Narrowing the gap between serverless and its state with storage functions, Zhang et al., SoCC’19
"Narrowing the gap" was runner-up in the SoCC’19 best paper awards. While being motivated by serverless use cases, there’s nothing especially serverless about the key-value store, Shredder, this paper reports on. Shredder’s novelty lies in a new implementation of an old idea. On the mainframe we used to call it function shipping. In databases you probably know it as stored procedures. The advantages of function shipping (as opposed to the data shipping we would normally do in a serverless application) are that (a) you can avoid moving potentially large amounts of data over the network in order to process it, and (b) you might be able to collapse multiple remote calls into one if the function traverses structures that otherwise could not be fetched in a single call.
Shredder is "a low-latency multi-tenant cloud store that allows small units of computation to be performed directly within storage nodes."
Running end-user compute inside the datastore is not without its challenges of course. From an operator perspective it makes it harder to follow the classic cloud-native design in which a global storage layer is separate to compute. User functions need to be isolated from each other, and from the parts of the data that they shouldn’t be allowed to see. And with CPU shared across tenants and the data serving infrastructure, some degree of resource isolation to ensure runaway (or malicious) functions don’t hog all the resources is also needed. Shredder addresses the function isolation part of these challenges — though admitting that side-channels will always be hard to completely eliminate — but is silent on the others. Nevertheless, because it fits so nicely with the stateless model of serverless compute, it’s a really interesting idea to explore.
A key challenge… is that serverless functions are stateless. Cloud providers count on this to ease provisioning and fault-tolerance. Realistic applications need access to data and state; this limitation forces functions to access all data remotely, and it forces them to externalize all state into remote cloud storage in order to preserve it across calls or pass state to another function.
(Note that function shipping doesn’t alleviate the need to externalize state).
Shredder’s goals are as follows:
- Tenants should be able to embed arbitrary functions within storage, and those functions should have seamless access to the tenant’s data
- A tenant should not be able to see the code or data of other tenants (isolation)
- Support for thousands of tenant functions, with fine-grained resource tracking to maximise resource utilisation
- High performance
Introducing Shredder
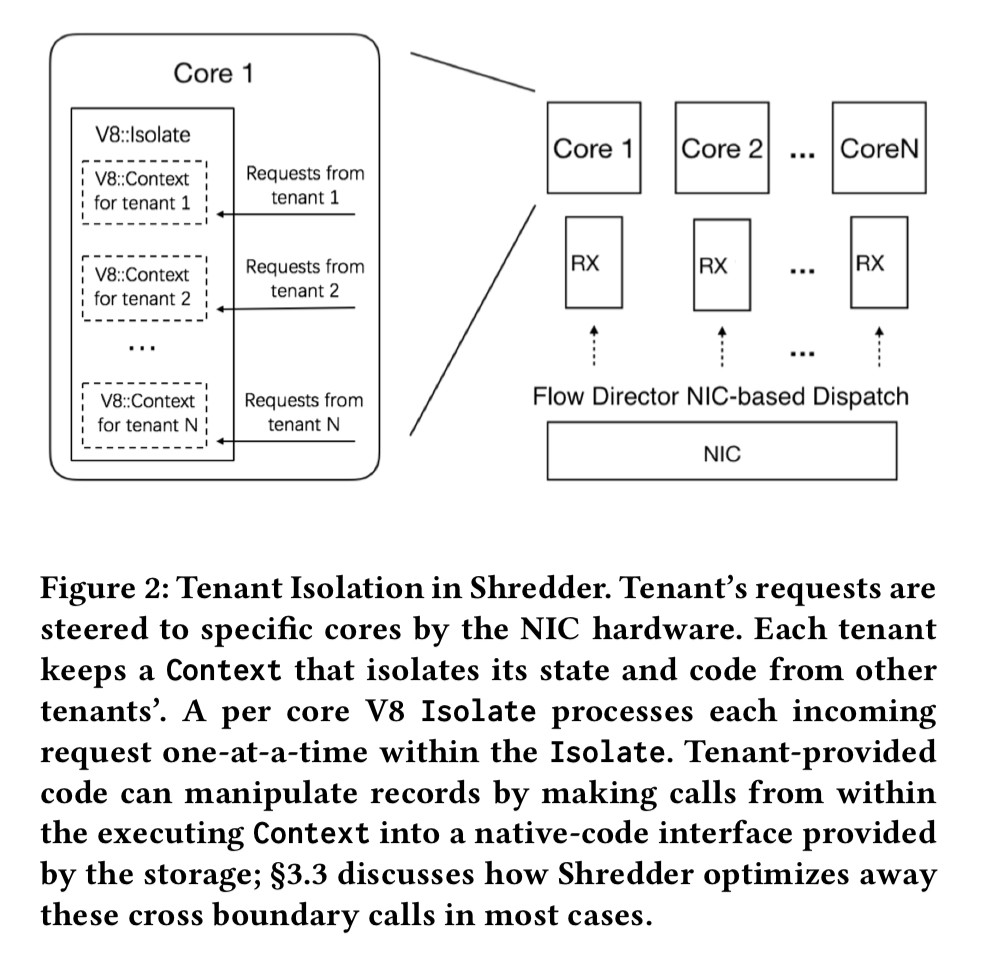
If you want a lightweight, fast-starting, easy to program for, embeddable application runtime that also offers isolation, then a natural choice is V8 isolates. The authors measured the overhead of transferring control into the V8 runtime and back out again at 196 ns. Users write functions in JavaScript (or Web Assembly), and V8 isolates are colocated with (within) the storage subsystem.
