Fixed it for you: protocol repair using lineage graphs Oldenburg et al., CIDR’19
This is a cool paper on a number of levels. Firstly, the main result that catches my eye is that it’s possible to build a distributed systems ‘debugger’ that can suggest protocol-level fixes. E.g. say you have a system that sometimes sends acks before it really should, resulting in the possibility of state loss. Nemo can uncover this and suggest a change to the protocol that removes the window. Secondly, it uses an obscure (from the perspective of most readers of this blog) programming language called Dedalus. Dedalus is a great example of how a different programming paradigm can help us to think about a problem differently and generate new insights and possibilities. (Dedalus is a temporal logic programming language based on datalog). Now, it would be easy for practitioner readers to immediately dismiss the work as not relevant to them given they won’t be coding systems in Dedalus anytime soon. The third thing I want to highlight in this introduction therefore is the research strategy:
Nemo operates on an idealized model in which distributed executions are centrally simulated, record-level provenance of these executions is automatically collected, and computer-readable correctness specifications are available. This was no accident: we wanted to explore the limits of our approach in a “perfect information” scenario.
Once we’ve understood something in an idealised setting, we have the foundation from which we can translate the results into messier ‘real-world’ scenarios:
Generalizing these results to large-scale distributed systems with shallow or non-existent specifications, coarse-grained tracing and logging rather than provenance collection, and a variety of industrial programming languages will require additional research… The generalization of LFDI from the same idealized model to real-world deployments at companies such as Netflix and eBay provides evidence that these problems can be solved.
Errors of commission and omission in distributed systems
Broadly speaking there are two ways we can get things wrong in a distributed system: we can program the intended design incorrectly (an error of commission), or there can be an oversight in the design such that an important case was never considered (an error of omission). Errors of commission are generally easier to track down, because we can compare failing and successful runs and play ‘spot the difference’ (e.g. with differential provenance techniques). Errors of omission are harder to debug.
Here, The problem is not so much a mistake but an oversight: the programmer has insufficiently developed the protocol. Examples include insufficient synchronisation between communicating processes (leaving to race conditions) redundancy (e.g., retry and replication) to ensure availability and durability in the face of faults. State-of-the-art provenance-based debugging is of no help to the programmer here, because there is no offending line of code to point to!
The following Dedalus program (incorrectly) implements a primary/backup replication protocol. It contains an error of omission: in lines 10-13 an ack is sent from the primary to a client immediately upon receipt of a request, rather than once it has been safely replicated. If the primary crashes after the ack but before replication, we’ll lose data.

(Remember, Dedalus is based on datalog, so you read the code ‘inside-out’— at least that’s the way I think about it!— e.g. I read lines 10 and 11 as “when I see a request, then I will asynchronously send an ack…” . The parts in bold are assertions of facts (persistent relations). E.g., when I see an ack, then assert that the request is acked).
Also note here that in our idealised world, we have a correctness specification available to us in the form of pre- and post-conditions (lines 32-38). Whenever something is acked (line 33) then the following facts should all be true… (lines 35-38). You can think of it like a more formal version of BDD if that helps (Given a request is acked, Then, …).
Lineage-driven development and debugging
The central idea of the paper is that provenance graphs (which handily are automatically generated for Dedalus program execution) can be used to debug both errors of commission and omission.
Once again, the database community is in a position to advance the state of the art in distributed systems by dusting of an old database idea: data provenance. We strongly believe the high-level, data–centric explanations of computations obtained via provenance collection to be the right way to debug errors spanning multiple communicating machines.
