SLOG: serializable, low-latency, geo-replicated transactions Ren et al., VLDB’19
SLOG is another research system motivated by the needs of the application developer (aka, user!). Building correct applications is much easier when the system provides strict serializability guarantees.
Strict serializability reduces application code complexity and bugs, since it behaves like a system that is running on a single machine processing transactions sequentially.
The challenge with strict serializability (or even just serializability on a regular DBMS) is that it requires coordination, and as we know, coordination kills performance. Weaker consistency models can give better performance yet “expose applications to potential race condition bugs, and typically require skilled application programmers.” But developers are the kingmakers (I think it’s been enough time now that we can drop the ‘new’ in that phrase?? ;) ), and thus:
… the demand for systems that support strict serializability has only increased.
So starting with strict serializability as a given, how do we claw back some of that performance? That’s where SLOG (Serializable LOw-latency, Geo-replicated transactions) comes in.
SLOG achieves high throughput, strictly serializable ACID transactions at geo-replicated scale for all transactions submitted across the world, all the while achieving low latency for transactions that initiate from a location close to the home region for data they access.
Coordination overhead is bad for performance, but coordination across regions is bad for performance on a whole other level! So the central idea behind SLOG is to take advantage of region affinity — the notion that e.g. data related to a user is likely to accessed in their home region— to handle as many transactions as possible using only intra-region coordination.
Cross-region coordination on every write is not necessary to guarantee strict serializability. If every read of a data item is served from the location of the most recent write to that data item, then there is no need to synchronously replicate writes across regions.
Is my data at home?
Data is replicated across regions, but for every data item one of these regions is designated as its home replica. All writes and linearizable reads of a data item are directed to that replica. Transactions can be single homed (all the data items they access have the same home region), or multi-homed (data items from more than one home region).
Within a region there is a local input log maintained across multiple servers using Paxos. Regions periodically send their log updates to other regions, which enables local snapshots reads in remote (non-home) regions, and faster remastering (re-homing) if a data item needs to be migrated.
If data turns out not to be in the best location, it can be migrated. SLOG borrows PNUTs heuristic for when to remaster data: 3 accesses in a row not from the home region (see §3.4 in the paper for details on how migrations are made safe).
Let’s make a plan
When data for single home transactions is processed within a region, SLOG works similarly to Calvin with data partitioned across servers. Key to good intra-region performance is the deterministic nature of the processing.
All nodes involved in processing a transaction… run an agreement protocol prior to processing a batch of transactions that plans out how to process the batch. This plan is deterministic in the sense that all replicas that see the same plan must have only one possible final state after processing transactions according to this plan. Once all parties agree to the plan, processing occurs (mostly) independently on each node, with the system relying on the plan’s determinism in order to avoid replica divergence.
To make the plan we need to know quite a bit about the transactions within a batch: “this makes deterministic database systems a poor fit for ORM tools and other applications that submit transactions to the database in pieces.” SLOG giveth and SLOG taketh away!
If a transaction that SLOG thought was going to be single-homed turns out not to be (e.g. , data migrated), then that will be detected at runtime, the transaction is aborted, and SLOG restarts it as a multi-home transaction instead.
Are you feeling lucky?
SLOG has two different models of operation: SLOG-B and SLOG-HA. In SLOG-B the only synchronous replication is internally within a home region. If a region fails, data may become unavailable. In SLOG-HA data is synchronously replicated to one or more nearby regions.
Unlike Spanner, Cosmos DB, Aurora, or other previously cited systems that support synchronous cross-region replication, SLOG’s deterministic architecture ensures that its throughput is unaffected by the presence of synchronous cross-region replicas.
Multi-home transactions
The most technically challenging problem in the design of LOG is the execution of multi-home transactions. The goal is to maintain strict serializability guarantees and high throughput in the presence of potentially large numbers of multi-home transactions, even though they may access contended data, and even though they require coordination across physically distant regions.
For single-homed transactions we know we can end up with a global serializable schedule without coordination. But all multi-homed transactions need to be ordered with respect to each other. Any strategy that produces a global ordering would do here (e.g. Paxos) – the current implementation achieves this goal by sending all multi-home transactions to the same region to be ordered by the local log there. (So in the current implementation, SLOG-HA is region fault-tolerant unless the region that dies happens to also be the nominated global ordering region??).
