Futzing and moseying: interviews with professional data analysts on exploration practices Alspaugh et al., VAST’18
What do people actually do when they do ‘exploratory data analysis’ (EDA)? This 2018 paper reports on the findings from interviews with 30 professional data analysts to see what they get up to in practice. The only caveat to the results is that the interviews were conducted in 2015, and this is a fast-moving space. The essence of what and why is probably still the same, but the tools involved have evolved.
What is EDA?
Exploration here is defined as “open-ended information analysis,” which doesn’t require a precisely stated goal. It comes after data ingestion, wrangling and profiling (i.e., when you have the data in a good enough state to ask question of it). The authors place it within the overall analysis process like this:

That looks a lot more waterfall-like than my experience of reality though. I’d expect to see lots of iterations between explore and model, and possibly report as well.
The guidance given to survey participants when asking about EDA is as follows:
EDA is an approach to analyzing data, usually undertaken at the beginning of an analysis, to familiarize oneself with a dataset. Typical goals are to suggest hypotheses, assess assumptions, and support selections of further tools, techniques, and datasets. Despite being a necessary part of any analysis, it remains a nebulous art, that is defined by an attitude and a collection of techniques, rather than a systematic methodology.
Survey participants
There were 30 participants in the study, each with at least four years of analysis experience. About half (18) used programming as their primary means of exploring data, and the remainder used visual analytics tools or a mix of tools and programming.
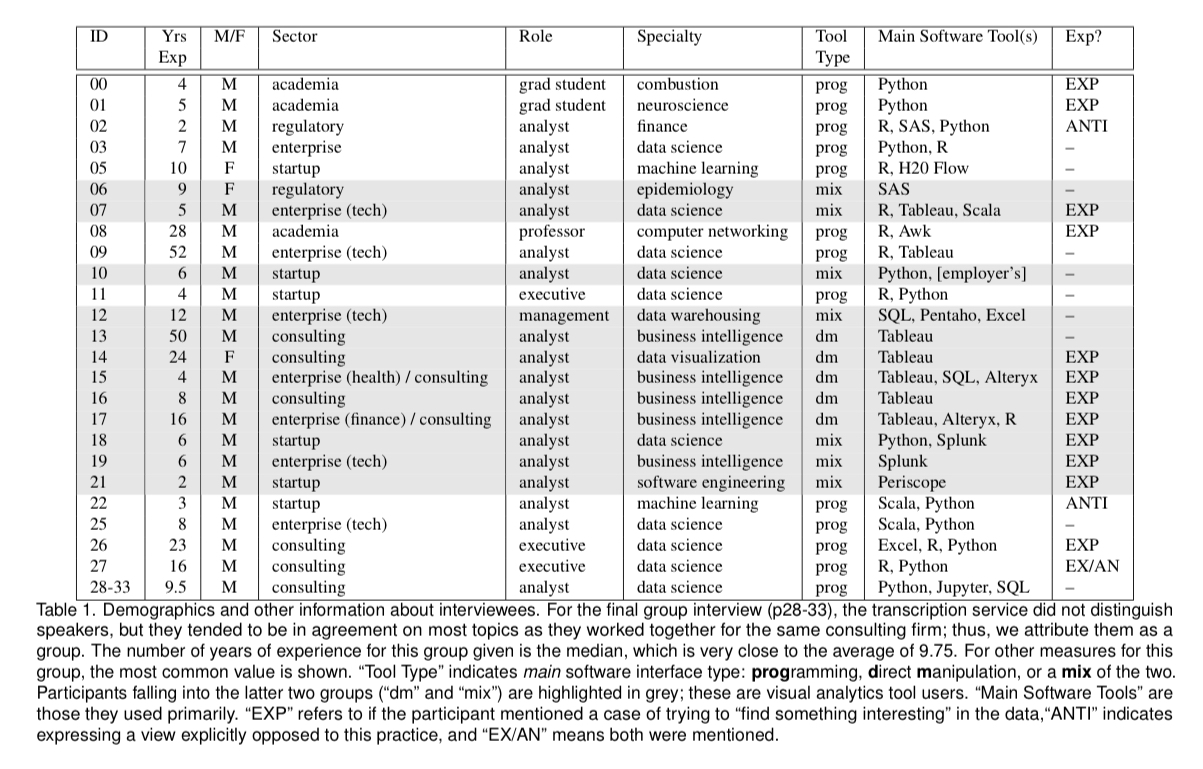
Each interview lasted from one to four hours, and the resulting transcripts were then coded.
