Musketeer: all for one, one for all in data processing systems – Gog et al. 2015
For between 40-80% of the jobs submitted to MapReduce systems, you’d be better off just running them on a single machine…
It was Eurosys 2015 last week, and a great new crop of papers were presented. Gog et al. from the Cambridge Systems at Scale (CamSaS) initiative published today’s choice, ‘Musketeer’. In fact, it’s going to be tomorrow’s choice as well since there’s more good material here than I can do justice to in one write-up. Today I want to focus on the motivation section from the Musketeer paper, which sheds a lot of light on the question “what’s the best big data processing system?” Tomorrow we’ll look at Musketeer itself.
What’s the best big data processing system?
“For what?” should probably be your first question here. No-one system is universally best. The Musketeers conducted a very interesting study that looked into this:
We evaluated a range of contemporary data processing systems – Hadoop, Spark, Naiad, PowerGraph, Metis and GraphChi – under controlled and comparable conditions. We found that (i) their performance varies widely depending on the high-level workflow; (ii) no single system always out-performs all others; and (iii) almost every system performs best under some circumstances
It’s common sense that each system must have a design point, and therefore you should expect it to work best with workloads close to that design point. But it’s easy to lose sight of this in religious wars over the ‘best’ data processing system – which can often take place without any context.
Let’s assume you do have a particular workload in mind, so that we can ask the much better question: “what’s the best data processing system for this workload?”. Even then…
Choosing the “right” parallel data processing system is difficult. It requires significant expert knowledge about the programming paradigm, design goals and implementation of the many available systems.
Tomorrow we’ll see how Musketeer can help make this choice for you, and even retarget your workflow to the back-end for which it is best suited. Even if you don’t use Musketeer though, the analysis from section 2 of the paper is of interest.
Gog et al. examined makespan – the entire time to execute a workflow including not only the computation itself, but also any data loading, pre-processing, and output materialization. From this, they determine four key factors that influence system performance:
- The size of the input data. Single machine frameworks outperform distributed ones for smaller inputs.
- The structure of the data. Skew and selectivity impact I/O performance and work distribution.
- Engineering decisions made during the constructing of the data processing system itself. For example, how efficiently it can load data.
- The computation type, since specialized systems operate more efficiently.
In all systems they studied, the ultimate source and sink of data is files in HDFS.
Do you really need that fancy distributed framework?
You might recall the story from last year of awk and grep on the command-line of a single machine outperforming a Hadoop cluster by a factor of 235.
Gog et al. studied the effect on input size on framework performance. Take a look at their figure 2a, below:
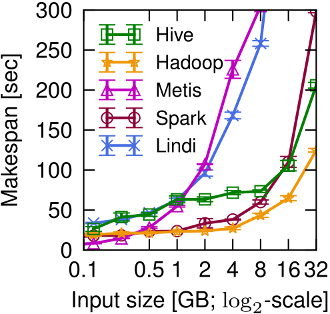
For small inputs (≤0.5GB), the Metis single-machine MapReduce system performs best. This matters, as small inputs are common in practice: 40– 80% of Cloudera customers’ MapReduce jobs and 70% of jobs in a Facebook trace have ≤ 1GB of input.
This last point bears repeating, and if I can generalize slightly: for between 40-80% of the jobs submitted to MapReduce systems, you’d be better off just running them on a single machine.
Likewise a join workflow producing 1.9GB of data runs best on a single machine. A larger join producing 29GB works best on Hadoop. See figure 2b below.
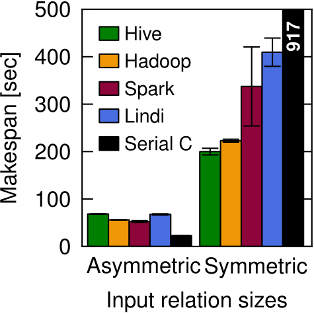
Do you really need that new shiny thing?
Well, maybe! But likewise there is no universal guarantee that e.g. Spark is better than Hadoop MR. It depends on what you’re trying to do…
Once the data size grows, Hive, Spark and Hadoop all surpass the single-machine Metis, not least since they can stream data from and to HDFS in parallel. However, since there is no data re-use in this workflow, Spark performs worse than Hadoop: it loads all data into a distributed in-memory RDD before performing the projection.
What are you optimising for?
For workflows involving iterative computations on graphs, it won’t surprise you to learn that specialized graph processing systems do well.
It is evident that graph-oriented paradigms have significant advantages for this computation: a GraphLINQ implementation running on Naiad outperforms all other systems. PowerGraph also performs very well, since its vertex-centric sharding reduces the communication overhead that dominates PageRank… However, the fastest system is not always the most efficient.
Look at figure 3a below. With smaller graphs the 100 node clusters may be the fastest, but you’re getting nowhere near a 100x speed-up for all that investment (we’re on the RHS of the Universal Scalability Law curve). If you prepared to wait just a little longer for results, you can get your answer with dramatically less compute power (also compare e.g. PowerGraph on 16 nodes with GraphChi on one).
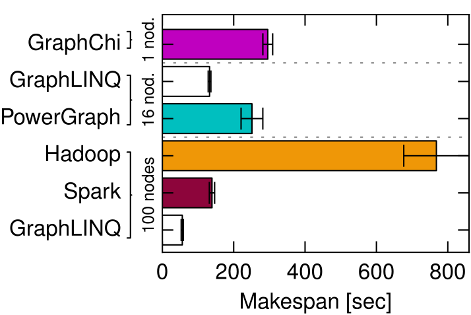
Yes, but what’s the best data processing system?
Our experiments show that the “best” system for a given workflow varies considerably. The right choice – i.e., the fastest or most efficient system – depends on the workflow, the input data size and the scale of parallelism available.
If you think a little carefully about what you’re trying to achieve – when you really need fully precise results vs. good approximations; when you really need to run on a distributed framework vs. a single machine; when you really need results quickly vs. waiting a little bit longer but being much more efficient – you can significantly improve the overall effectiveness of your data platform.
Tomorrow we’ll see how Musketeer can help to make all this more practical and manageable by enabling workflows to be written once and mapped to many systems – even combining systems within a workflow.
Postscript
The authors did something very neat with this paper – in the pdf version, every figure is actually a link to a webpage describing the experiments and data sets behind it. Really great idea, thanks!