V8 is lightweight enough that it can easily support thousands of concurrent tenants. Entry/exit in/out of V8 contexts is less expensive than hardware-based isolation mechanisms, keeping request processing latency low and throughput high.
These V8 isolates sit in the middle of the three layer design within each storage node as the storage function layer. In from of them is a networking layer, and the in-memory storage layer holds the actual data. Shredder’s implementation is built on top of Seastar.
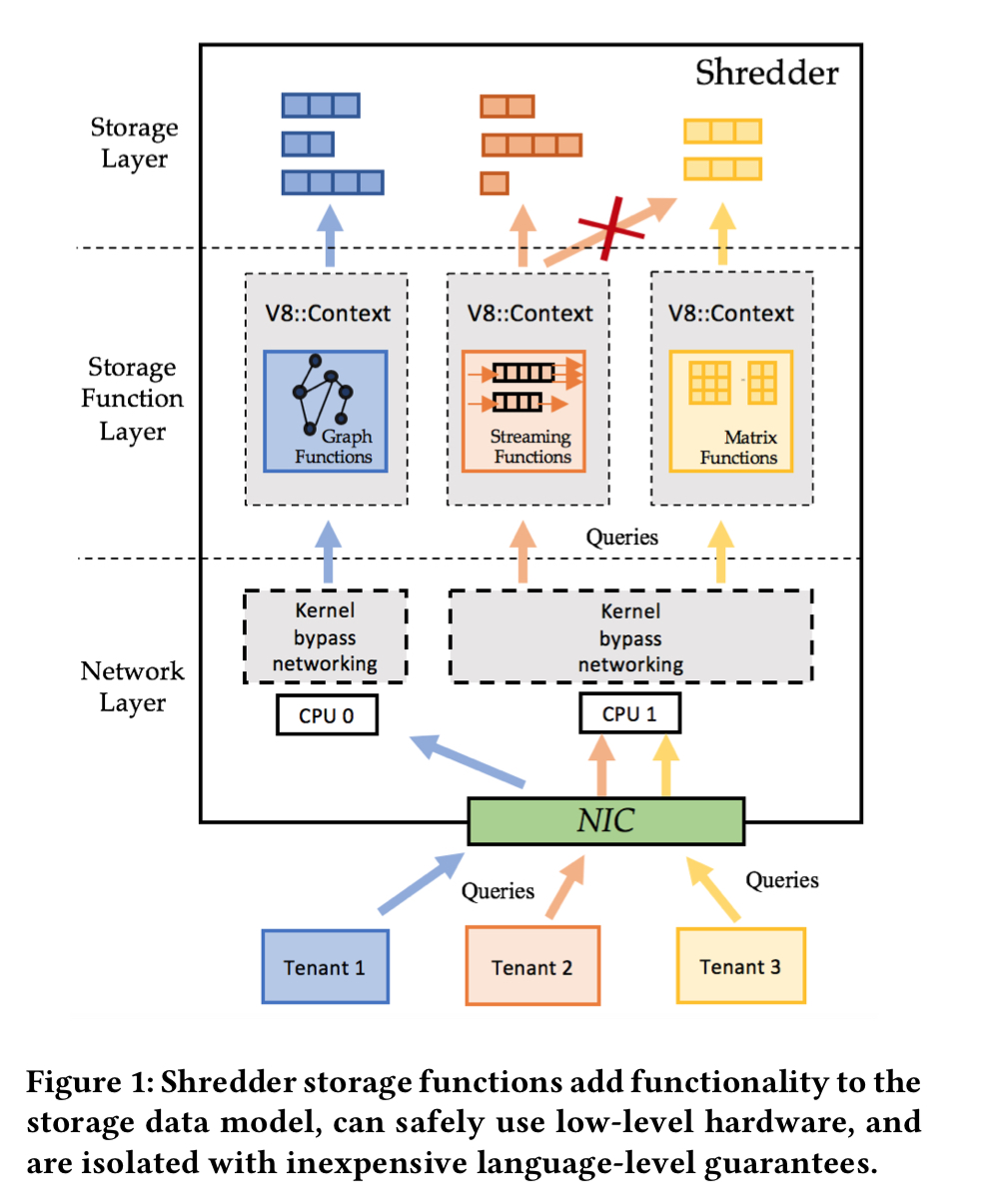
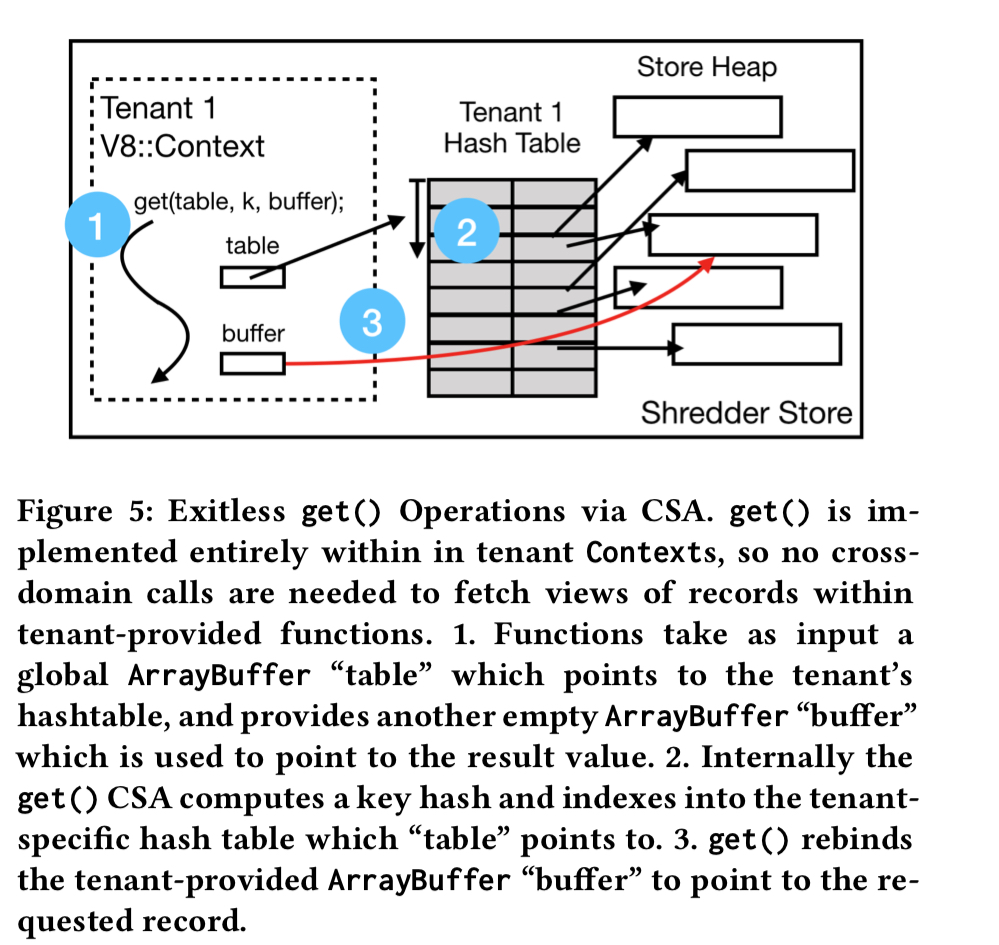
196 ns to get into and out of the V8 runtime is pretty good, but there’s also a 31ns cost every time you transfer control between a JavaScript function and the storage layer, and that can add up if you need to do it for every single data access (note in the above figure that the actual data in the storage layer lives in memory outside of V8). Shredder has two mechanisms that keep the overhead low. Firstly, it supports zero-copy data access using ArrayBuffers mapped to the underlying memory. Secondly, for data-intensive operations requiring continuous transfer of control between a Context and trusted store code (e.g., traversing a linked data structure involving many keys) Shredder has in-context store operations built using V8’s CodeStubAssembler (CSA) (built-ins). (The new recommended way to achieve the same end in V8 now seems to be Torque).
