Algorithmic improvements for fast concurrent cuckoo hashing Li et al, EuroSys 2014
Today’s paper continues the work on optimistic cuckoo hashing that we looked at yesterday, extending it to support multiple writers and even higher throughput. One of the original goals for the research was to take advantage of the hardware transactional memory support in the Intel Haswell chipset, and indeed the authors do do this, but it turned out not to be as significant as they expected:
Contrary to our expectations… we ended up implementing a design that performs well regardless of its use of HTM, and the bulk of our time was not spent dealing with concurrency mechanisms, but rather in algorithm and data structure engineering to optimize for concurrent access. For fast hash tables, HTM’s biggest benefit may be to software engineering, by reducing the intellectual complexity of locking, with a modest performance gain as a secondary benefit.
There’s no substitute for good design!
The careful reader will have noted that Mem3C as we looked at yesterday is optimised for read-dominated workloads, and its single writer thread becomes an increasing limit on throughput as you add more writes into the mix. Starting with the Mem3C design, Li et al. extend it to support high throughput for multiple writers:
Our design uses algorithmic engineering of Cuckoo hashing combined with architectural tuning in the form of effective prefetching, use of striped fine-grained spinlocks, and an optimistic design that minimizes the size of the locked critical section during updates.
The end result achieves ~40M inserts/second on a 16-core machine, outperforming Intel’s Thread Building Blocks by 2.5x and using less than half of the memory.
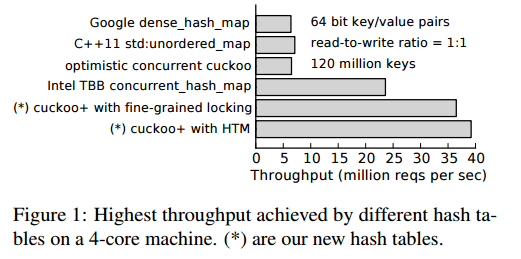
I shall once more focus on the core algorithm enhancements, and refer the reader to the full paper for the detailed evaluation. Let’s begin by looking at the general improvements made to improve concurrency – the most significant contributors to the overall gains, and then we can take a look at some of the HTM and TSX specifics.
Improving cuckoo hashing concurrency
The team started out by considering the existing design from the perspective of three well-known concurrency principles:
- P1: Avoid unnecessary or unintentional access to common data (this principle was already adhered to in the baseline the authors compare against)
- P2: Minimize the size and execution time of critical sections, and
- P3: Optimize the concurrency control mechanism to match the expected behaviour of the data structure.
Perhaps the third principle requires a little further explanation, at a risk of giving the game away:
For example, because the critical sections of our optimized hash tables are all very short, we use lightweight spinlocks and lock-striping in the fine-grained locking implementation, and optimize TSX lock elision to reduce transactional abort rate when applying it to the coarse-grained locking implementation.
Recall that the optimistic cuckoo hashing of Mem3C already has the following features:
- hashing insertions are done ‘back-to-front’ to eliminate false misses
- lock striping is used for efficient concurrency control
- reads can be performed with no cache line writes by using optimistic locking
By using these techniques with only version counters and a simple global lock for writers, MemC3 provided substantial gains for read-intensive workloads, but still performed poorly for write-heavy workloads.
The scheme used in MemC3 was not obviously amenable to the fine-grained locking needed to support high throughput with multiple concurrent writers. Firstly, the cuckoo path can be very long (say a few hundred items, which equates to hundreds of locks), and secondly those locks would need to be nested which can easily cause deadlocks unless great care is taken.
Improvements are made in four areas:
- Minimising the time spent in critical sections
- Reducing the length of cuckoo paths
- Increasing set-associativity
- Introducing fine-grained locking
Minimising critical sections
In Mem3C insert locks the hash table at the beginning of the insert process, and unlocks it at the end. This means that cuckoo path discovery happens within the critical section. A simple change is to search for an empty slot before acquiring any lock, and only lock the table once the the actual insert itself begins. This allows multiple insert threads to look for cuckoo paths at the same time. Once inside the critical section, it only remains to validate the chosen path (much quicker than finding one in the first place), and then proceed as normal if it is unchanged, or restart the insert process if the path has subsequently become invalid.
A path becomes invalid with probability
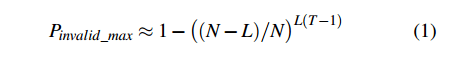
Where N is the number of entries in the hash table, L is the maximum length of a cuckoo path, and T is the number of threads.
