One SQL to rule them all: an efficient and syntactically idiomatic approach to management of streams and tables Begoli et al., SIGMOD’19
In data processing it seems, all roads eventually lead back to SQL! Today’s paper choice is authored by a collection of experts from the Apache Beam, Apache Calcite, and Apache Flink projects, outlining their experiences building SQL interfaces for streaming. The net result is a set of proposed extensions to the SQL standard itself, being worked on under the auspices of the international SQL standardization body.
The thesis of this paper, supported by experience developing large open-source frameworks supporting real-world streaming use cases, is that the SQL language and relational model as-is and with minor non-intrusive extensions, can be very effective for manipulation of streaming data.
Many of the ideas presented here are already implemented by Apache Beam, Calcite, and Flink in some form, as one option amongst several. The streaming SQL interface has been adopted by Alibaba, Hauwei, Lyft, Uber and others, with the following feedback presented to the authors as to why they made this choice:
- Development and adoption costs are significantly lower compared to non-declarative stream processing APIs
- Familiarity with standard SQL eases adoption compared to non-standardized query languages
- Common stream processing tasks such as windowed aggregations and joins can be easily expressed and efficiently executed due to event time semantics
- In case of faulty application logic or service outages, a recorded data stream can be reprocessed by the same query that processes the live data stream.
Foundational principles
The big goal is to unify the abstractions of tables and streams in one common framework:
Combined, tables and streams cover the critical spectrum of business operations ranging from strategic decision making supported by historical data to near- and real-time data used in interactive analysis… We believe, based on our experience and nearly two decades of research on streaming SQL extensions, that using the same SQL semantics in a consistent manner is a productive and elegant way to unify these two modalities of data…
As the authors point out, there has been a lot of prior work in this space over many years, and the proposals presented in this paper draw on much of it. At the sharp end, they are based on lessons learned working an Apache Flink, Beam, and Calcite.
The thing that streaming adds to a traditional relational view is the concept of time. Note that a mutable database table, as perceived by a consumer across multiple queries, is already a time-varying relation (TVR). It’s just that for any one query the results always show the relation at a single point in time.
A time-varying relation is exactly what the name implies: a relationship whose contents may vary over time… The key insight, stated but under-utilized in prior work, is that streams and tables are two representations for one semantic object.
The TVR, by definition, supports the entire suite of relational operators, even in scenarios involving time-varying relational data. So the first part of the proposal is essentially a no-op! We want TVRs, and that’s what relations already are, so let’s just use them – and make it explicit that SQL operates over TVRs as we do so.
We do need some extensions to deal with the notion of event time though. In particular, we need to take care to separate the event time from the processing time (which could be some arbitrary time later). We also need to understand that events will not necessarily be presented for processing in event-time order.
We propose to support event time semantics via two concepts: explicit event timestamps and watermarks. Together, these allow correct event time calculation, such as grouping into intervals (or windows) of event time, to be effectively expressed and carried out without consuming unbounded resources.
The watermarking model used traces its lineage back to Millwheel, Google Cloud Dataflow, and from there to Beam and Flink. For each moment in processing time, the watermark specifies the event timestamp up to which the input is believed to be complete at that point in processing time.
The third piece of the puzzle is to provide some control over how relations are rendered and when rows are materialized. For example: should a query’s output change instantaneously to reflect any new input (normally overkill), or do we just want to see batched updates at the end of a window?
Example
Query 7 from the NEXmark stream querying benchmark monitors the highest price items in an auction. Every ten minutes, it returns the highest bid and associated itemid for the most recent ten minutes.