The CSA version of
get()implements the same hashing algorithm as the C++ hashing function for hash tables in the storage layer, so that it directly looks up values in the hash tables. From the storage function perspective, the store still supports the sameget()andput()storage interface. Using code generating from the [CSA Intermediate Representation], tenants can efficiently traverse the structures without execution ever leaving the V8 runtime.
Shredder in action
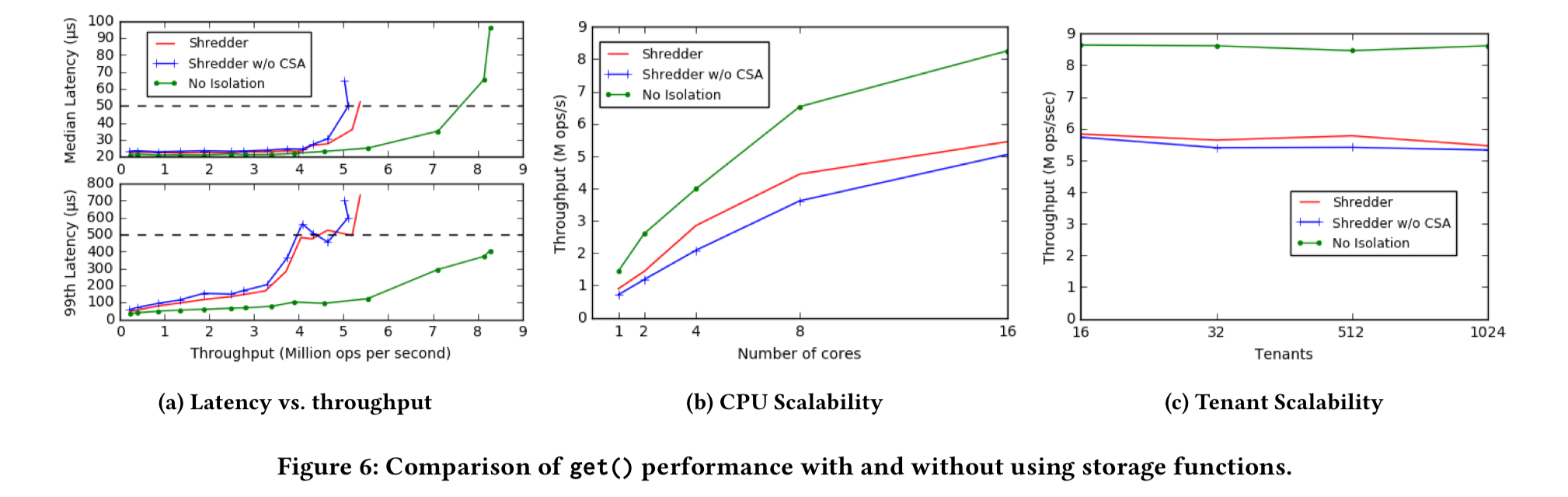
The evaluation show that the core Shredder store can respond to 4 million storage-function invocations per second in 50 µs with tail latencies around 500 µs. Throughput stays pretty constant as the number of tenants is scaled (the evaluation goes up to 1024 tenants). Depending on the use case, CSA increases server throughput by up to 3.5x.
