MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing Fan et al. NSDI 2013
At the core of this paper is an improved hashing algorithm called optimistic cuckoo hashing, and a CLOCK-based eviction algorithm that works in tandem with it. They are evaluated in the context of Memcached, where combined they give up to a 30% memory usage reduction and up to a 3x improvement in queries per second as compared to the default Memcached implementation on read-heavy workloads with small objects (as is typified by Facebook workloads). There’s an excellent evaluation section at the end of the paper that breaks down the contributions to those gains, which look something like this:
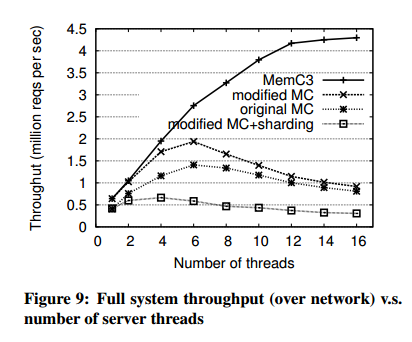
But in this write-up I just want to enjoy the algorithm and refer you to the full paper for further details on Memcached integration and the evaluation.
Cuckoo hashing
Let’s start with regular cuckoo hashing. In the most basic hash table you hash a key which tells you the bucket into which you can insert (or find) the associated value. Cuckoo hashing uses two hash functions, giving two possible buckets in which to insert or find the associated value.
Consider the following table in which each row represents a bucket, and each bucket has four slots available. A slot holds a pointer to a key-value pair structure.
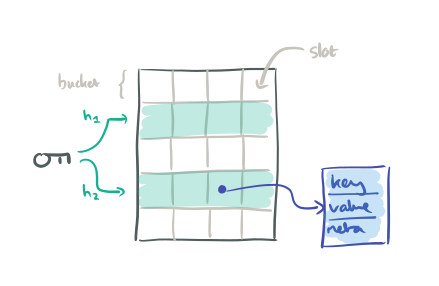
Given a key to lookup, we pass it through both hash functions, ending up with two buckets. We thus have up to 2×4 = 8 slots to examine to find one referencing the key in question.
It’s the behaviour on insert that gives cuckoo hashing its name. Hash the key using both hashes as normal to find the two buckets. If either of those buckets has an empty slot, use that to store the new key-value pair (ptr). If all the slots are full however, it’s time to evict a key from its nest. Choose a random key y from one of the buckets and evict it, creating space to add the new entry. Now hash y to find its second bucket, and try to insert y there. If that bucket is also full, evict a key from that bucket to make space, and continue the process until an empty slot is found (or you reach some maximum number of displacements – e.g. 500)
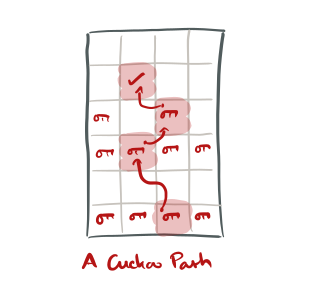
If no vacant slot can be found , the hash table is scheduled for expansion (memory permitting).
Though it may execute a sequence of displacements, the expected insertion time of cuckoo hashing is O(1).
Introducing tags to improve lookups
As will be obvious from the above, we’re doing a lot of key lookups and comparisons, which isn’t great for cache locality. The first change in optimised cuckoo hashing is to introduce tags. A tag is a 1-byte hash of the key value that is stored in the hash table slot alongside the key pointer. It can be used to give a very quick (1/256) indication of whether a key could possibly be a match or not without having to fetch it.
It is possible to have false retrievals due to two different keys having the same tag, so the fetched key is further verified to ensure it is the correct one. With a 1-byte tag by hashing, the change of tag-collision is only 1/28 = 0.39%. After checking all 8 candidate slots, a negative lookup makes 8×0.39% = 0.03 pointer deferences on average. Because each bucket fits in a CPU cacheline (usually 64-byte), on average each lookup makes only 2 parallel cacheline-sized reads for checking the two buckets plus either 0.03 pointer dereferences if the lookup misses, or 1.03 if it hits.
Using tags to improve inserts
Instead of using two independent hashes to determine the two buckets for a key, we can exploit the tag hash to determine the second bucket.
Let bucket1 = hash(x). Now compute tag(x) and the let bucket2 = bucket1 ⊕ tag(x).
This formulation has the important property that we can also recover bucket1 if we know bucket2 and tag(x). Whether a key to be displaced is in bucket1 or bucket2 we can therefore always recover the alternate bucket without ever needing to lookup the full key.
