Efficiently Compiling Efficient Query Plans for Modern Hardware– Neumann, VLDB 2011
Updated with direct links to Databricks blog post now that it is published.
A couple of weeks ago I had a chance to chat with Reynold Xin and Richard Garris from Databricks / Spark at RedisConf, where we were both giving talks. Reynold and Richard did a great demonstration of Spark running on top of Redis. They also told me about some improvements to Spark the Databricks team have been working on, inspired by Neumann’s 2011 paper “Efficiently Compiling Efficient Query Plans for Modern Hardware.” Later on today you’ll be able to read more about how they’ve applied these ideas in the Apache Spark 2.0 release on the Databricks blog. Let’s take a look at Neumann’s paper to fill in some of the background…
The traditional steps in relational query processing are to parse and validate the query; perform semantic preserving rewrites to simplify and normalize it; and then an optimizer creates a query plan for executing the query. The query plan effectively specifies a dataflow diagram that pipes data through a graph of query operators. A query executor then carries out the plan. Per Hellerstein et al., in some systems the optimizer creates low-level op codes and the query executor acts as a runtime interpreter. “In other systems, the query executor receives a representation of the dataflow graph and recursively invokes procedures for operators based on the graph layout… Most modern query executors employ the iterator model that was used in the earliest relational systems.”
The system most strongly associated with the operator model is Volcano, and you may hear reference to ‘the Volcano-style.’ By introducing a uniform interface for all operators, Volcano decouples operators from their inputs. Volcano’s exchange operators exploit this to introduce inter- and intra-operator parallelism… Anyway, I digress, the iterator interface is based on a simple open, next, close protocol.
Streaming interfaces based on iterators aren’t just restricted to database management systems of course. Last year we looked at Streams à la carte: Extensible pipelines with object algebras in which Biboudis et al. studied streaming interfaces in Java, Scala, and C#. Here you’ll find a discussion of push vs pull dataflows. In the pull model, each streaming operator pulls tuples from its predecessors in the pipeline by calling next. You end up with three virtual calls for each item: hasNext(), next(), and accept(). If you flip the processing order around and instead push elements through the stream, you can eliminate two virtual calls per element.
Neumann observes similar problems with the pull model in the context of query execution, but goes even deeper to understand it’s relation to modern hardware:
…This is a very nice and simple interface, and allows for easy combination of arbitrary operators, but it clearly comes from a time when query processing was dominated by I/O and CPU consumption was less important: first, the next function will be called for every single tuple produced as intermediate or final result, i.e. millions of times. Second, the call to next is usually a virtual call or a a call via a function pointer. Consequently, the call is even more expensive than a regular call and degrades the branch prediction of modern CPUs. Third, this model often results in poor code locality and complex book-keeping.
(Aside: in ‘Architecture of a Database System‘ Hellerstein et al. point out that ‘in practice, throughput in a well-tuned transaction processing DBMS is typically not I/O bound,’ and, ‘this fact is often a surprise to people who have not operated or implemented a database system.’).
To maximize query processing performance Neumann argues, we have to maximize data and code locality. We’d like to keep data in registers for as long as possible during query processing… but how?
The classical iterator model is clearly ill-suited for this, as tuples are passed via function calls to arbitrary functions – which always results in evicting the register contents. The block-oriented execution models have fewer passes across function boundaries, but they clearly also break the pipeline as they produce batches of tuples beyond register capacity… We therefore reverse the direction of data flow control. Instead of pulling tuples up, we push them towards the consumer operators. While pushing tuples, we continue pushing until we reach the next pipeline-breaker…
A pipeline breaker is defined as something that takes an incoming tuple out of the CPU registers. With data being pushed from one pipeline breaker to the next, any operators in between leave tuples in the CPU registers making them very efficient.
Furthermore, in a push-based architecture the complex control flow logic tends to be outside tight loops, which reduces register pressure. As the typical pipeline-breakers would have to materialize the tuples anyway, we produce execution plans that minimize the number of memory accesses.
