GAN dissection: visualizing and understanding generative adversarial networks Bau et al., arXiv’18
Earlier this week we looked at visualisations to aid understanding and interpretation of RNNs, today’s paper choice gives us a fascinating look at what happens inside a GAN (generative adversarial network). In addition to the paper, the code is available on GitHub and video demonstrations can be found on the project home page.
We’re interested in GANs that generate images.
To a human observer, a well-trained GAN appears to have learned facts about the objects in the image: for example, a door can appear on a building but not on a tree. We wish to understand how a GAN represents such a structure. Do the objects emerge as pure pixel patterns without any explicit representation of objects such as doors and trees, or does the GAN contain internal variables that correspond to the objects that humans perceive? If the GAN does contain variables for doors and trees, do those variables cause the generation of those objects, or do they merely correlate? How are relationships between objects represented?
The basis for the study is three variants of Progressive GANs trained on LSUN scene datasets. To understand what’s going on inside these GANs the authors develop a technique involving a combination of dissection and intervention.
- Given a trained segmentation model (i.e., a model that can map pixels in an image to one of a set of pre-defined object classes), we can dissect the intermediate layers of the GAN to identify the level of agreement between individual units and each object class. The segmentation model used in the paper was trained on the ADE20K scene dataset and can segment an input image into 336 object classes, 29 parts of large objects, and 25 materials.
- Dissection can reveal units that correlate with the appearance of objects of certain classes, but is the relationship causal? Two difference types of intervention help us to understand this better. First, we can ablate those units (switch them off), and see if the correlated objects disappear from an image in which they were previously present. Second, we can force the units on and see if the correlated objects appear in an image in which they were previously absent.
The very first figure in the paper provides an excellent overview. Here we can see (a) a set of generated images of churches; and (b) the results of dissection identify GAN units matching trees. When we ablate those units ( c ) the trees largely disappear, and when we deliberately activate them (d) trees re-appear.

The same insights can be used for human-guided model improvements. Here we see generated images with artefacts (f). If we identify the GAN units that cause those artefacts (e), and ablate them we can remove unwanted artefacts from generated images (g).

Characterising units by dissection
For dissection we take a upsampled and thresholded feature map of a unit and compare it to the segmentation map of a given object class.
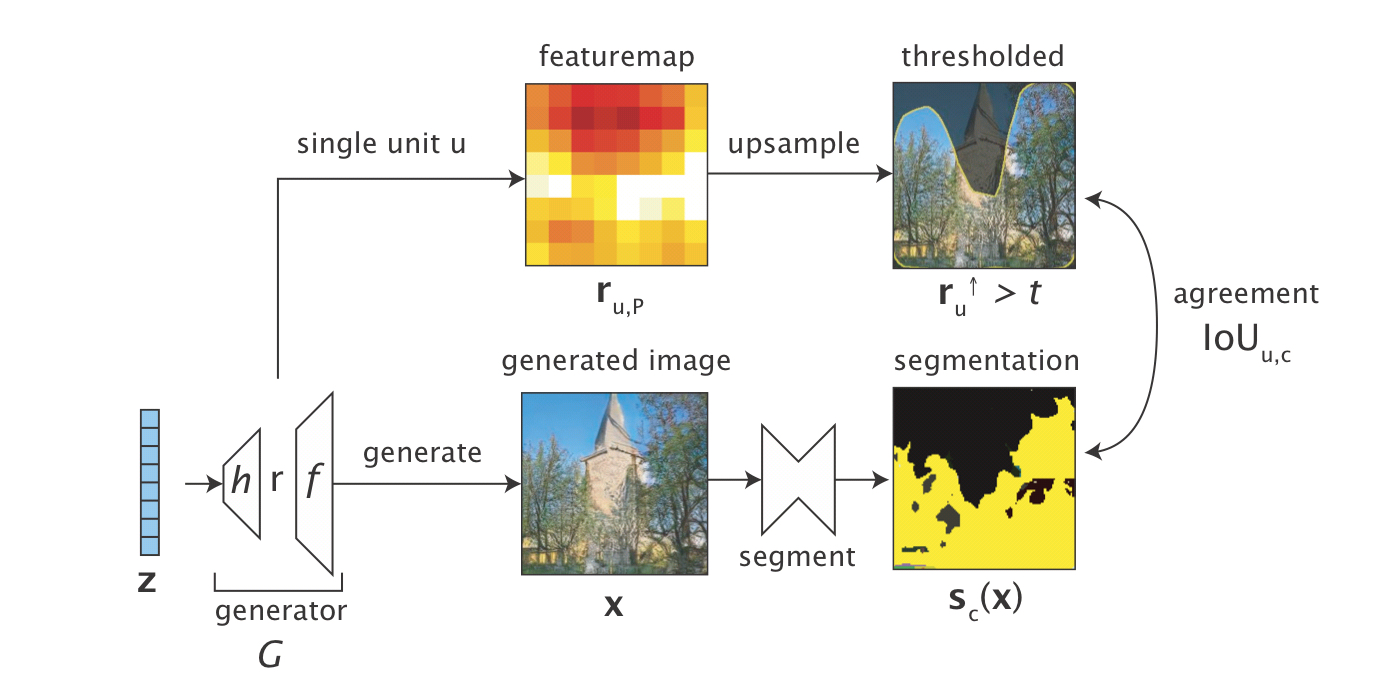
