Aligning superhuman AI with human behavior: chess as a model system, McIlroy-Young et al., KDD’20
t’s been a while, but it’s time to start reading CS papers again! We’ll ease back into it with one or two papers a week for a few weeks, building back up to something like 3 papers a week at steady state.
How human-like is superhuman AI?
AI models can learn to perform some tasks to human or even super-human levels, but do they then perform those tasks in a human-like way? And does that even matter so long as the outcomes are good? If we’re going to hand everything over to AI and get out of the way, then maybe not. But where humans are still involved in task performance, supervision, or evaluation, then McIlroy-Young et al. make the case that this difference in approaches really does matter. Human-machine collaboration offers a lot of potential to enhance and augment human performance, but this requires the human and the machine to be ‘on the same page’ to be truly effective (see e.g. ‘Ten challenges for making automation a ‘team player’ in joint human-agent activity‘).
The central challenge in realizing these opportunities is that algorithms approach problems very differently from the ways that people do, and thus may be uninterpretable, hard to learn from, or even dangerous for humans to follow.
As well as outright behaviour and performance once fully trained, a related interesting question is whether or not the AI model improves with training in the same way that humans do on the same task as their skill levels increase. I.e., how do human and AI performances compare at different skill levels, and are the learning trajectories similar? This is the question that most interests me in the paper, because if we can successfully model human learning trajectories on a task, then we ought to be able to build very effective AI coaches to improve human performance.
Chess
These are big questions, and chess turns out to be the perfect testbed for exploring them:
- we have chess engines that have achieved super-human performance (e.g, AlphaZero)
- these engines were not trained on human games
- we also have large databases of human games available though,
- we have a recognised method of assessing player skill levels (rating points).
The second point in particular is quite important – if you train a model by giving it a set of labelled data based on what a human did in a given situation, then you’ll get a model that mimics what humans do. In reinforcement learning situtuations though, the model is trained by getting feedback on the outcome of its interactions with an external enviroment: in the case of AlphaZero, the training is done by playing games against itself.
This paper explores several key questions in the context of chess play:
- Move matching: Can a trained chess engine predict the move that a human player is likely to make in any given situation? An engine that does well at this task will be able to play much more like a human.
- How does move matching performance vary with the strength of the AI model, and also with the strength of the human player? For example, a player with a lower rating is going to play different moves to a player with a stronger one.
- Blunder prediction: Can we train a model to predict when a human player at a given skill level is likely to make a mistake? That is, play a move which significantly lessens the win-prediction for the player compared to the best move available in the situation.
If we can predict, for example, the moves that a player rated 1500 is likely to make, and the moves that a player rated 1600 is likely to make, then one very interesting thing we could do is find the scenarios where those predicted moves differ. These are very likely to be the areas that a 1500-rated player should work on to improve their game and take it to the next level. And within those areas, the place to start is with the blunders that 1500-rated players make and 1600-rated players tend not to.
Stockfish, AlpaZero (Leela), and Maia
Stockfish is one of the most popular chess engines in the world, and the reigning computer chess world champion. It uses heuristics developed by human experts to evaluate positions encountered during alpha-beta game-tree search. It can be configured to play at different strengths, which is achieved by limiting the depth of the game-tree that it explores.
AlphaZero is DeepMind’s chess engine that uses a DNN to evaluate positions, combined with Monte Carlo tree search. The evaluation in this paper is done using the Leela open source implementation.
Maia is a derivative of Leela developed by the authors for the purposes of this study. Unlike AlphaZero/Leela, Maia is trained on human games (from Lichess) as opposed to self-play. Furthermore, Maia does not use any tree search when determining which move to play. Instead Maia simply outputs the top recommended move for a given position from the DNN. Because it is trained on human games, it is also possible to parameterise Maia by training it on human games played at a particular skill level (rating bin), and the authors do this for nine different rating bins between 1100 and 1900 (Glicko-2).
These three engines are used to explore move matching and blunder prediction performance.