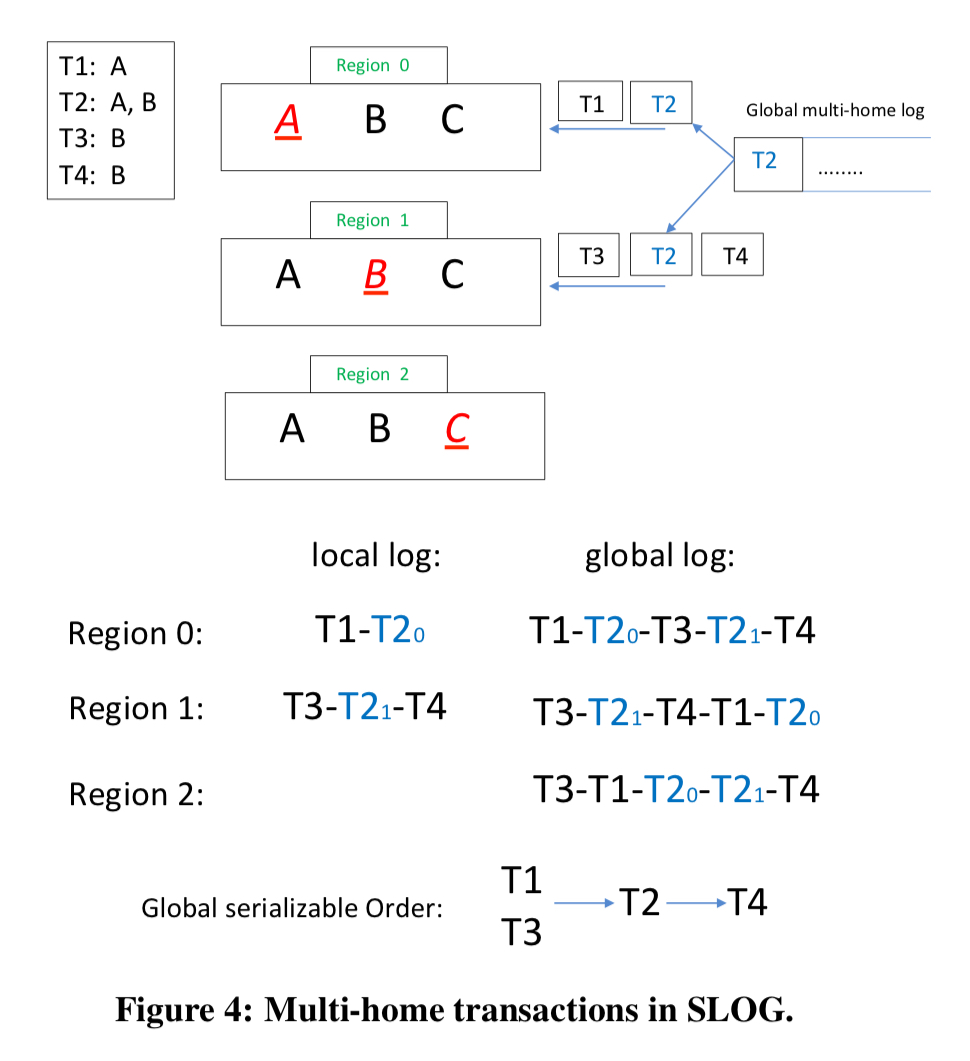
Within each region involved in processing a multi-home transaction, a local LockOnlyTxn is generated which locks the local reads and writes for that region. LockOnlyTxns are placed in the local log like any other transaction, securing an ordering relative to other single-home transactions at the same region.
Evaluation
SLOG is compared to Calvin (a deterministic system, but without the notion of region affinities), to a design based on NuoDB (has region affinities, but is not deterministic, uses 2PL for serializability), and to Cloud Spanner using transactional YCSB and TPC-C NewOrder benchmarks.
Under low contention (mostly single-home transactions) throughput is similar across SLOG, Calvin, and NuoDB-2PL, but as the number of multi-home transactions in the mix increases, Calvin shows an advantage. SLOG pays an extra cost over Calvin for its LockOnlyTxns, but still does better than NuoDB-2PL. However, Calvin’s advantage is reduced somewhat when multi-partition transactions (which could still be single-homed) are in play.
… we expect most workloads to be in one of two categories: either it is mostly single-partition and mostly single-home, or otherwise both multi-partition and multi-home transactions are common.
So hold on a minute, did I bring you all this way just to tell you that Calvin is better?! Not at all! You see, SLOG’s slight disadvantage on multi-home transaction throughput is more than made up for by its latency figures:
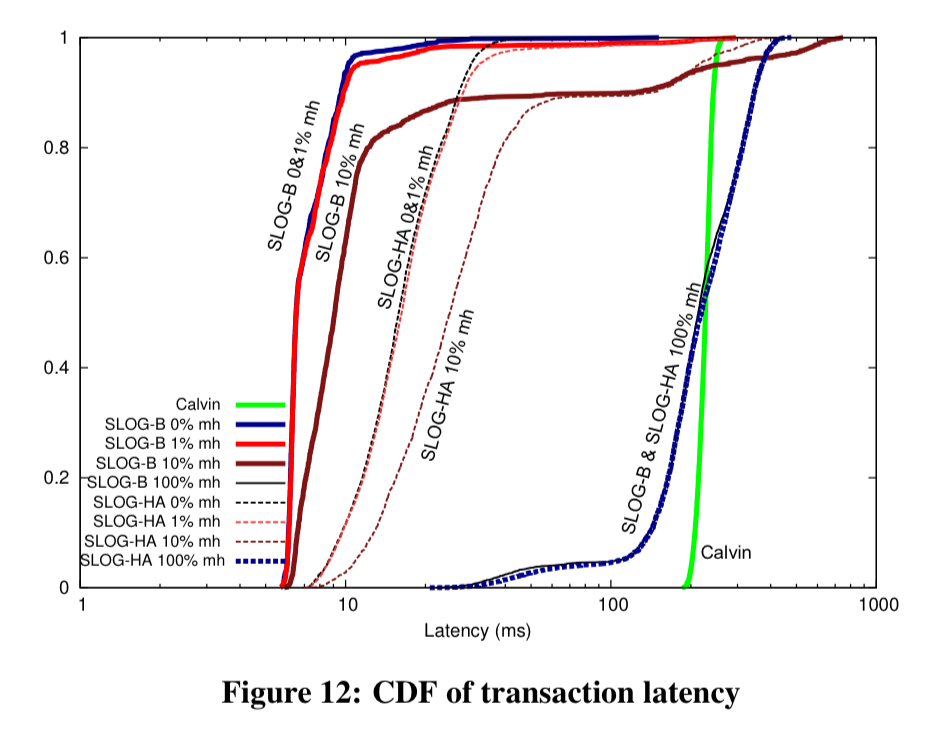
…SLOG’s ability to commit single-home transactions as soon as they are processed at their home region allows SLOG to dramatically reduce its latency relative to Calvin.
