Toward sustainable insights, or why polygamy is bad for you Binning et al., CIDR 2017
Buckle up! Today we’re going to be talking about statistics, p-values, and the multiple comparisons problem. Some good background resources here are:
- Statistics Done Wrong, by Alex Reinhart
- p-values on wikipedia
- Misunderstandings of p-values, also on wikipedia
For my own benefit, I’ll try and explain what follows as simply as possible – I find it incredibly easy to make mistakes otherwise! Let’s start with a very quick recap of p-values.
p-values
If we observe some variable 

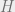

Time to move on from dice rolls. Suppose the variable 

Suppose we see a suspiciously large value. What are the odds of that?
p-value =

(source: wikipedia)
Here’s the first thinking trap. The p-value tells us the likelihood of seeing a given value (greater than or equal to in this example) of X given some hypothesis. We cannot swap the order and treat it as the probability that the hypothesis is true given our observation!

An arbitrary but universally accepted p-value of 0.05 (there’s a 5% chance of this observation given the hypothesis) is deemed as the threshold for ‘statistical significance.’ Really, things don’t divide neatly into ‘statistically significant’ and ‘statistically insignificant’, there’s just a continuous underlying probability. p=0.051 is not dramatically different from p=0.049 even though one is ‘significant’ and the other isn’t.
Multiple comparisons
Take a look at this xkcd cartoon. When we look at the correlation between green jelly beans and acne, we find a statistically significant result (i.e., p < 0.05). Publish!!
But hold on, there’s some kind of weird ‘Schrödinger statistics’ that we have to take into account! The true significance of our green jelly bean finding depends on how many other jelly bean colours we also examined for correlation with acne before we looked at the green beans. Prior observations change the world. Sounds like nonsense doesn’t it! How can the fact that I previously looked into blue beans in any way change the significance of the green bean correlation with acne – the numbers are there in black and white and don’t change whatever I might have looked at before?!
We’ve been tricked into thinking we’ve answered one question ‘what’s the significance of the correlation between green jelly beans and acne?’, when what we’re really doing is answering the following question: ‘what’s the chance of finding at least one jelly bean colour that shows a statistically significant correlation with acne, even though the two phenomena are actually independent?’ It matters a lot whether ‘green’ is something we discovered (we’re answering the latter question), or something we fixed a priori (the former question).
It helps me a lot to think of it this way: imagine a population of 1000 points, in a normal distribution. If you sample a point at random, there’s a slim chance that you picked an outlier point. Not knowing the underlying distribution, you’d say that there was a low chance (i.e., statistically significant) that this really came from the true underlying distribution (even though it did of course). But what if you keep on exploring the space, repeatedly sampling points until you’ve taken e.g., 10,000 samples. What are the chances you’ll catch some of those outlier points in your sample? Incredibly high! Now you could make the true statement “I took a sample at random and found a point which is unlikely to have come from such an underlying distribution with statistical significance.” Such a statement can be very misleading though unless you also qualify it with how many points you looked at before you found it.
Let’s take a concrete example. Suppose under the null hypotheses there’s a 99% chance you’ll observe a value of 


Multiple comparisons and data visualisation
That was a long introduction! Finally we get to the paper. We want to help scientists find interesting correlations in their data – a number of tools have grown up to help do this. The core idea is to have the tool investigate lots of potential correlations, and when one is found that seems to be ‘interesting,’ to show it to the user. Very helpful you say – it would take me ages to discover these things myself! But as we now know, we have to very careful we don’t fall into the multiple comparisons trap. How many combinations were tried before hitting on this one? If we don’t know, then we actually don’t know what the statistical significance of the visualisation we’re looking at is, even though it may appear in isolation to be highly significant.
… without knowing how exactly the system tried to find ‘interesting’ correlations and how many correlations it tested, it is later on impossible for the user to determine what the expected false discovery rate will be across the whole data exploration session.
When using an interactive visualisation tool, not only is the statistical significance of the visualised results unclear, but the more you explore the greater the odds of finding false discoveries.
With every additional hypothesis test the chance of finding a false discovery increases. This problem is known as the ‘multiple comparisons problem’ and has been studied extensively in the statistics literature.
There are some great examples of such spurious correlations found by existing tools in the opening sections of the paper.
The authors set out to build a data exploration and visualization tool called QUDE (Quantifying the Uncertainty in Data Exploration) – pronounced ‘cute’, which only makes sense to American readers!! QUDE integrates a ‘risk detection engine’ alongside the explorer to always show the user the risk that something is a false discovery.
Two fundamental challenges arise when attempting to automatically quantify the risk: (1) the traditional techniques either do not scale well with the number of hypothesis or can not be used in an interactive environment and (2) in many cases it is not clear which hypothesis is currently being tested through a visualization by the user (i.e., the ‘user intent’).
QUDE uses a measure called the False Discovery Rate (FDR). If 
![E[V/R]](https://s0.wp.com/latex.php?latex=E%5BV%2FR%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Beyond controlling the multiple hypothesis error, the QUDE team also plan to include support for detecting other common statistical mistakes in time, including Simpson’s paradox, the Base rate fallacy, imbalance of labels and pseudoreplication.
Given the long introduction I had space only for the briefest description of QUDE itself, so please do go on to check out the full paper if this catches your interest.
I’ll leave you with this opening quote from the paper:
A new study shows that drinking a glass of wine is just as good as spending an hour at the gym” [Fox News, 02/15]. “A new study shows how sugar might fuel the growth of cancer” [Today, 01/16]. “A new study shows late night snacking could damage the part of your brain that creates and stores memories” [Fox News, 05/16].
We’ve all seen endless such stories, often contradicting each other. If we don’t know how many other ‘studies’ researchers did before hitting on these particular results, we really don’t know their significance at all. (I have no knowledge of the situation for the particular cases in the quote above).