Here’s what it looks like expressed using the proposed SQL extensions. Rather than give a lengthy prose description of what’s going on, I’ve chosen just to annotate the query itself. Hopefully that’s enough for you to get the gist…

Given the following events
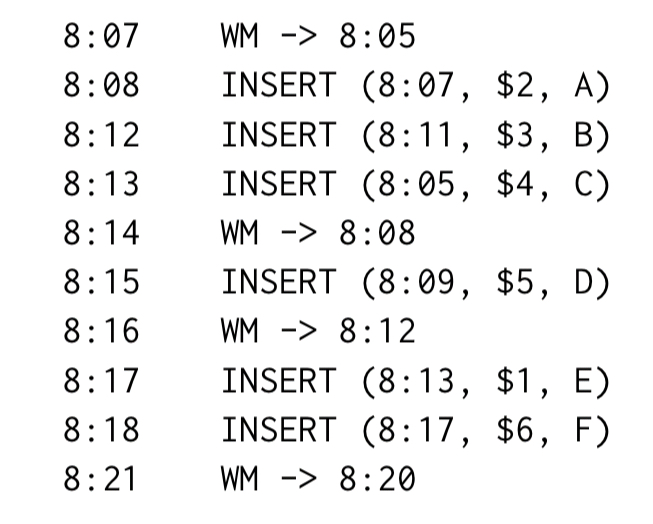
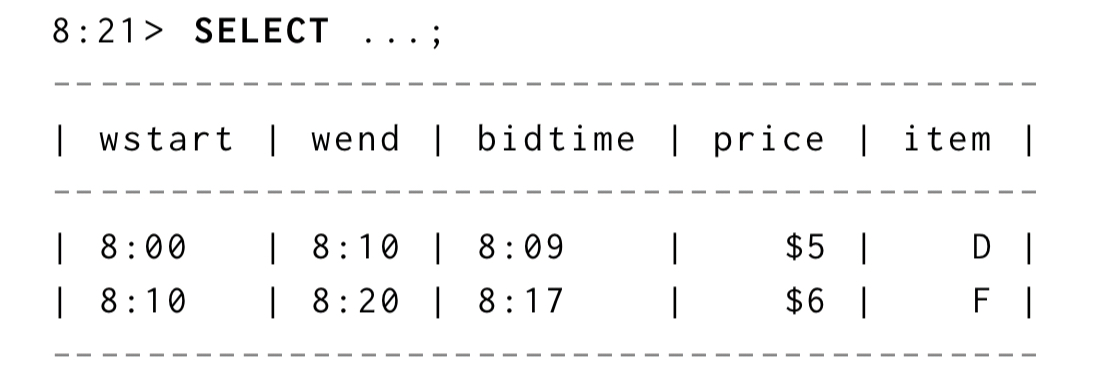
Then a query evaluated at 8:21 would yield the following TVR:
Whereas an evaluation at 8:13 would have looked different:

Note that as currently expressed, the query returns point in time results, but we can use the materialisation delay extensions to change that if we want to. For example, SELECT ... EMIT AFTER WATERMARK; will only emit rows once the watermark has passed the end of the a window.
So at 8:16 we’d see

And at 8:21:
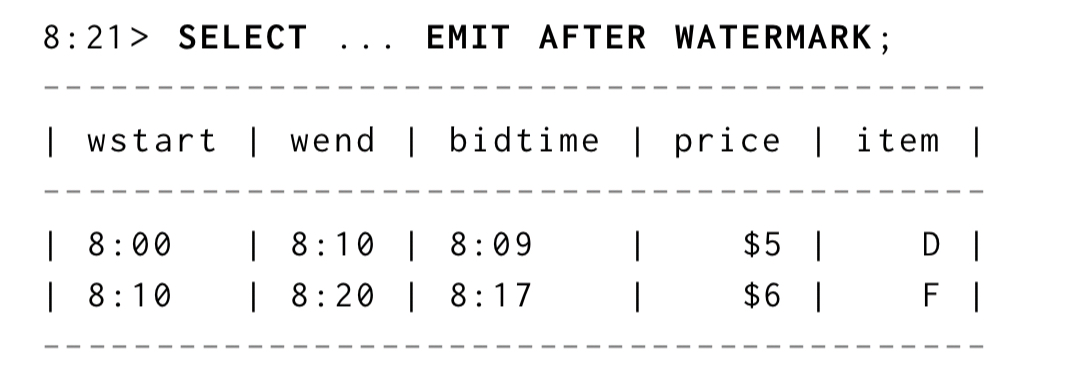
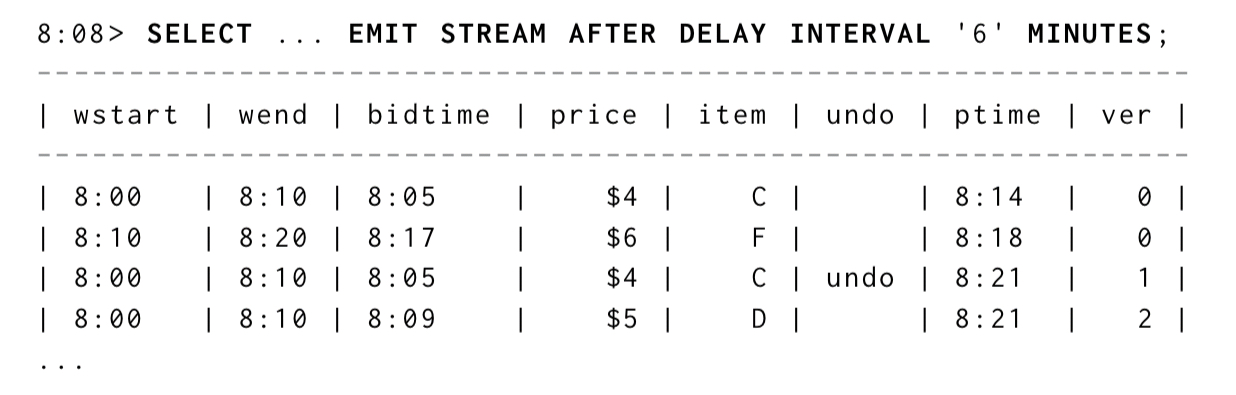
If we want to see rows for windows regardless of watermark, but only get periodic aggregated snapshots we can use SELECT ... EMIT STREAM AFTER DELAY (STREAM here indicates we want streamed results too).
SQL Extensions
Hopefully that’s given you a good flavour. As it stands, the proposal contains 7 extensions to standard SQL:
- Watermarked event time column: an event time column in a relation is a distinguished column of type
TIMESTAMPwith an associated watermark. The watermark is maintained by the system. - Grouping on event timestamps: when a GROUP BY clause groups on an event time column, only groups with a key less than the watermark for the column are included
- Event-time windowing functions: starting with
TumbleandHopwhich take a relation and event time column descriptor and return a relation with additional event-time columns as output. Tumble produces equally spaced disjoint windows, Hop produces equally sized sliding windows. - Stream materialization: EMIT STREAM results in a time-varying relation representing changes to the classic result of the query. Additional columns indicate whether or not the row is a retraction of the previous row, the changelog processing time offset of the row, and a sequence number relative to other changes to the same event time grouping.