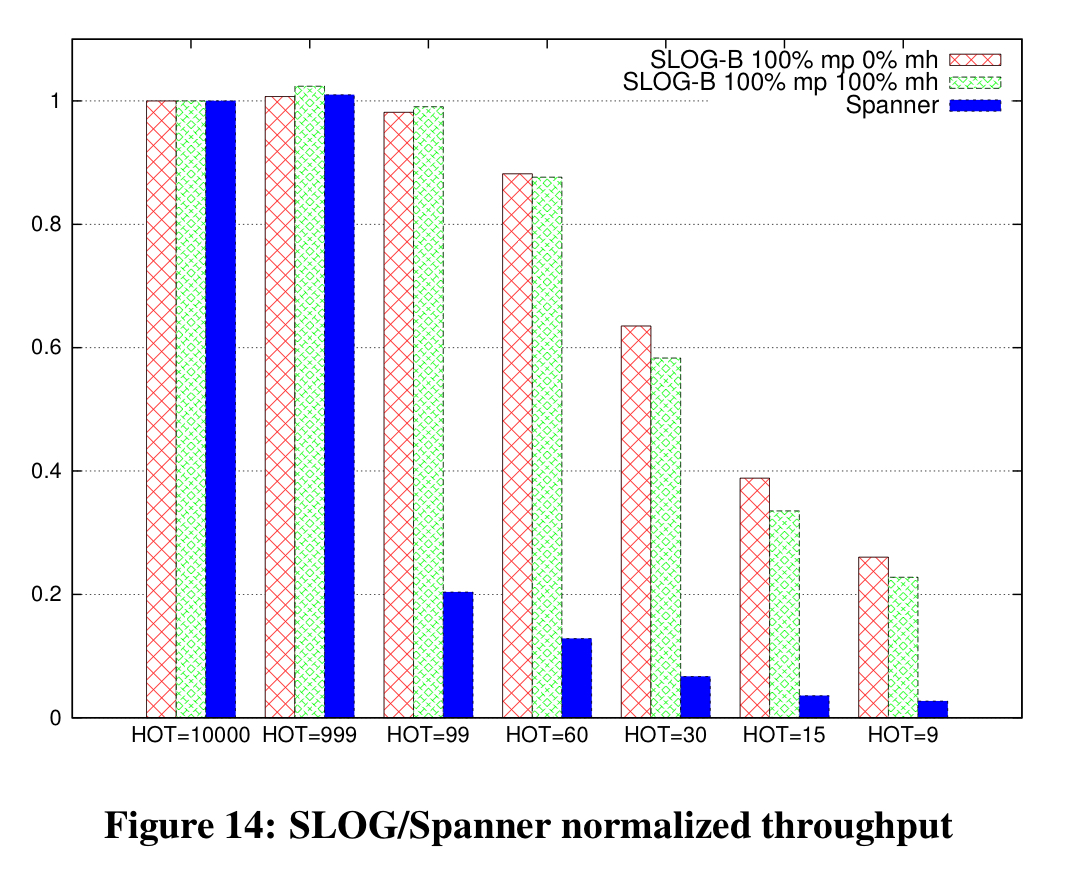
Compared to Spanner, SLOG has a very different performance profile. In particular, Spanner’s throughput decreases rapidly under contention since it doesn’t allow conflicting transactions to run during 2PC and the Paxos-implemented geo-replication.
The last word
Current state-of-the-art geo-replicated systems force their users to give up one of: (1) strict serializability, (2) low-latency writes, (3) high transactional throughput. Some widely used systems force their users to give up two of them… SLOG leverages physical region locality in an application workload in order to achieve all three, while also supporting online consistent dynamic “re-mastering” of data as application patterns change over time.

Am I right in thinking that this looks a lot like VoltDB?