Move matching
There are nine test sets based on human games played on Lichess, for each of nine ratings bins (1100-1199, 1200-1299, …, 1900-1999). In the move matching task, an engine is given a position and asked to output a move. In the case of Maia, Maia is also given the previous 6 moves for each player. The accuracy scored is based on how often the engine move matches the human move.
Stockfish matches human moves 33-41% of the time. You might think this is because Stockfish is a much stronger player than the humans – i.e. it is suggesting ‘better’ moves when there is no match, but if we weaken Stockfish (by limiting the depth of search) so that its rating falls to comparable strength of play, the match rate to human moves gets worse, not better.
…as Stockfish increases or decreases in strength, it does so largely orthogonally from how humans increase or decrease in strength.

Leela engines at rating strengths of 800 to 3,200 are also tested on this task. Again, the stronger versions do best, with a maximum move-matching score of 46%. However, this prediction accuracy doesn’t vary much across human ratings, suggesting that Leela is not doing a good job of characterising or matching human play at different skill levels.
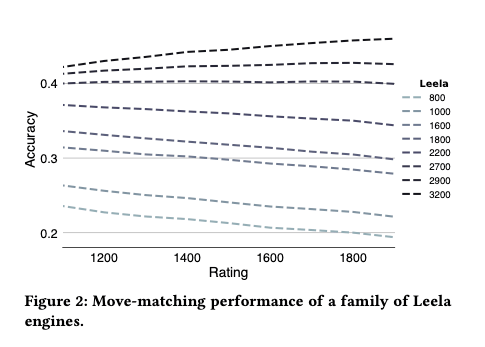
Neither Stockfish nor Leela were designed to match human moves of course, they were just built to play the strongest chess possible. Maia on the other hand is a DNN explicitly trained on the task of predicting what a human player at a given rating level will do in a given board position. Perhaps unsurprisingly then, Maia does better at this task than Stockfish and Leela, predicting human moves with an accuracy of between 46 and 52%. Each of the nine Maia models (trained on games from different rating bins) shows maximum predictive accuracy for games near the rating range Maia was trained on.
Maia thus succeeds at capturing granular human behavior in a tunable way that is qualitatively beyond both traditional engines and self-play neural network systems.
In the figure below, you can see Maia’s prediction performance starting to drop off above 1900, which is the maximum strength level it was trained at.

Another obvious-with-hindsight finding that comes out of this analysis is that move matching prediction increases in accuracy with the quality of the moves played – good moves are easier to predict. However, Maia models are better at predicting human moves than Leela across the whole range of move quality – good moves and bad moves. Which leads onto the next investigation, can we predict when a human is likely to make a blunder (a notably bad move)?
Predicting Mistakes
A move is considered to be a blunder if it worsens a player’s win probability by 10 percentage points or more. A training set is created with moves classified as blunders (182M moves) or non-blunders (272M moves), and a test set with 9M blunders and 9M non-blunders. A baseline random forest model achieves 56.4% blunder prediction accuracy when given just the board position, and 63% accuracy when given the board state plus game metadata (player ratings, clock time remaining). A residual CNN (details are in the paper appendix) achieved up to 71.7% accuracy. We can do even better at blunder prediction when we restrict ourselves to common positions – defined as those that occur more than 10 times in the dataset. Here the authors obtained prediction accuracy of up to 76.9%.
What have we learned?
- If we’re building AI systems that need to collaborate with humans, human-like behaviour doesn’t come for free and is something it seems we have to explicitly design for in the way the model is trained. This could be an important factor for many systems.
- AI models don’t necessarily improve in the same way that humans do – the machine learning trajectory and the human learning trajectory can be different. Humans and machines at the same level of performance may obtain that performance score in different ways. You need to consider more than just performance if building a model for use in a training or coaching situation.
- It is possible to match human performance at different skill levels, and hence to understand what a human might need to do to reach the next performance level.
- It is also possible to build models predicting when humans might make mistakes. These could be used to focus coaching on the most important areas, or maybe to create adaptive user experiences that provide extra checks and balances in the trickiest moments.