- Materialization delay: when a query has an
EMIT AFTER WATERMARKmodifier, only complete rows from the results are materialized - Periodic materialization: when a query has
EMIT AFTER DELAY drows are materialized with period d, instead of continuously. - Combined materialization delay: when a query has
EMIT AFTER DELAY d AND AFTER WATERMARKrows are materialized with period d as well as when complete.
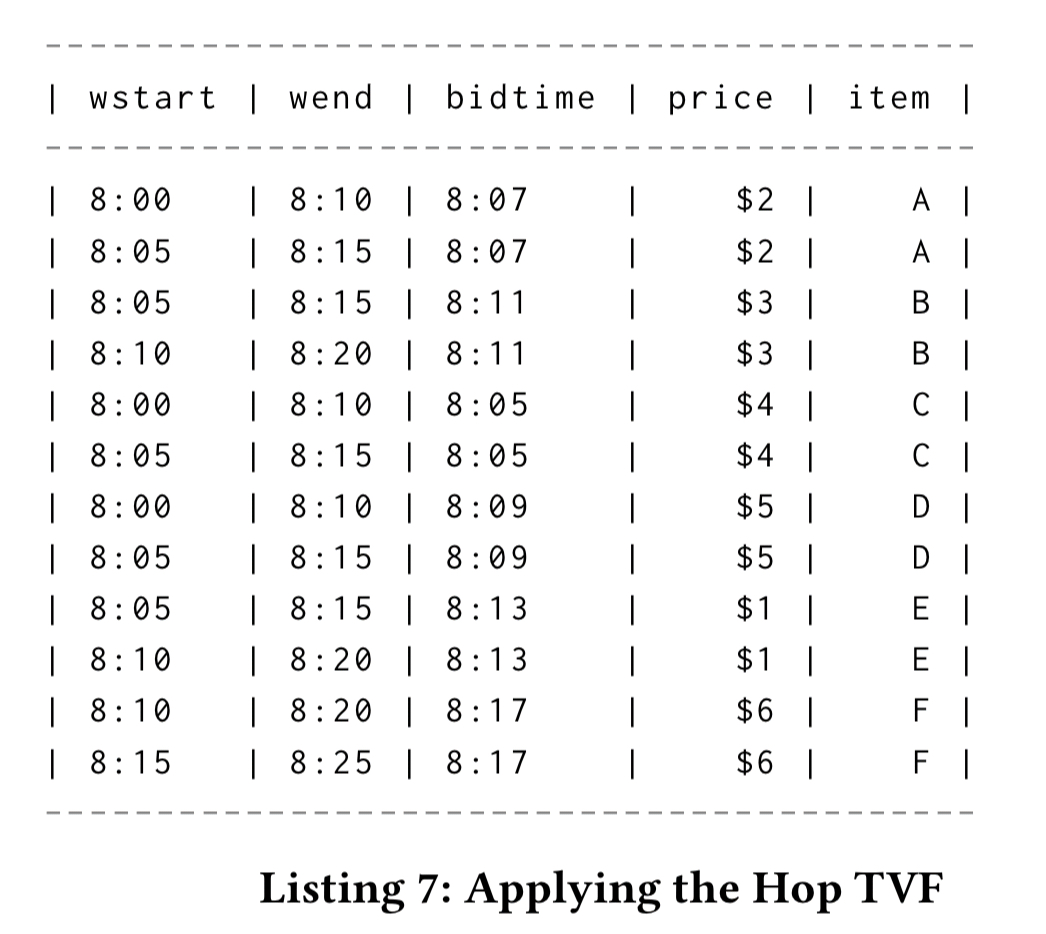
Hop example

Emit Stream example

Lessons learned along the way
Section 5 in the paper contains a list of lessons learned from Apache Calcite, Flink, and Beam that have informed the design. I don’t have the space to cover them all here, but as a flavour here are a couple that caught my eye:
- Because event timestamps are just regular attributes and can be referenced in ordinary expressions, it’s possible that an expression result may not remain aligned with watermarks, which needs to be taken into account during query planning.
- Users find it hard to reason about the optimal use of event time in queries, which can lead to expensive execution plans with undesirable semantics.
Future work
For me, the impressive thing about this work is how much can be achieved with so little. A read through the future work section though (§8) soon shows that the set of extensions is going to need to grow some more before this is done.
As an example, one area that caught my eye was the SQL standard definition that time in SQL queries is fixed at query time (either to the current time, or to a specified fixed time using AS OF SYSTEM TIME). That means you can’t yet express a view over the tail of a stream (you can use an expression such as CURRENT_TIME - INTERVAL ‘1’ HOUR in a predicate, but CURRENT_TIME takes on one fixed value at the time the query is executed). Likewise enriching a TVR with attributes from a temporal table at a specific point in time (e.g. event time) needs additional support.