Provenance-based debugging can begin once we have a failed run and also one or more successful runs to compare it to. To track-down weaknesses (generate failing runs) in the protocol or implementation, you could use an intelligent bug-finder such as Molly. Pairing Molly with Nemo leads to a development loop that looks like this:
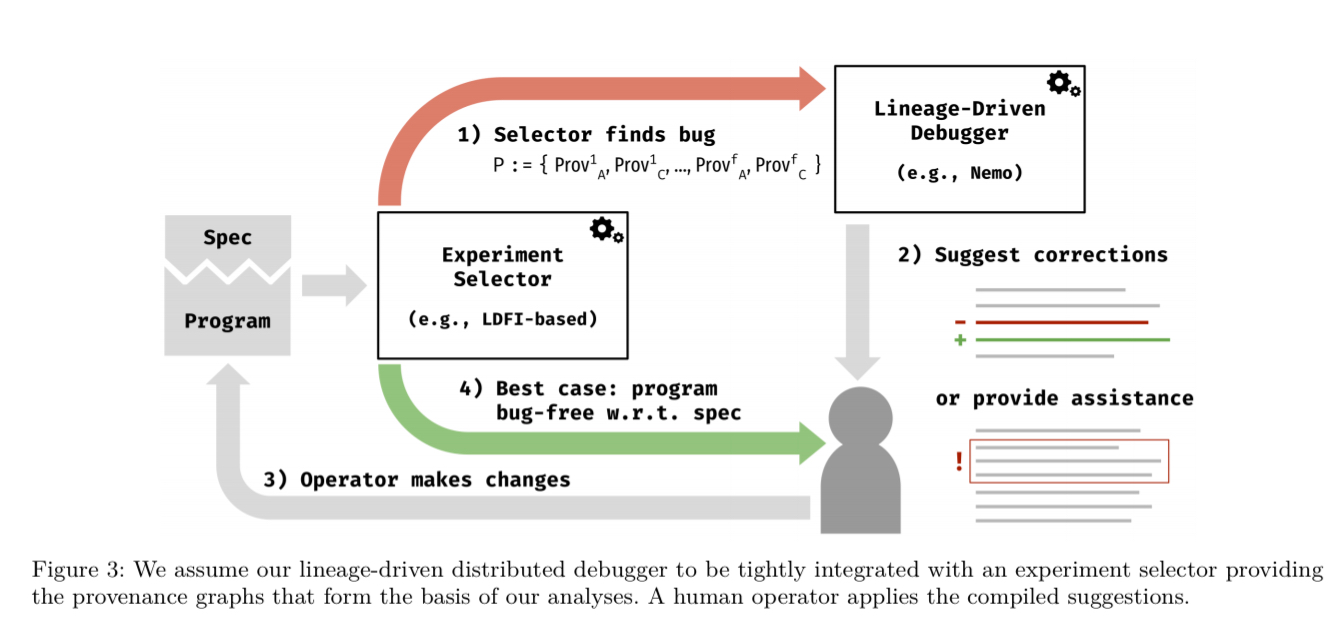
Debugging with differential provenance
The correctness statements are all in the form of implications, 

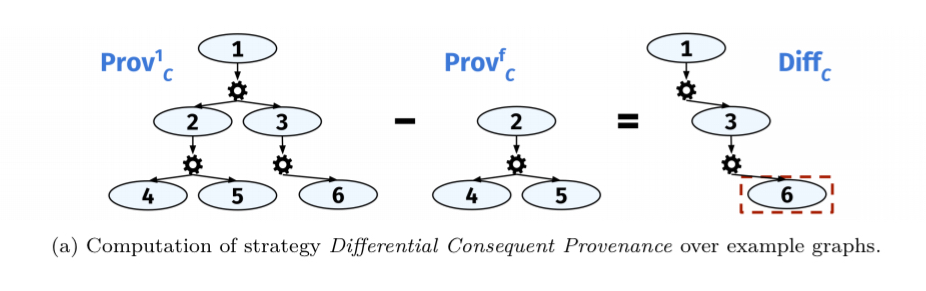
In differential provenance we find a frontier in the provenance graph, a line distinguishing the point at which the failing run departed from the successful path. Given a successful run and a failing run, we can take the difference between their graphs to pinpoint a likely cause. So we examine the provenance of everything leading up to the facts in
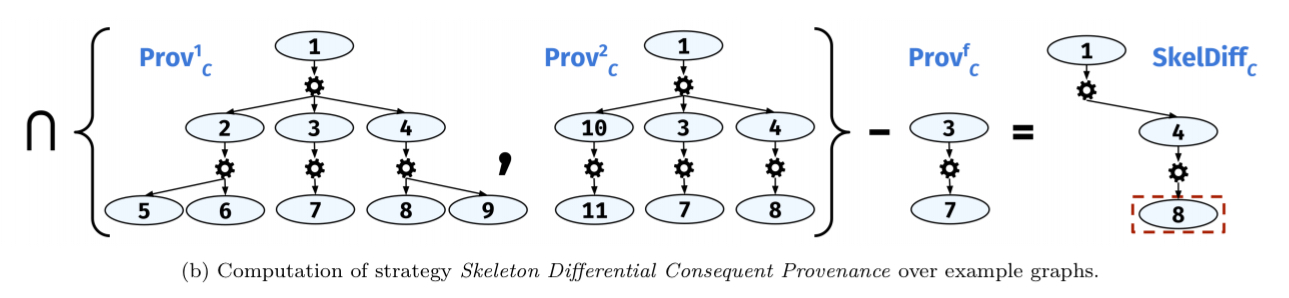
If we have multiple successful runs and a failed run then we can combine the successful runs together to create a skeleton, or prototype, of a successful run by taking the intersection of their provenance graphs. I.e., what is it that all successful runs have in common. (I’m guessing if we had multiple failing runs for the same failure we could also do the same thing there to find out what all instances of a given failure have in common too). Then we can compare the failed run against the success skeleton.
