GraphIt: a high-performance graph DSL Zhang et al., OOPSLA’18
See also: http://graphit-lang.org/.
The problem with finding the optimal algorithm and data structures for a given problem is that so often it depends. This is especially true when it comes to graph algorithms.
It is difficult to implement high-performance graph algorithms. The performance bottlenecks of these algorithms depend not only on the algorithm and the underlying hardware, but also on the size and structure of the graph. As a result, different algorithms running on the same machine, or even the same algorithm running with different types of graph on the same machine, can exhibit different performance bottlenecks.
What we’d like therefore, is some way of expressing a graph algorithm at a high level such that we can map it into different implementations, each applying different optimisations as needed. For bonus points, we could then automate the search within the optimisation space to find the best performing combination for the circumstances at hand.
This is exactly what GraphIt does. GraphIt combines a DSL for specifying graph algorithms with a separate scheduling language that determines implementation policy. You can specify a schedule yourself, or use autotuning to discover optimal schedules for you.
Compared to six state-of-the-art in-memory graph processing frameworks, GraphIt outperforms all of them (by up to 4.8x) in 24 out of 32 experiments in the evaluation. It is never more than 43% slower than the fastest framework across all 32 experiments. At the same time, the algorithms expressed using GraphIt require up to an order of magnitude less code to express.
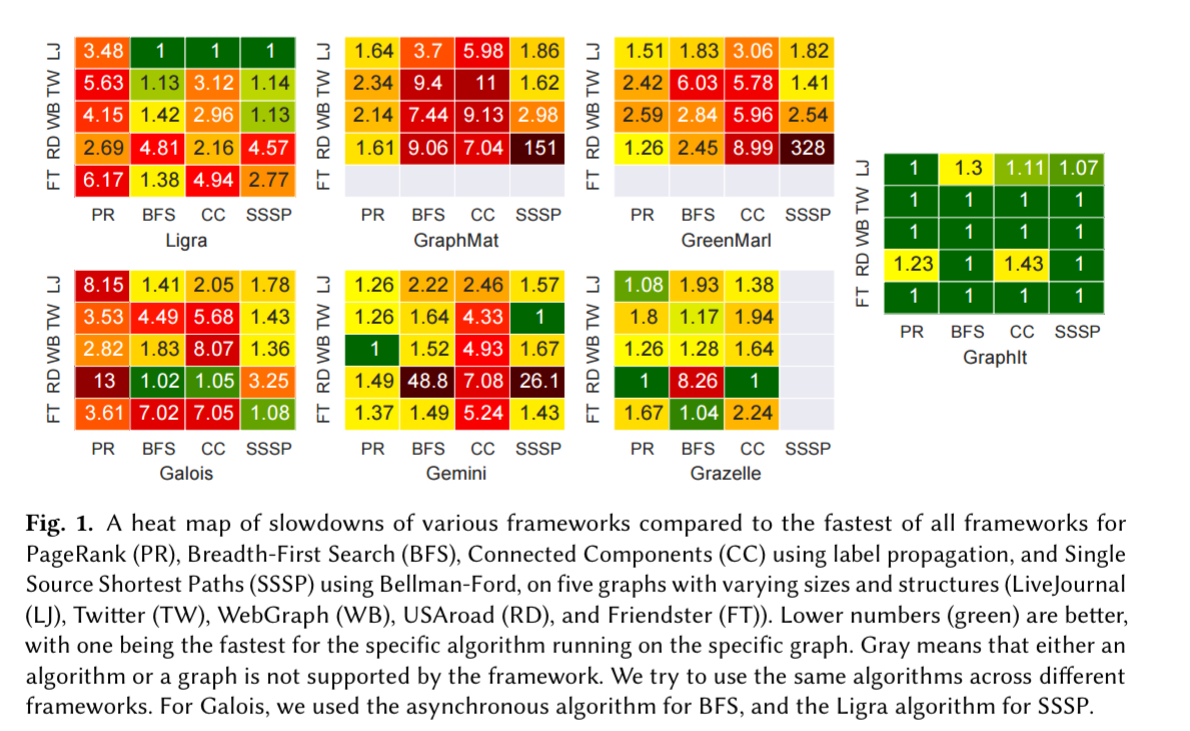
Trade-offs for graph algorithms
We can think about the various possible implementation choices for graph algorithms as making trade-offs in three main dimensions:
- Locality – the amount of spatial and temporal reuse in a program
- Work efficiency – the inverse of the number of instructions (weighted by cycles per instructions) required (i.e., if it takes more instruction cycles, it’s less efficient)
- Parallelism – the amount of work than can be executed independently by different processing units
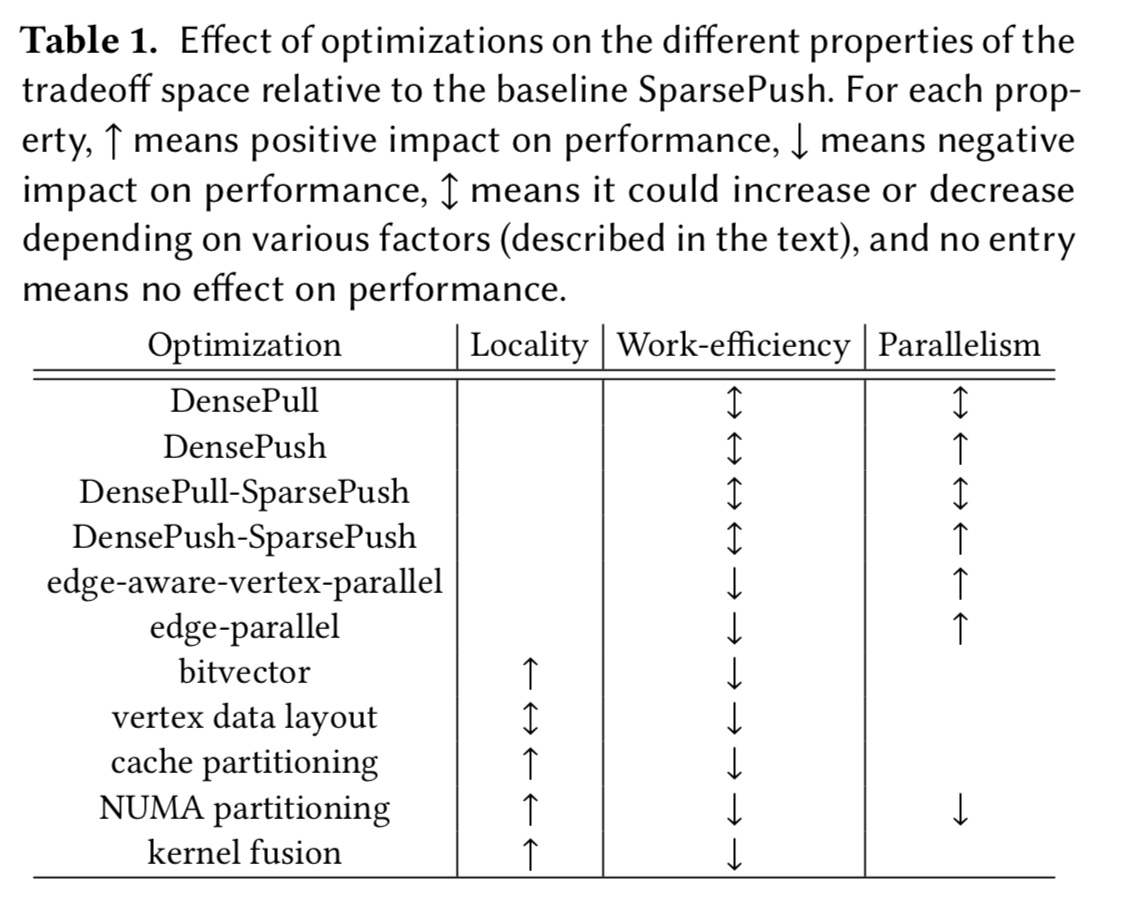
There’s a whole catalog of different possible optimisations that move us within this space. The following table shows their impact compared to a baseline sparse push implementation:
The sparse push baseline (as implemented for the PageRankDelta algorithm) looks like Fig 2 below. On each iteration each vertex on the frontier sends its delta (change in rank value) to its out-neighbours. The set of vertices in the frontier are maintained in a sparse data structure.

