Hadoop’s YARN handles cluster scheduling with a Resource Manager (RM), and per-job requirements with an Application Master (AM). The authors modified the Resource Manager to contact the SDN and obtain information about the network topology at start time (as well as when the system changes).
When a new job is submitted, the RM receives from the AM the number of map tasks and reduce tasks in that job. With this information, our cross-layer scheduling framework places these tasks by using our SA Algorithm. In MapReduce/Hadoop, the predominant network traffic is the “shuffle” traffic, which carries data from the map tasks to the appropriate reduce tasks. HDFS nodes also become a server node in our approach, which is then considered as a parameter during our SA algorithm
Once task placement has been done using the SA algorithm, the RM asks the SDN to allocate the paths for each pair of communicating tasks. The integration with Storm is similar, with the integration being made with Storm’s Nimbus daemon.
The Simulated Annealing based algorithm
When the framework starts, it pre-computes a topology map. For each pair of hosts, the k shortest paths between that pair are calculated using a modified version of the Floyd-Warshall Algorithm. Each path is stored along with the available bandwidth on each of its links, the bandwidth information in periodically updated by the SDN layer. With 1000 servers, creating the topology map takes around 3 minutes, and the result is small enough to easily store in memory.
The SA framework needs to explore the combined space of possible worker placements and possible paths.
Simulated Annealing (SA) is an iterative approach to reach an optimum in a state space. Given the current state S, the core SA heuristic considers some of its neighboring states S’, and probabilistically decides between either: i) moving the system to a neighbor state S’, or ii) staying in state S. This is executed iteratively until a convergence criterion is met.
When considering worker placement, a ‘neighbour state’ is a state that differs in the placement of exactly one task. When considering network configuration, a neighbour state is a state that differs in exactly one path.
When a user submits a Hadoop job or Storm application topology an application level scheduler first consults the topology map to determine the servers on which placement will yield the best throughput:
The primary SA works at the application level, and drives the network-level SA. This means that every iteration of the SA at the application level calls the routing-level SA as a black box, which in turn runs SA on the network paths for the end hosts in the current state, converges to a good set of paths, and then returns. When the application-level SA converges, we have a new state and the new job can be scheduled accordingly.
When selecting a task placement to de-allocate the algorithm prefers to select a node that is close either to a source or to a sink on the heuristic that this node’s placement is more likely to affect the overall throughput. The new server to place the task on is chosen at random. When selecting a path to de-allocate, the algorithm prefers to select the path that has the highest number of hops, and in the event of a tie, the lowest bandwidth. When allocating a new path, preference is given to paths that have the lowest number of hops, and in the event of a tie, the highest available bandwidth.
Once the best task placement, and the network paths that are the best match for the end-to-end flows in that placement, have been determined the SDN controller is asked to set-up the requested paths.
Upon a failure or change in the network, the SA algorithm can be re-run quickly. The SDN controller monitors the link status in the background. Upon an update to any link’s bandwidth, or addition or removal of links, the SDN controller calls the application scheduler, which then updates its Topology Map. Thereafter, we run the SA algorithm, but only at the routing level, and only for flows that use the updated link. This reduces the explored state space. Upon a server failure, the application-level SA scheduler runs only for the affected tasks (and it calls the routing-level SA)
Evaluation Results
The two key questions are: how long does it take to schedule a job/topology, and by how much does the approach improve throughput?
Scheduling times varies with topology (JellyFish takes longer than Fat-Tree), but in all cases with a 1000-node cluster it is still sub-second, and takes approximately half-a-second for a 1000 node Hadoop cluster with Fat-Tree.
In return, cross-layer scheduling improved job completion times in Hadoop by 34% (38%) at the 50th (75th) percentile, and by 34% (41%) at the 50th (75th) percentile for Storm.
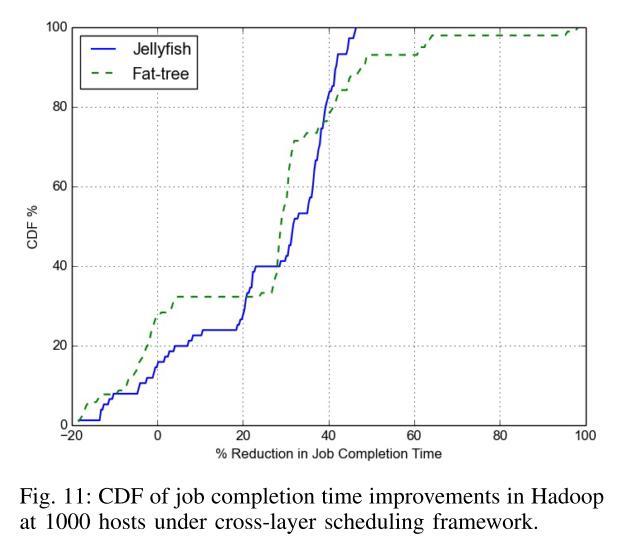
The throughput improvements are higher in network topologies with more route diversity, and our cross-layer scheduling approach allows improvements to be maintained in the case of link failure.

Interesting finding, given that https://blog.acolyer.org/2015/04/20/making-sense-of-performance-in-data-analytics-frameworks/ found single digit percentage improvement from eliminating network latency altogether.