Supporting concurrent access
Our hashing scheme is, to our knowledge, the first approach to support concurrent access (multi-reader, single writer) while still maintaining the high space efficiency of cuckoo hashing (e.g. > 90% occupancy).
Making the algorithm concurrent requires solving two challenges:
- avoiding deadlocks while acquiring locks on all of the buckets, while not knowing in advance which buckets you are going to touch, and
- avoiding false cache misses when a key is evicted from one bucket but not yet reinserted in a new one
Although strictly the authors don’t really solve the first problem, they just punt on it by only allowing a single writer. In read dominated workloads, that’s a reasonable trade-off. Cache misses are avoided by first discovering a valid cuckoo path, but not yet moving any keys, and then working backwards from the empty slot up to the desired original insert. Coupled with the single writer restriction this means that each individual swap is guaranteed not to cause any further eviction cascades and can be made atomic without needing to lock the whole chain.
The most straightforward locking scheme would be to lock the two buckets involved in a swap (being careful about lock ordering) and unlock them afterwards. This requires two locks per swap.
Optimizing for the common case, our approach takes advantage of having a single writer to synchronize insert and lookups with low overhead. Instead of locking on buckets, it assigns a version counter for each key, updates its version when displacing this key on insert, and looks for a version change during lookup to detect any concurrent displacement.
But where do you keep the counters?? Adding them to each key-value object could consume a lot of storage assuming potential hundreds of millions of keys. It also opens up a race condition because the key-value objects are stored outside of the hash data structure itself and thus not protected by any locks.
The solution is to use a fixed-size array of counters – much smaller than the number of keys. 8192 counters fit in 32BK (in cache), and each counter is shared among multiple keys using our old friend hashing again. This compromise of using shared counters still allows a good degree of concurrent access while keeping the chances of a ‘false retry’ (version counter incremented for some other key that has a hash collision in the counter table) down to roughly 0.01%.
The counters are integrated as follows:
- Before a displacing a key on insert, the the insert process increases the counter by one to indicate an ongoing update for the key. After the key is moved, the counter is incremented by one again. Counters start at zero, so odd numbered counters represent locked keys, and even numbered counters unlocked keys.
- A lookup process that sees an odd numbered counter waits and retries. If it sees an even numbered counter it snapshots the value, reads both buckets, and then snapshots the counter value again. If the counter value has changed it must retry the operation.
The final twist in optimised cuckoo hashing is to explore multiple possible insert paths in parallel, increasing the chances of quickly finding one that terminates in an empty slot. In the evaluation, exploring two paths in parallel seemed to be the optimum setting.
CLOCK-based eviction
So far we’ve talked about inserts and lookups. And although the optimised cuckoo hashing scheme is very space efficient, at some point we expect our cache to become full (or near full) and then we need to start worrying about evictions.
In stock Memcached an LRU eviction policy is used, but it requires 18 bytes (two pointers and a 2-byte reference counter) to ensure keys can be evicted safely in strict LRU order. It also incurs significant synchronization overhead.
In contrast, MemC3 uses 1 bit per key and allows concurrent operations. It achieves this by trading the strict LRU algorithm for an approximate one based on the CLOCK algorithm.
As our target workloads are dominated by small objects, the space saved by trading perfect for approximate LRU allows the cache to store significantly more entries, which in turn improves the hit ratio. As we will show in section 5, our cache management achieves 3x to 10x the query throughput of the default cache in Memcached, while also improving the hit ratio.
Imagine a circular buffer of bits, and a virtual clock hand pointing to an entry in the buffer.
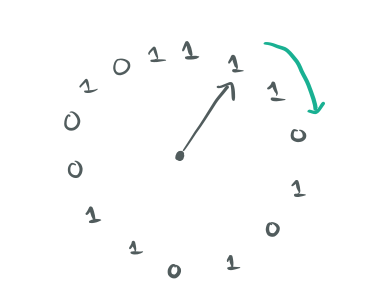
Each bit represents the recency of a different key-value object. ‘1’ if it’s been recently used, and ‘0’ otherwise. The update operation on a key simply sets the corresponding recency bit to 1. On eviction, the bit pointed to by the clock hand is checked. If it’s zero, the corresponding key is evicted. If it is one, the bit is set to zero and the clock hand is advanced to point to the next bit. This process repeats until a zero bit is found .
The eviction process is integrated with the optimistic locking scheme as follows:
When evict selects a victim key x by Clock, it first increases key _x’_s version counter to inform other threads currently reading x to retry; it then deletes x from the hash table to make x unreachable for later readers, including those retries; and finally it increases key x’s version counter again to complete the change for x. Note that evict and insert are both serialized using locks so when updating the counters they cannot affect each other.