- In DensePull we instead have each vertex iterate over its incoming neighbours
- In DensePush we don’t bother maintaining the frontier in a sparse format and instead iterate over all vertices checking each one to see if it’s in the frontier as we go.
- DensePull-SparsePush and DensePush-SparsePush are hybrids that use SparshPush, DensePull, and DensePush in different directions based on the size of the active set.
- For the representation of the frontier itself we can choose between various representations such as bitvectors, boolean arrays, and sparse arrays.
For each of the above traversal modes we have different choices for parallelisation. We can process vertices in parallel (vertex-parallel), or for heavily skewed graphs where the workload of a vertex is proportional to its number of incoming edges we might prefer an edge-aware_vertex_parallel approach instead. Alternatively we could go all in and use an edge-parallel approach.
We can potentially employ cache partitioning, trying to keep random accesses within the last level cache (LLC). Vertices are partitioned into Segmented Subgraphs (SSGs). This improves locality but harms work efficiency due to vertex data replication from graph partitioning and merging of partial results. NUMA partitioning executes multiple SSGs in parallel on different sockets.
Vertex data layout (arrays of structs or structs of arrays) can also affect locality of memory accesses. Consider a random lookup in an array and then accessing two fields from that vertex (arrays of structs) versus two random lookups (structs of arrays). However, the former approach expands the working set size for no benefit if fields are not typically accessed together.
Finally, when two graph kernels have the same traversal pattern we can fuse their traversals (kernel fusion).
That’s a lot of choices, and a fine way of polluting expression of the core algorithm with optimisation details.
The GraphIt DSL for expressing graph algorithms
GraphIt offers a high level DSL for expression algorithms at a level above these concerns. Here’s PageRankDelta in full, including all the setup:

The heart of the matter is expressed in lines 31 through 38. On line 32, the from operator ensures that only edges with a source vertex in the frontier are traversed, and the apply operator acts on the selected edges.
This separation enables the compiler to generate complex code for different traversal modes and parallelization optimizations, while inserting appropriate data access and synchronization instructions for the
updateEdgefunction.
As a comparison, the three core lines of the GraphIt expression require 16 lines of code of Ligra:

The scheduling language
Looking again at the GraphIt DSL version of PageRankDelta, notice the funny #s1# label on line 32. These labels are used to identify statements on which optimisations can apply, and a scheduling language maps these labels to points in the optimisation space.
The scheduling functions allow choices to be made in each of the optimisation areas we looked at earlier:

For example, the following schedule elects to use the “DensePull-SparsePush” traversal and leaves all other configuration options at their default settings:

The following examples show pseudocode for PageRankDelta generated with different schedules.