That litany of “A new study shows…” reminded me of an article about the Arnold Foundation’s mission to reform science (https://www.wired.com/2017/01/john-arnold-waging-war-on-bad-science/) and John Arnold’s tweet ‘The four most dangerous words: “A new study shows…”‘ (https://twitter.com/johnarnoldfndtn/status/737699374487080961)
Great summary Adrian for those of us who don’t flex our stats muscles everyday!
If anyone has not seen it, Tyler Vigen’s Spurios Correlations site is highly entertaining: http://www.tylervigen.com/spurious-correlations
Different domains uses different p-values, with the social sciences often using 0.05 (with the top ranked journals insisting on 0.01).
A discussion of what p-values might be used in software engineering here:
http://shape-of-code.coding-guidelines.com/2016/09/09/p-values-in-software-engineering/
In “p=0.51 is not dramatically different from p=0.49”, the numbers should be 0.051 and 0.049…
Yes they should, thank you! I’ve updated the post….
This is probably a naive question. Is there a reason why the p-value calculation assumes a Gaussian probability distribution? I started wondering about it after reading Nassim Taleb’s draft http://www.fooledbyrandomness.com/knowledge.pdf. In particular, can the null hypothesis probability distribution come from a type 3 generator (two Gaussian distributions where there is probability p1 of sampling from the “normal” N1 distribution, and probability p2 of sampling from the “rare” N2 distribution, where mean1 << mean2 and sigma1 << sigma2) or type 4 generator (Pareto-Lévy-Mandelbrot distribution) as defined in the draft?
Strictly speaking, a p-value measurement only tests the likelihood of seeing a given result _as compared to some underlying hypothesis_. (As I understand it anyway, but I’m not a statistician!) So as long as you state what the hypothesis you’re comparing against is (e.g., type of underlying distribution) then you should be good to go. Of course, people take short cuts and often don’t say what hypothesis they’re comparing against – for correlations in such a situation we would always assume the null hypothesis.
> why the p-value calculation assumes a Gaussian probability distribution
Awesome question!
This is due to the Central Limit Theorem (https://en.wikipedia.org/wiki/Central_limit_theorem). The theorem, maybe the cornerstone of statistics, states that a large sum of independent random variables tends to be normally distributed. This is actually a large simplification: the normal distribution is not the only one here, but this is the most popular formulation.
So here is the simplified outline for a statistical hypothesis testing process:
1. Formulate the null hypothesis. It’s something that we want to show is unlikely (like “most huskies weight 50kg”). Also formulate an alternative hypothesis (well, in our case that’d be “most huskies weight less then 50kg”).
2. Sample your population. (Go and weight a bunch of huskies. That’s a wonderful Sunday afternoon right there! If you like huskies of course – but who doesn’t?)
3. Compute the test statistic value (TSV) for your sample. That is basically your mean scaled to the size of the sample you have – so that
the larger the sample is, the more certain your are of your inference.
Imagine we would be able to repeat this many times. The TSVs we’ve just computed would form a distribution themselves. Well, the Central Limit Theorem asserts that distribution would be Gaussian (normal).
4. Compute the probability of seeing the test statistic value observed under the null hypothesis (a normal distribution centered and shaped the way null hypothesis predicts it should be). If the TSV falls into a region past a pre-defined p-value, we reject the null hypothesis.
In our case we should only look at one tail of that distribution, we don’t want to catch a case when huskies weight more than 50kg.
Hope this clears it up.
Take a look at https://www.explainxkcd.com/wiki/index.php/882:_Significant
Am I missing a stats joke or was “why polygamy is bad for you” simply a provocative headline? I don’t see it mentioned at all in the post itself
The paper itself is quite critical of two existing data exploration tools: SeeDB and Data Polygamy, and I believe this latter tool is what the title refers too. I chose to focus on the general multiple comparisons problem in my write-up rather than single out specific works.