For example, when N = 10 million, L = 250, and T = 8 then the upper bound on path invalidation is 4.28%. In practice the expected probability would be much lower, but the optimisations that follow reduce the odds of path invalidation by orders of magnitude…
Reducing cuckoo path length
The standard cuckoo algorithm does a ‘depth first search’ when looking for a cuckoo path for insert. That is, it picks a victim slot at random from the two buckets for the key in question, and then chases that path down until an empty slot is found or the maximum path length is reached. That makes sense in the original algorithm when evictions are happening along the way at each step. But now that we’ve separated path discovery and eviction, it is no longer the best option.
Instead, what if we do a breadth first search, looking at the paths from each of the slots in the two buckets in parallel. That is, imagine all of the slots in the initial two buckets are taken (which must be the case, otherwise we wouldn’t be looking for a path at all). Now we try one step from each of those slots (instead of just picking one). If we find an empty slot, great, otherwise we go another step. This process is guaranteed to find the shortest possible cuckoo path, and probably much more quickly than the depth-first alternative.
For a B-way set-associative cuckoo hash table (fancy way of saying each bucket has B slots), where the maximum number of slots to be checked before declaring the hashtable too full is M, then the maximum length of a cuckoo path found by breadth-first search is given by:
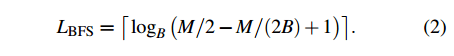
In MemC3 B = 4 and M = 2000 by default. Using MemC3’s twin-path depth-first search strategy, MemC3 will reach a maximum of 250 displacements for an insert. In the same setup, the BFS approach will reach a maximum of only 5 displacements. Reducing the path length so dramatically of course will have major implications when it comes to considering fine-grained locking…
Using more slots per bucket
If you use more slots per bucket (higher set-associativity) then read throughput is reduced (as you have to scan more slots across the two buckets). So long as a bucket fits in a cache line this effect should not be too serious. In contrast, more slots per bucket should improve write throughput because each insert reads fewer random buckets when looking for an empty slot.
So it’s a trade-off, and the empirical results suggest that using an 8-way set associative hash table provides the best overall compromise.
Fine-grained locking
Optimizing cuckoo hashing’s reversed path-swap ordering, combining with the dramatic path length reduction outlined above, makes fine-grained locking practical once more.
… we go back to the basic design of lock-striped cuckoo hashing and maintain an actual lock in the stripe in addition to the version counter (our lock uses the high-order bit of the counter). Here we favor spinlocks using compare-and-swap over more general purpose mutexes. A spinlock wastes CPU cycles spinning on the lock while other writers are active, but has low overhead, particularly for uncontended access. Because the operations that our hash tables support are all very short and have low contention, very simple spinlocks are often the best choice.
The combination of all of the above optimisations results in a hash table that is highly memory efficient and also permits highly-concurrent read-write access.
Exploiting Intel Transactional Synchronization Extensions (TSX)
Recently, Intel released Transactional Synchronization Extensions (TSX), an extension to the Intel 64 architecture that adds transactional memory support in hardware. Part of the recently-released Intel Haswell microarchitecture, TSX allows the processor to determine dynamically whether threads need to serialize through lock-protected critical sections, and to serialize only when required.
Hardware memory transactions are best-effort, so you need a fallback path if a hardware txn fails for some reason. Lock elision is the most obvious: execute a lock-protected region speculatively as a transaction, and fallback to normal locking if the lock does not succeed. There are three common reasons for hardware transactions to abort:
- Data conflicts on transactionally accessed addresses
- Limited resources for transactional stores, and
- Use of TSX-unfriendly instructions or system calls (e.g. mmap).
Adhering to concurrency principles P1 and P2 discussed earlier therefore also helps greatly to reduce TSX aborts. By reducing the size of the transactional region in a cuckoo insert from hundreds of bucket reads and writes to just a few transaction aborts caused by data conflicts or resource limits are much reduced.
Minimizing the use of TSX-unfriendly instructions in the critical section is future work. The authors do however use a tuned version of TSX lock elision matched to the application’s transactional behaviour, details can be found in appendix A of the paper.
libcuckoo
The focus of this paper was on the algorithmic and systems changes needed to achieve the highest possible hash table performance. As is typical in a research paper, this results in a fast, but somewhat “bare-bones” building block with several limitations, such as supporting only short fixed-length key-value pairs. To facilitate the wider applicability of our results, one of our colleagues has, subsequent to the work described herein, incorporated this design into an open-source C++ library, libcuckoo. The libcuckoo library offers an easy-to-use interface that supports variable length key value pairs of arbitrary types, including those with pointers or strings, provides iterators, and dynamically resizes itself as it fills. The price of this generality is that it uses locks for reads as well as writes, so that pointer-valued items can be safely dereferenced, at the cost of a 5-20% slowdown. Specialized applications will, of course, still get the most performance using the hybrid locking/optimistic approach described herein, and part of our future work will be to provide one implementation that provides the best of both of these worlds.