(Enlarge)
These are just some of the easier examples, throw in NUMA and cache optimisation as well and it can get really hairy!. The total optimisation space is as follows:
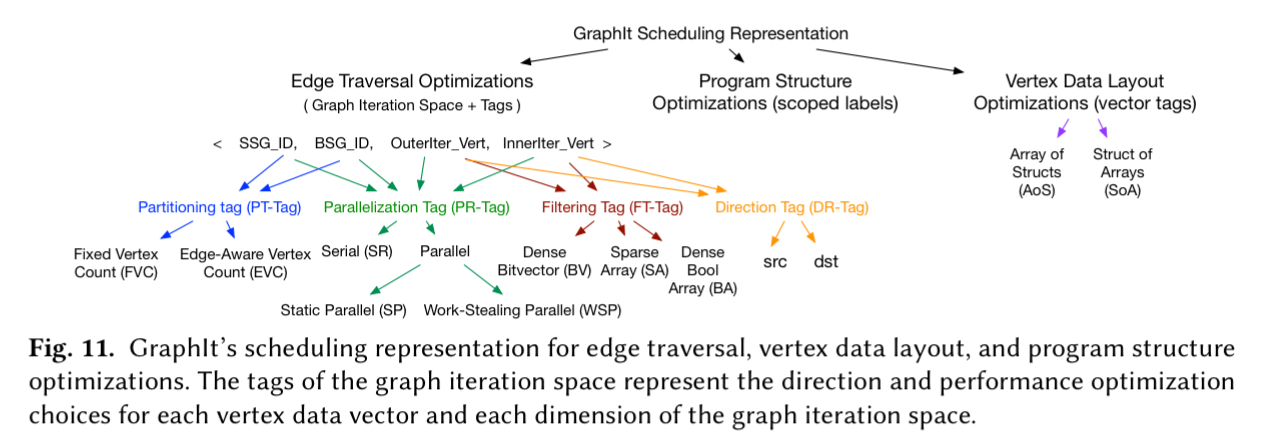
(Enlarge)
Compilation and the graph iteration space
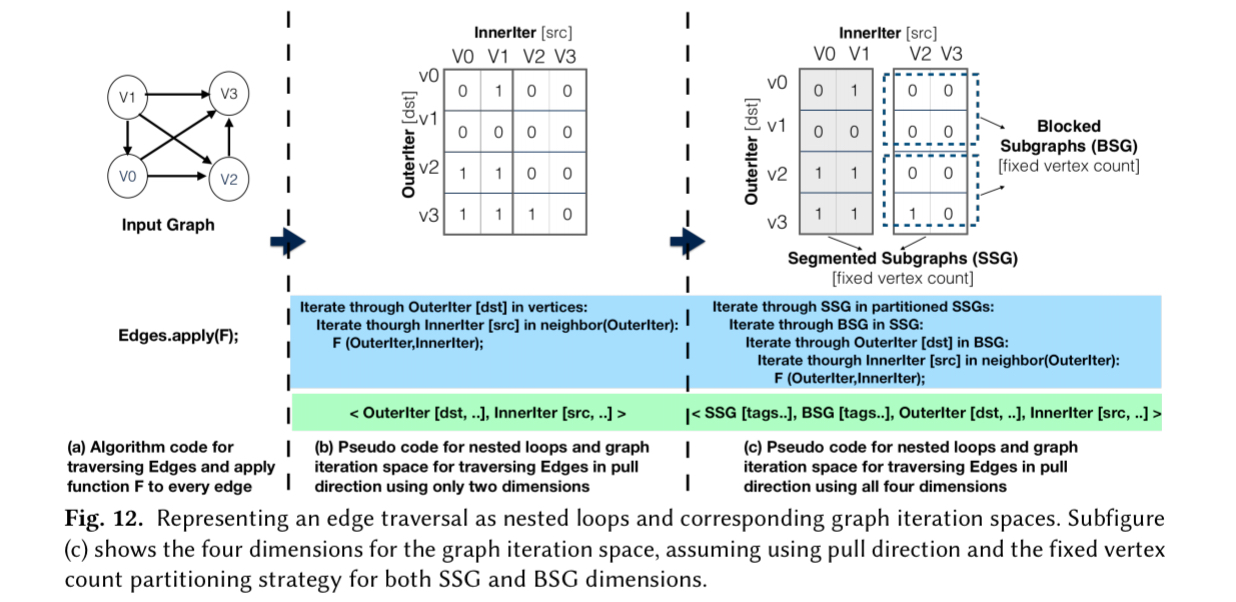
Under the covers, a graph is represented by an adjacency matrix, and the graph iteration space is represented in four dimensions based: the Segmented Subgraph ID (SSG_ID); a Blocked Subgraph ID (BSD_ID); an OuterIter ID indicating column position when iterating over columns and an InnerIter ID indicating row position when iterating over rows.