Consider the following SQL query:
select *
from R1,R3,
(select R2.z, count(*)
from R2
where R2.y = 3
group by R2.z) R2
where R1.x = 7 and R1.a = R3.b and R2.z = R3.c
With accompanying execution plan:
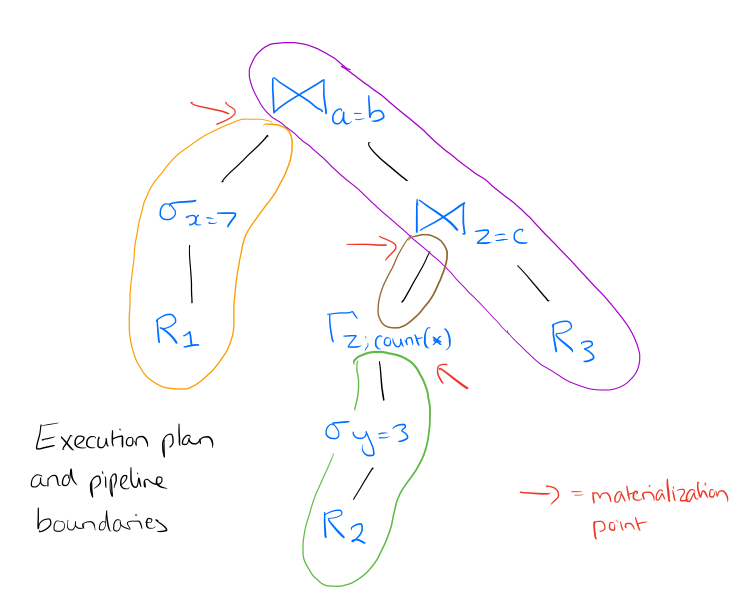
The materialization points (pipeline breaks) are highlighted.
As we have to materialize the tuples anyway at some point, we therefore propose to compile the queries in a way that all pipelining operations are performed purely in CPU (i.e. without materialization), and the execution itself goes from one materialization point to another.
The compiled query results in code that looks like this:

There are four code fragments, corresponding to the four pipeline fragments in the query plan. Each fragment is strongly pipelining, and can keep all of its tuples in CPU registers, only accessing memory to retrieve new tuples or to materialize their results.
Furthermore, we have very good code locality as small code fragments are working on large amounts of data in tight loops. As such, me can expect to get very good performance from such an evaluation scheme.
Note that individual operator logic can be spread out over multiple code fragments. We lose the neat simple structure of the iterator model, but what we gain in its place is the ability to generate near optimal assembly code.
The abstractions needed to keep the code maintainable and understandable exist, i.e. all operators offer a uniform interface (produce / consume), but they exist only in the query compiler itself. The generated code exposes all the details (for efficiency reasons), but that is fine, as the code is generated anyway.
Conceptually, produce asks the operator to produce its result tuples, and these are pushed to the consuming operator by calling its consume function. In the example above, execution would begin at the top of the tree, by calling produce on the join(a=b) node, which in turn calls produce on the select(x=7) node, with calls produce on R1 to access the relation. Since R1 is a leaf it can produce tuples by itself, and begins the push of tuples by calling consume on the select node…
The overall code generation scheme is as follows:

The real translation code is significantly more complex of course, as we have to keep track of the loaded attributes, the state of the operators involved, attributed dependencies in the case of correlated subqueries, etc., but in principle this simple mapping already shows how we can translate algebraic expressions into imperative code.
The authors use LLVM to generate portable assembler code (the Spark team generate Java bytecode). LLVM hides the problem of register allocation by offering an unbounded number of registers. LLVM produces extremely fast machine code, and usually requires only a few milliseconds for query compilation. The full code generator for SQL-92 was implemented in 11,000 lines of code. (The Apache Spark implementation generates Java bytecodes).
Code generation details
The LLVM code generated using the strategy sketched above is extremely fast. The main work is done in a tight loop over the tuples, which allows for good memory pre-fetching and accurate branch prediction. In fact, the code is so fast that suddenly code fragments become a bottleneck that were relatively unimportant as long as the other code was slow…
Branches are laid out to make them amenable to ultra efficient CPU execution – branches are very cheap so long as branches are taken either nearly always or almost never. A branch taken with a probability of 50% ruins the branch prediction… the query compiler therefore aims to produce code that allows for good branch prediction.