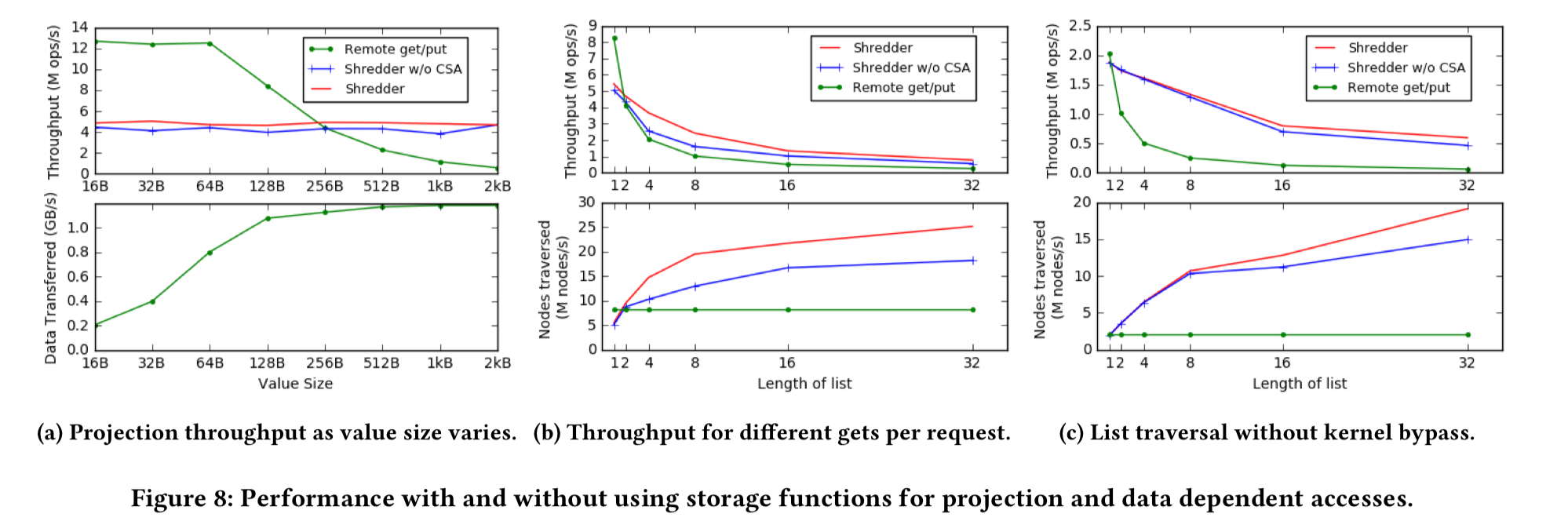
So the core function-shipping design seems to work well. But the real benefits of course come from the fact that you can architect your solution to take advantage of function shipping in the first place. Consider a use case requiring a simple projection of multiple values stored on the server. In Shredder this can be done on the server with a one-line storage function. Another example is a list traversal, which Shredder can do on the server side.
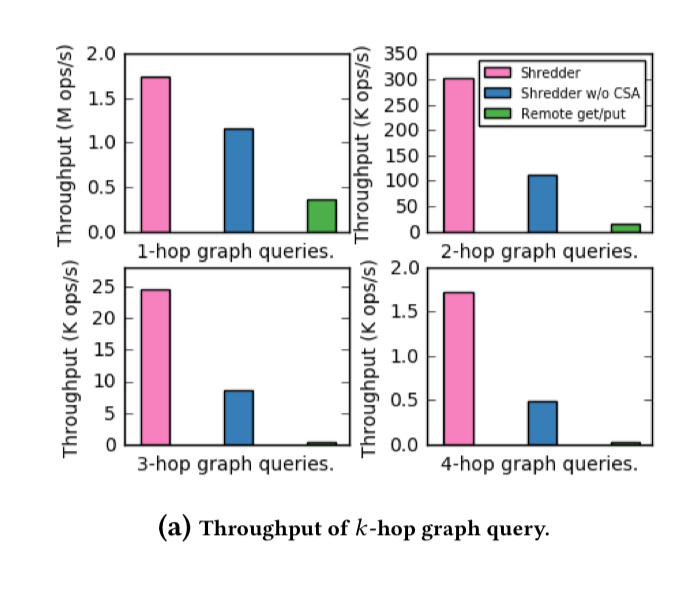
Using a dataset of friend lists from Facebook, the authors implemented a k-hop query application for randomly generated keys on the social graph (which had 4,039 nodes and 88,234 edges in total). The following chart shows the throughput of the Shredder-based implementation with storage functions vs a traditional remote get/put implementation.
The last word
Shredder takes a step towards resolving [the gap between computation and data]; while applications can use it as a normal key-value store, they can also embed compute directly next to their data. Serverless applications already logically decompose applications into fine-grained units in order to ease scaling; we view Shredder as the first step toward exploiting that by recognizing that logically decoupling compute and storage need not mandate physical decoupling.

12 thoughts on “Narrowing the gap between serverless and its state with storage functions”
Comments are closed.