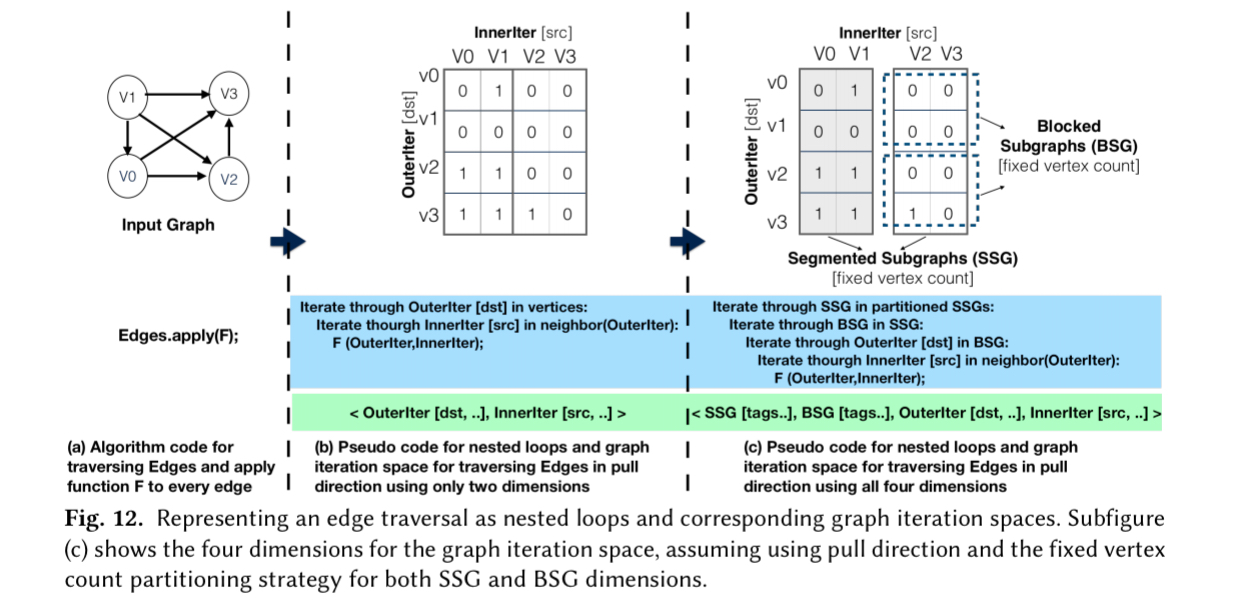
(Enlarge)
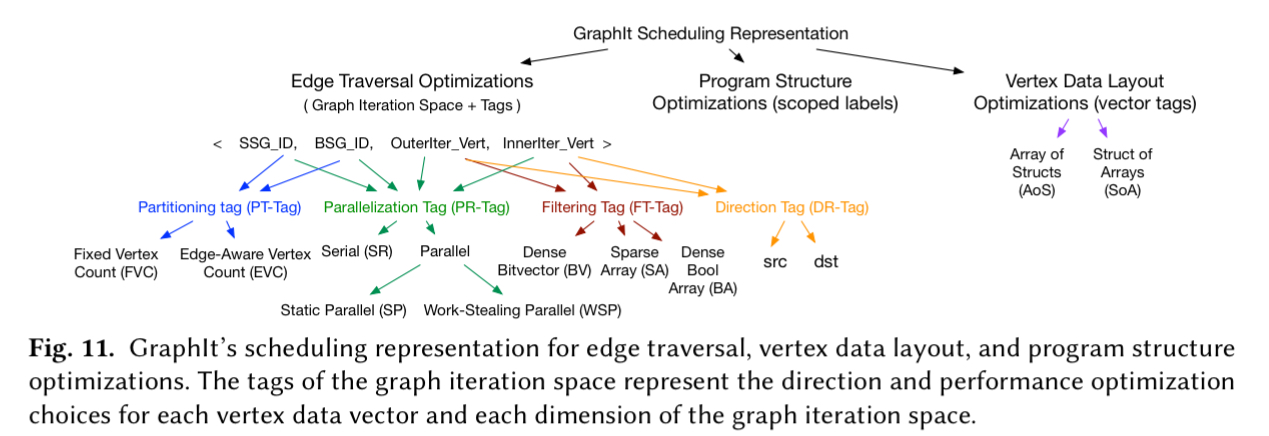
Each of the four dimensions in the graph iteration space is annotated with tags to indicate the traversal direction and optimisation strategies from the schedule. The scheduling language is mapped down to graph iteration space vectors and tags (details in section 5 of the paper), from which the GraphIt compiler generates optimised C++ code (details in section 6.1 – 6.3).
Autotuning
GraphIt can have up to