Generating correction suggestions
So far so good, but what about errors of omission? Recall that by construction of the correctness specification when we have a failure we’re in a situation where
One way to rule out the anomalous execution is to ensure that the conditions for establishing
For the example program we were looking at earlier, this would translate into making it harder to send the ack by ensuring all the required conditions were present first.
From a provenance graph perspective we examine the rules leading to the establishment of 
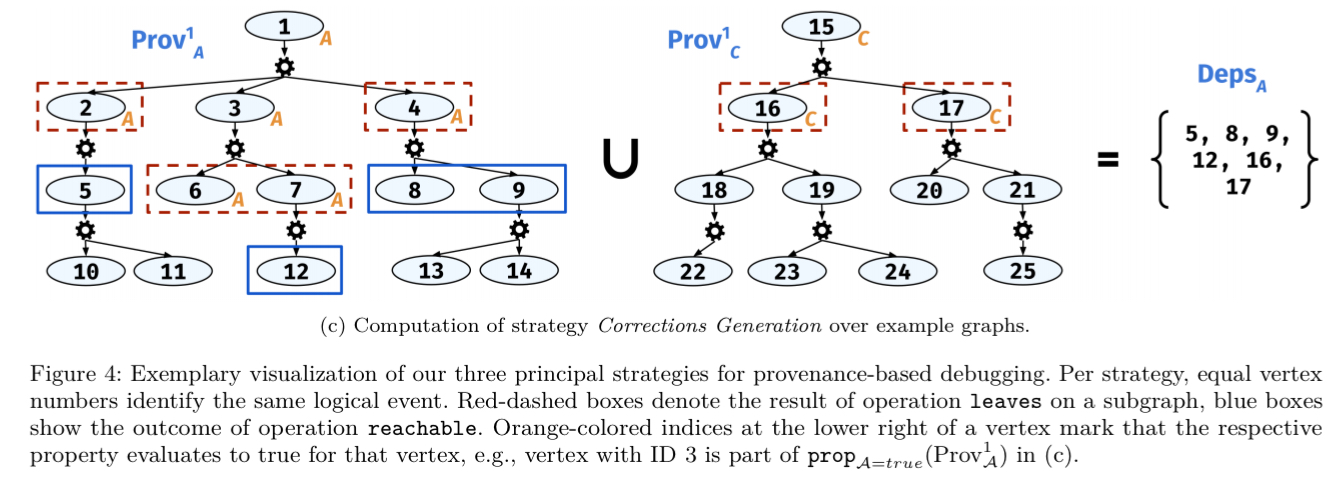
Invoking this strategy, the programmer will be presented with a set of rule suggestions to add, and a set of dependencies to adjust, that, if applied appropriately, close the window between establishment of
Evaluation
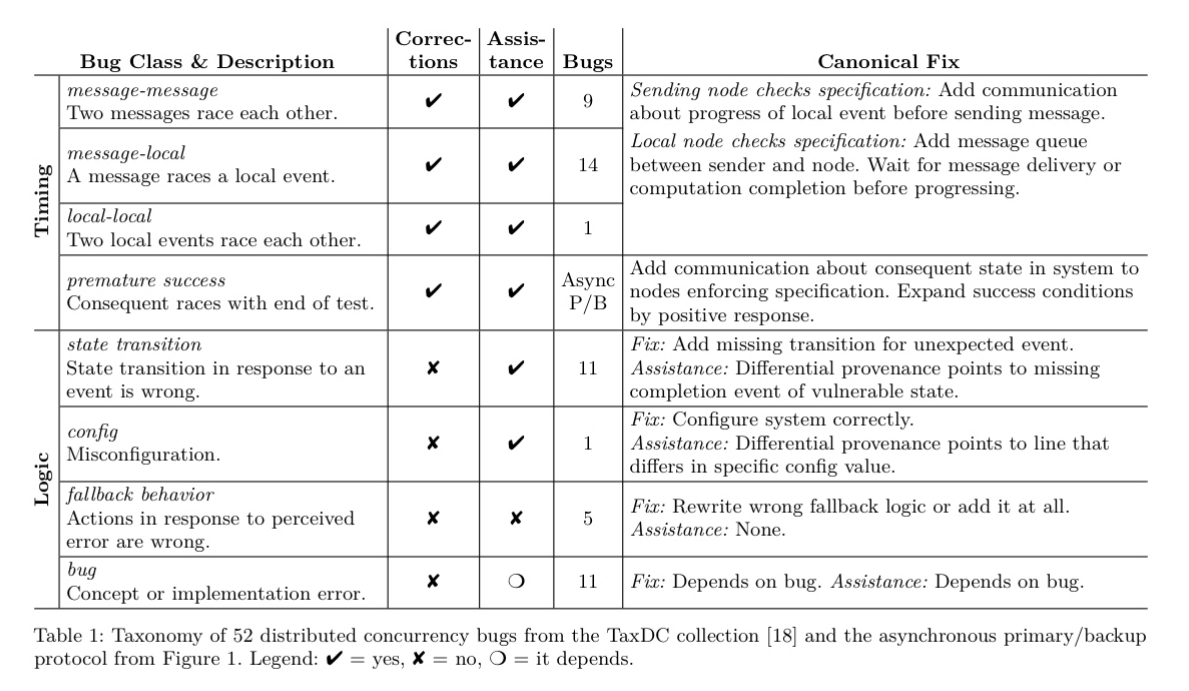
The evaluation uses the TaxDC collection of real-world bugs from large-scale distributed systems. The collection is first filtered to reduce it to bugs that the particular bug finder (Molly) used in the experiments can be expected to find, and then these bugs are classified by root cause. 24 of the 52 bugs are potentially repairable by the corrections generation strategy, the remaining 28 are logic errors (commissions). Of these 12 can receive significant debugging assistance. Only bugs caused by wrong fallback behaviour showed no benefit from provenance-based debugging over conventional methods.
From the set of potentially repairable bugs, Nemo was used to successfully analyse and fix six of them. (My interpretation being no attempt was made on the other 18, as opposed to trying and failing). For example, CA-2083 is a message-message race in Cassandra: a schema message creating a new keyspace and a data message carrying data for that keyspace race to a node. Nemo identifies the race and synthesises a modification of one line of protocol code to enforce the correct ordering of these messages. As a bonus, Nemo also suggested improving the fault-tolerance of some critical network events prone to omissions.
Coming back to the example primary/backup Dedalus program we looked at earlier, Nemo suggests the introduced of an ack_log to inform the client about replica state, with receipt of ack_log from all nodes the condition for success.
Additional fault tolerance analysis suggests to increase the resilience of rules
replicate,request,log, andack, leading to a correct and more robust primary/backup replication protocol that resembles in code what the specification describes as correct.
Turning the provenance framework into a readily available DSL for general-purpose applicability is part of the future work.

the Nemo code is here: https://github.com/numbleroot/nemo
Minor typo – the link to the Molly write up says LFDI instead of LDFI