By organizing the data flow and the control flow such that tuples are pushed directly from one pipeline breaker into another, and by keeping data in registers as long as possible, we get excellent data locality. However, this does not mean that we have to process tuples linearly, one tuple at a time. Our initial implementation pushes individual tuples, and this already performs very well, but more advanced processing techniques can be integrated very naturally in the general framework.
One such technique is the processing of several tuples at a time to exploit SIMD registers. LLVM directly allows for modelling SIMD values as vector types, thus the impact on the overall code generation framework is relatively minor. (See also SPARK-12992).
Multi-core parallelism can also be supported with almost no code changes. Usually the data fragments are determined by the storage system, but they could instead come from a parallelizing decision.
Note that the “parallelizing decision” in itself is a difficult problem! … This is beyond the scope of this paper. But for future work it is a very relevant problem as the number of cores is increasing.
Evaluation
The LLVM code generation technique was implemented in a database system called HyPer, and compared to HyPer with C++ code generation, the VectorWise and MonetDB systems, and a commercial DBMS identified only as ‘X’. DB ‘X’ is a general purpose disk-based system.
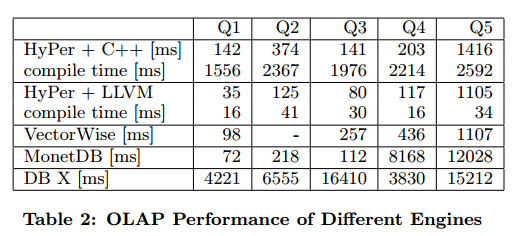
The comparison between the C++ backend and the LLVM backend is particularly interesting here. First, while the C++ version is reasonably fast, the compact code generated by the LLVM backend is significantly faster… The second observation is that even though the queries are reasonably fast when cross-compiled into C++, the compile time itself is unacceptable, which was part of the reason why we looked at alternatives for generating C++ code.
The authors also examined the efficiency of the generated code with respect to branching and caching. Using the callgrind tool of valgrind they were able to limit profiling just to query processing itself and obtained the following results for the five queries in the workload:

The first block shows the number of branches, the number of branch mispredictions, and the number of I1 instruction cache misses. The second block shows the number of L1 data cache misses (D1), and L2 misses. The final block is the total number of executed instructions.
Our implementation of the compilation framework for compiling algebra into LLVM assembler is compact and maintainable. Therefore the data-centric compilation approach is promising for all new database projects. By relying on mainstream compilation frameworks the DBMS automatically benefits from future compiler and processor improvements without re-engineering the query engine.
A little history on query compilation and interpretation
This isn’t the first time researchers have looked at compilation strategies for query processing. Section 4.3 of ‘Architecture of a Database System‘ contains the following relevant passage:
The original System R prototype compiled query plans into machine code, whereas the early INGRES prototype generated an interpretable query plan. Query interpretation was listed as a “mistake” by the INGRES authors in their retrospective paper in the early 1980’s,but Moore’s law and software engineering have vindicated the INGRES decision to some degree. Ironically, compiling to machine code is listed by some researchers on the System R project as a mistake. When the System R code base was made into a commercial DBMS system (SQL/DS) the development team’s first change was to replace the machine code executor with an interpreter. To enable cross-platform portability, every major DBMS now compiles queries into some kind of interpretable data structure. The only difference between them is the intermediate form’s level of abstraction. The query plan in some systems is a very lightweight object, not unlike a relational algebraic expression, that is annotated with the names of access methods, join algorithms, and so on. Other systems use a lower-level language of “op-codes,” closer in spirit to Java byte codes than to relational algebraic expressions.
Neumann et al. use the ‘op-codes’ of the LLVM to generate portable assembler code, which can then be executed directly using an optimizing JIT compiler provided by LLVM.
Don’t forget to check out the Databricks blog later on today where you’ll be able to see details of the implementation in Spark and some very impressive performance results!