valid schedules with each run taking more than 30 seconds for our set of applications and input graphs. Exhaustive searches would require weeks of time. As a result, we use OpenTuner to build an autotuner on top of GraphIt that leverages stochastic search techniques to find high-performance schedules within a reasonable amount of time.
Evaluation
GraphIt is compared against six different state-of-the-art in-memory graph processing frameworks on a dual socket system with 12 cores each and 128GB of memory. The input datasets used for the evaluation are shown in the following table.
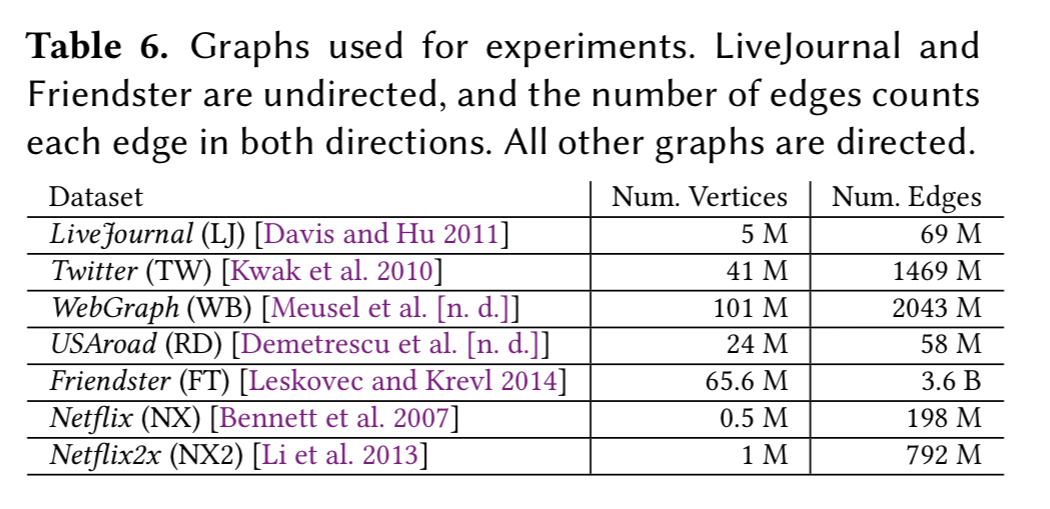
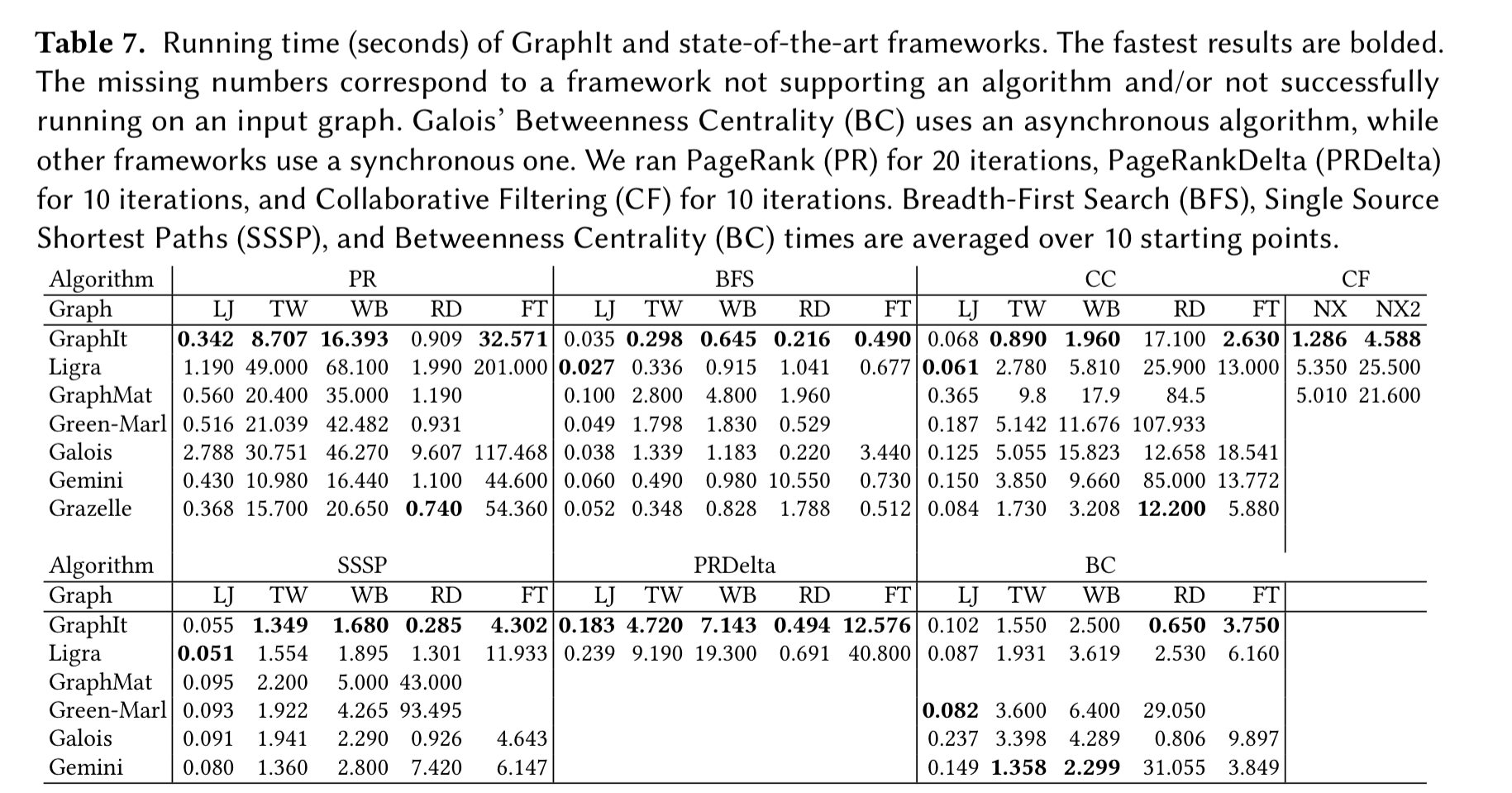
Here are the execution times for GraphIt versus the other systems across a variety of algorithms over these datasets:
And here is a line-of-code comparison for expressing those algorithms:


{kind=link}
{kind=link}
{kind=link}
5 thoughts on “GraphIt: A high-performance graph DSL”
Comments are closed.