The extent of agreement is captured using an intersection-over-union (IoU) measure. We take the intersection of the thresholded image and the pixels defined as belonging to the segment class, and divide it by their union. The result tells us what fraction of the combined pixels are correlated with the class.
The following examples show units with high IoU scores for the classes ‘table’ and ‘sofa’.

Finding causal relationships through intervention
We can say that a given hidden unit causes the generation of object(s) of a given class if ablating that unit causes the object to disappear, and activating it causes the object to appear. Averaging effects over all locations and images gives us the average causal effect (ACE) of a unit on the generation of a given class.
While these measures can be applied to a single unit, we have found that objects tend to depend on more than one unit. Thus we need to identify a set of units U that maximize the average causal effect for an object class
.
This set is found by optimising an objective that looks for a maximum class difference between images with partial ablation and images with partial insertion, using a parameter than controls the contribution of each unit.
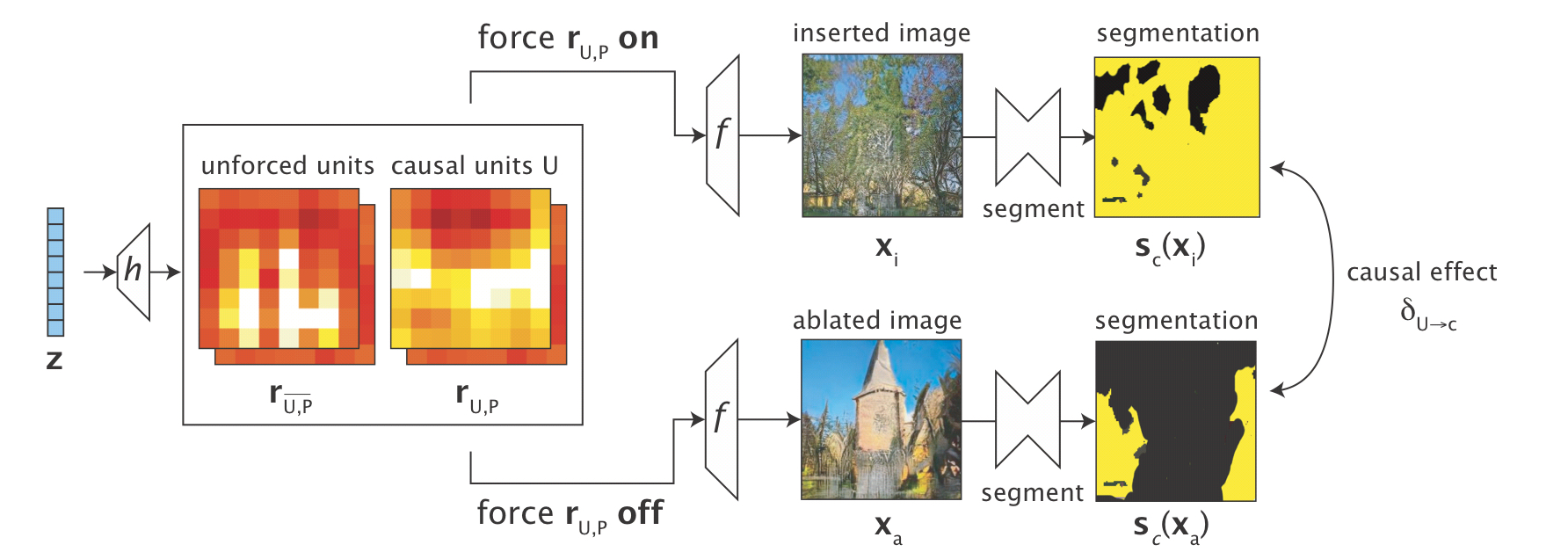
Here you can see the effects of increasing larger sets of hidden units, in this case identified as associated with the class ‘tree’.

Findings from GAN analysis
- Units emerge that correlate with instances of an object class, with diverse visual appearances. The units are learning abstractions.