EDA in practice: motivations
So what goes on during EDA? According to participant 18:
A lot of putzing, a lot of trying to parse our text logs to see if I could find anything helpful. Yeah… Same as like futzing… Kind of moseying… I don’t know, just poking around with things and see what happens.
Four core activities or motivations for undertaking EDA emerge from the interviews.
- Trying to uncover interesting or surprising results
- Comparing the data with a current understanding of an underlying phenomenon, in a open-ended fashion
- Generating new questions or ideas for further investigation
- Using EDA to test or demonstrate a new methodology or tool
Reason #1 is interesting in as much as if you go looking hard enough you’re bound to find something, as in the well-known multiple-comparisons problem. Four of the 30 participants objected to going on such “fishing expeditions,” or worrying about the costs of data collection and preparation just for ‘futzing and moseying.’
The boundaries of EDA are fuzzy, with participants also describing discovery, wrangling, and profiling tasks under this banner, as well as some aspects of modelling and storytelling. Essentially, EDA in this light is when you’re undertaking analysis activities in an informal manner.
EDA in practice: challenges
Participants complain about the large overheads in discovery, wrangling, and profiling in order to be able to undertake EDA. Another pet-hate is clients with very little idea of their goals and objectives for analysis. For example:
This still happens with surprising regularity, we get clients who are just like can you tell me what’s interesting in this data and how I can make a bazillion dollars in it because I’ve read this article in Forbes and it says that there’s gold in these there hills, and all I need to do is take my data and exhaust it, I can tun it into money.
Once into the EDA process, another major challenge, that we’ve also looked at in the context of machine learning pipelines (e.g. ‘Software engineering for machine learning’), is the lack of documentation, metadata, and provenance.
A common theme was the challenge of dealing with different “versions” of the data, stemming from changes, either planned or accidental, in the data generation and collection process.
Tracking the results of the exploration process, including documenting code, models, and result provenance was another challenge. The MLFlow, DVC and Sacred projects have all emerged since – though how widely used they amongst this audience I’m not sure. There’s a handy comparison of the three here. Anything else that should be on the list here?
EDA in practice: tools
The tools used by the participants were constrained by what was approved / available within the environment they were working in. Interactive visualisations were comparatively less used than you might expect, mostly due to a lack of availability. Without interactivity, the fallback is just to generate lots of static plots.
Only 18 of the 30 participants mentioned using databases and related tools (that statement caused a significant recalibration in my mind, I would have guessed much closer to 100%!). SQL databases and spreadsheets (of course!!) are tied for most commonly used data storage and manipulation solutions. Just under half of the participants used Jupyter notebooks.
The study participants really wanted an environment that combined Jupyter notebooks with Tableau-like visualisations available inside cells. (You can run e.g. Vega-Lite interactive visualisations inside Jupyter these days).
In the time since the interviews were conducted, the popularity of Jupyter notebooks and similar tools have continued to increase for data analysis, and the notebooks themselves have begun to include better support for visualization and widgets to support interactivity. Competing tools that integrate visualization into notebook-style data analysis have also emerged, including interactive widgets for Jupyter notebooks, Zeppelin, which allows for language independent visualization including SQL queries, Observable, which provides a notebook-style interaction for the popular d3 JavaScript visualization language, and a web-based version of the Wolfram language.
More help with wrangling, profiling, and cleaning, as well as capturing and versioning the analysis process itself and its results also came up. However, most analysts are wary of tools to automatically generate visualisations and insights.
The last word:
Given the community’s demonstrated interest in creating tools, particularly “intelligent” ones, for data exploration, we hope this information will provide useful evidence regarding the data exploration experiences of practitioners and will help inspire new research directions.

One thought on “Futzing and moseying: interviews with professional data analysts on exploration practices”
Comments are closed.