HackPPL: a universal probabilistic programming language Ai et al., MAPL’19
The Hack programming language, as the authors proudly tell us, is “a dominant web development language across large technology firms with over 100 million lines of production code.” Nail that niche! Does your market get any smaller if we also require those firms to have names starting with ‘F’ ? ;)
In all serious though, Hack powers large chunks of Facebook, running on top of the HipHopVM (HHVM). It started out as an optionally-typed dialect of PHP, but in recent times the Hack development team decided to discontinue PHP support ‘in order open up opportunities for sweeping language advancements’. One of those sweeping advancements is the introduction of support for probabilistic reasoning. This goes under the unfortunate sounding name of ‘HackPPL’. I’m not sure how it should officially be pronounced, but I can tell you that PPL stands for “probabilistic programming language”, not “people”!
This paper is interesting on a couple of levels. Firstly, the mere fact that probabilistic reasoning is becoming prevalent enough for Facebook to want to integrate it into the language, and secondly of course what that actually looks like.
Probabilistic reasoning has become increasingly important in industrial machine learning applications as practitioners seek to obtain higher-fidelity insights from disparate sources of information.
Let’s start with an example use case. “Social media companies1 routinely rely on the annotations provided by reviewers to estimate prevalence, or overall occurrence, of content that violates certain community standards…” But only a fraction of all content can only be reviewed by humans, and even then reviewers may make mistakes. Bayesian approaches are ideally suited to this kind of reasoning under uncertainty. We may not have the true labels for content, but we do have noisy labels from reviewers. We’d like to estimate the true prevalence of each category, the latent category that each piece of content belongs to, and the accuracy of each labeller on different content types.
Throwing you in at the deep end, here’s how that looks in HackPPL:

The annotation model is used to estimate the uncertainty in predicting prevalence by incorporating labeler accuracy. The goal of this model when used in production is to assist with monitoring changes in prevalence over time.
Models
HackPPL models are Hack classes annotated with <>. Generative models are composed by defining random variables using the sample operator.

Models are implemented as coroutines reified as multi-shot continuations. “This choice enables us to accommodate more stateful control flow, such as loops and exception handling, that Hack developers are familiar with.” The <> attribute is just sugar on top of this underlying mechanism so that users can invoke sample and related methods as if they were ordinary Hack functions.
Random variables are represented as tensors for efficient inference in large and complex models. The PyTorch tensor framework is integrated as an extension to the Hack virtual machine, and “as tensors are used widely throughout model writing, we have ongoing efforts to integrate their syntax more seamlessly into Hack.” (Ever wished you’d just gone with typed Python??).
The PyTorch tensors support continuous values, but sampling and conditioning on discrete random variables is also a must-have feature. HackPPL introduces a DTensor (discrete tensor) abstraction for this. The primary feature of a DTensor is efficient conversion to and from one-hot encoded tensors:

A Distribution needs to provide sample and score methods, where sample retrieves i.i.d. samples from the distribution, and score(x) computes the log probability at 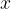
Inference
To support universal modeling, HackPPL adopts a trace-based approach to inference. Traces are proposals for parameter values created from model program executions and each trace is evaluated according to the log probability of parameter values conditioned on observations.
Users configure and run inference using the PPLInfer helper class. The listing below shows an example inference pipeline using Hamiltonian Monte Carlo inference.

The aforementioned coroutine-based implementation facilitates exploring model subcomputations by simple resuming a coroutine multiple times.
HackPPL provides a variety of sampling-based inference methods including Importance-Sampling, Metropolis-Hastings, Sequential Monte-Carlo, and Hamiltonian Monte-Carlo. With a differentiable target distribution, HackPPL uses PyTorch’s reverse-mode automatic differentiation. For discrete variables, HackPPL instead uses the coroutine support to suspend and resume the program multiple times with all possible values in the support of the distribution. For example, in the following program, whenever ‘c’ is sampled the rest of the program will be run n times, where n is the number of categories.

Model assessment
For sampling-based methods, monitoring convergence and diagnosing problems is an essential part of inference. To help with convergence monitoring, we provide standard convergence diagnostics statistics and visualization support in the library…
The HackPPL Playground is an extension to Nuclide (clearly still in use within Facebook, but now officially abandonware in its open source form). It makes it easy for developers to run, debug, and visualize HackPPl model “from within an editor that is already typically used for Hack development.”

The visualisation library is built on top of Plotly. Reactive charts update in realtime as inference progresses.
The last word
HackPPL is now deployed at a large technology firm1 and is being used to solve business problems through deep integrations with critical services.
For the rest of us, a good starting point might be TensorFlow Probability.
Serious question: at this point in time is Hack a competitive advantage for Facebook, or a competitive liability?

Typo: some important text is missing “HackPPL models are Hack classes annotated with <>.” and similarly again later.
Unusual choice of language. Any ideas on advantages compared to just following the herd?
Also, are the masses of Hack programmers at Unnamed Tech Company really going to write this sort of code on a regular basis?
> For some reason, the authors go to great lengths never to use the word Facebook anywhere in the body of the paper.
Perhaps the reason is double-blind reviewing? See: https://pldi19.sigplan.org/home/mapl-2019#evaluation-criteria
I do find it funny what lengths people have to go to hide their affiliations in their papers for this purpose.