- The set of all object classes matched by units of a GAN provide a map of what a GAN has learned about the data.
The units that emerge are object classes appropriate to the scene type: for example, when we examine a GAN trained on kitchen scenes, we find units that match stoves, cabinets, and the legs of tall kitchen stools. Another striking phenomenon is that many units represent parts of objects: for example, the conference room GAN contains separate units for the body and head of a person.
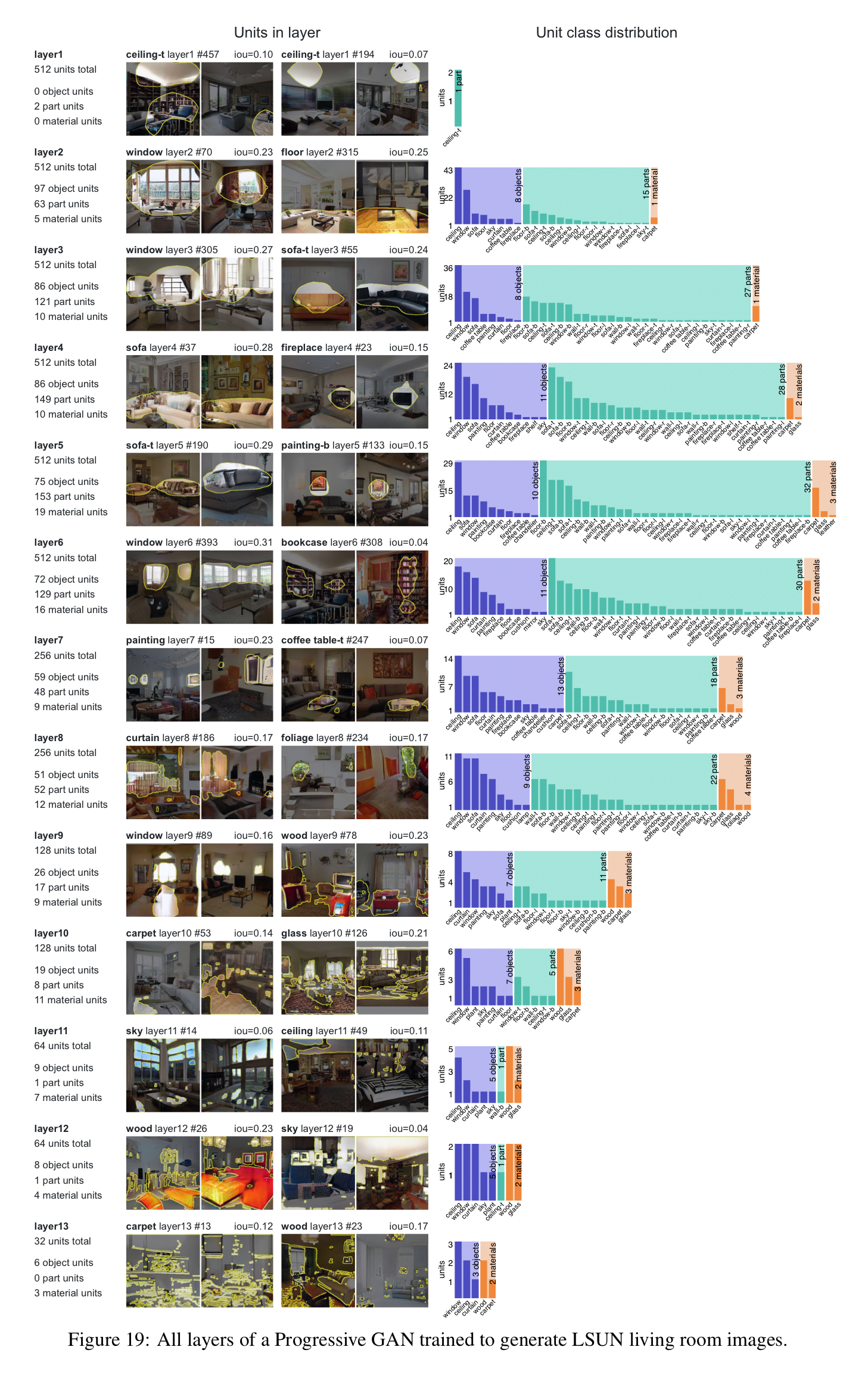
- The type of information represented changes from layer to layer. Early layers remain entangled, middle layers have many units matching semantic objects and object parts, and later layers have units matching pixel patterns such as materials, edges, and colors.
Here’s an interesting layer-by-layer breakdown of a Progressive GAN trained to generate LSUN living room images:
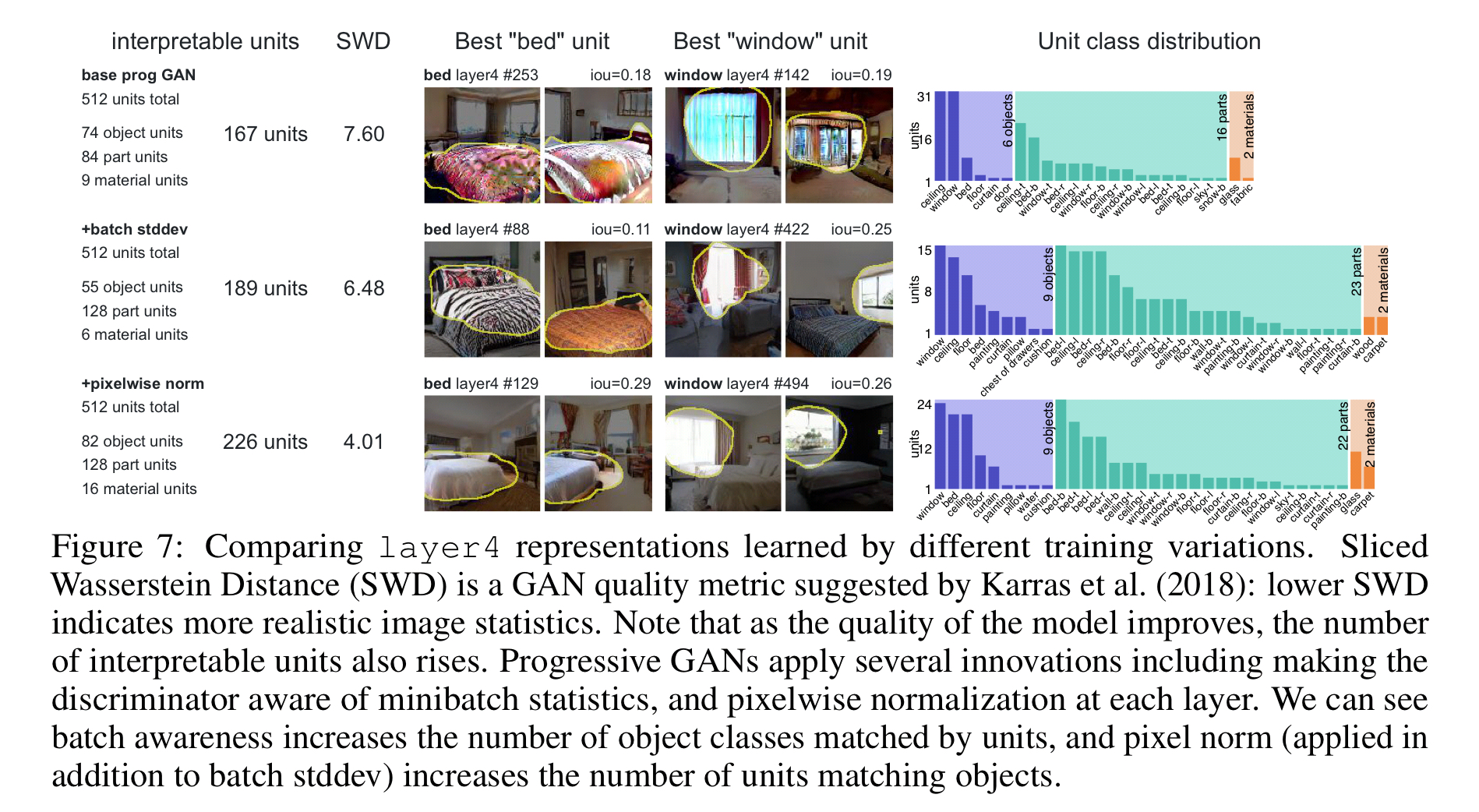
- Compared to a baseline Progressive GAN, adding minibatch stddev statistics increases the realism of the outputs. The unit analysis shows that it also increases the diversity of the concepts represented by units.
- Turning off (ablating) units identified as associated with common object classes causes the corresponding objects to mostly disappear from the generated scenes. Not every object can be erased though. Sometimes the object seems to be integral to the scene. For example, when generating conference rooms the size and density of tables and chairs can be reduced, but they cannot be eliminated entirely.

- By forcing units on we can try to insert objects into scenes. For example, activating the same ‘door units’ across a variety of scenes causes doors to appear – but the actual appearance of the door will vary in accordance with the surrounding scene.
We also observe that doors cannot be added in most locations. The locations where a door can be added are highlighted by a yellow box… it is not possible to trigger a door in the sky or on trees. Interventions provide insight into how a GAN enforces relationships between objects. Even if we try to add a door in layer 4, that choice can be vetoed later if the object is not appropriate for the context.

By carefully examining representation units, we have found many parts of GAN representations can be interpreted, not only as signals that correlate with object concepts but as variables that have a causal effect on the synthesis of objects in the output. These interpretable effects can be used to compare, debug, modify, and reason about a GAN model.
There remain open questions for future work. For example, why can a door not be inserted in the sky? How does the GAN suppress the signal in the later layers? Understanding the relationships between the layers of a GAN is the next hurdle…

Hi Adrian — Long time lurker. Could you enable the RSS/Atom feed on your blog please? It’ll make it possible for my feed aggregator to access your content. Thanks!
You should be able to get the feed by appending /feed/ to the blog url (i.e, https://blog.acolyer.org/feed/). This works for any wordpress.com site afaik