There’s a small typo:
“which needs to to taken into”
The topic is throwing me back to my masters thesis ten years ago. Back then stream DBs were already becoming less hip, but I found them very cool. I also evaluated different approaches and the SQL extension seemd much more useful.
The system we used back then had the ungoogleable name STREAM (STanford sTReam dAta Manager): http://infolab.stanford.edu/stream/
Fixed, thank you!
From Reddit:
coffeewithalex
> Watermarked
That’s it! I’m out!
I’ve had it with playbooks, recipes, beans, eggs, jars and all of that screwed up jargon that has nothing to do with what’s actually being done!
Plus, the extensions are redundant, when you have window functions and aggregate functions to do exactly this, in an SQL-esque declarative fashion, rather than a functional one that will be hard to implement in a planner.
For example, with the first example of max bid per time window of 5 minutes, you can simply make a function that truncates the time to 5-minute intervals, and group by that value, and compute the end window as that value + 5 minutes. This will be amazingly fast too, and won’t require redefining SQL with new standards.
And if you don’t want to create a function, simply have 3 columns: date_trunc(hour) of that field, and the integer part of minutes/5. Group by these 2 columns and you’re done!
Hop() can be done exactly the same way, but then you’d right join with a full set of time intervals and null values for them, to get a continuous list of events aggregated by time interval.
Because in the end this is basic aggregation.
Nice to see SQL keeps evolving with the streaming architectures :-)